

Genetic diversity of the 28-kilodalton outer membrane protein gene in human isolates of Ehrlichia chaffeensis
- PMID: 10074538
- PMCID: PMC88661
- DOI: 10.1128/JCM.37.4.1137-1143.1999
Genetic diversity of the 28-kilodalton outer membrane protein gene in human isolates of Ehrlichia chaffeensis
Abstract
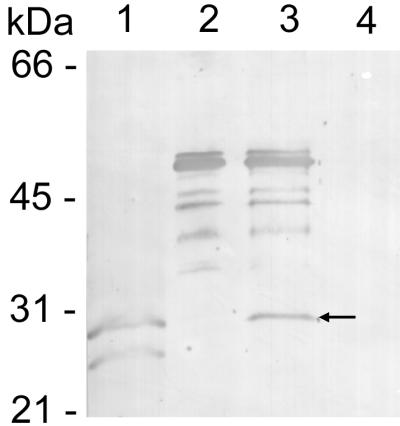
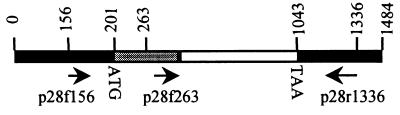
The Ehrlichia chaffeensis 28-kDa outer membrane protein (p28) gene was sequenced completely by genomic walking with adapter PCR. The DNA sequence of the p28 gene was nearly identical to the previously reported sequence (N. Ohashi, N. Zhi, Y. Zhang, and Y. Rikihisa, Infect. Immun. 66:132-139, 1998), but analysis of a further 75 bp on the 5' end of the gene revealed DNA that encoded a 25-amino-acid signal sequence. The leader sequence was removed from the N terminus of a 30-kDa precursor to generate the mature p28 protein. A monoclonal antibody (MAb), 1A9, recognizing four outer membrane proteins of E. chaffeensis (Arkansas strain) including the 25-, 26-, 27-, and 29-kDa proteins (X.-J. Yu, P. Brouqui, J. S. Dumler, and D. Raoult, J. Clin. Microbiol. 31:3284-3288, 1993) reacted with the recombinant p28 protein. This result indicated that the four proteins recognized by MAb 1A9 were encoded by the multiple genes of the 28-kDa protein family. DNA sequence alignment analysis revealed divergence of p28 among all five human isolates of E. chaffeensis. The E. chaffeensis strains could be divided into three genetic groups on the basis of the p28 gene. The first group consisted of the Sapulpa and St. Vincent strains. They had predicted amino acid sequences identical to each other. The second group contained strain 91HE17 and strain Jax, which only showed 0.4% divergence from each other. The third group contained the Arkansas strain only. The amino acid sequences of p28 differed by 11% between the first two groups, by 13.3% between the first and third groups, and by 13.1% between the second and third groups. The presence of antigenic variants of p28 among the strains of E. chaffeensis and the presence of multiple copies of heterogeneous genes suggest a possible mechanism by which E. chaffeensis might evade the host immune defenses. Whether or not immunization with the p28 of one strain of E. chaffeensis would confer cross-protection against other strains needs to be investigated.
Figures


References
-
- Anderson B E, Sims K G, Olson J G, Childs J E, Piesman J F, Happ C M, Maupin G O, Johnson B J. Amblyomma americanum: a potential vector of human ehrlichiosis. Am J Trop Med Hyg. 1993;49:239–244. - PubMed
-
- Chen S M, Dumler J S, Feng H M, Walker D H. Identification of the antigenic constituents of Ehrlichia chaffeensis. Am J Trop Med Hyg. 1994;50:52–58. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
