

doi: 10.1073/pnas.96.22.12224.
Bridging the gap: a family of novel DNA polymerases that replicate faulty DNA
- PMID: 10535901
- PMCID: PMC34254
- DOI: 10.1073/pnas.96.22.12224
Item in Clipboard
Bridging the gap: a family of novel DNA polymerases that replicate faulty DNA
Proc Natl Acad Sci U S A.
.
No abstract available
Figures
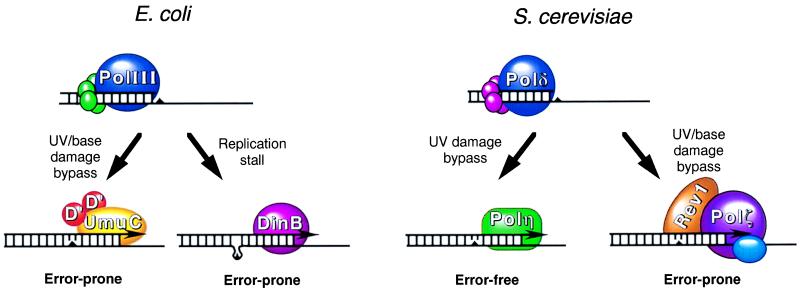
Modes of bypass replication in E. coli and
S. cerevisiae. As DNA replication proceeds, the
replicative DNA polymerases, PolIII in E. coli or Polδ
in S. cerevisiae, encounter lesions or stall sites
(triangles) in DNA. In E. coli, the DNA polymerase
activity of the UmuD′2C complex carries out limited DNA
synthesis across and past the lesion in an error-prone manner. At
replicative pause sites, such as at a misaligned template-primer
junction, the DinB protein could carry out limited synthesis, resulting
in −1 frameshifts. In S. cerevisiae, the
RAD30-encoded Polη performs replicative bypass of
thymine dimers in an error-free manner by the insertion of two adenines
across from the dimer. Alternatively, the Rev1 protein together with
the REV3/REV7-encoded Polζ carries out replicative
bypass of UV lesions and other base damages in an error-prone manner.
In humans, defects in Polη in XP-V patients result in the loss of
this error-free component of UV damage bypass. Elevated mutagenesis
arising from increased bypass by Polζ would be the underlying cause
of high cancer incidence in XP-V patients.
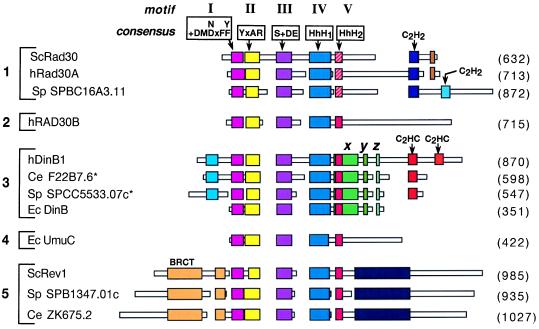
Schematic alignment of DinB/UmuC/Rad30 family proteins. Boxes
represent amino acid sequences of the proteins. Regions of homology are
indicated by colored larger boxes, whereas unique sequences are shown
as narrow white boxes. Areas without boxes indicate gaps introduced for
optimal alignment. Motifs I-III are shown with their respective
consensus sequences where x indicates any amino acid and + indicates a
hydrophobic residue (I, L, or V). Motifs IV and V represent the
helix–hairpin–helix (HhH) domains. The HhH2 sequence in
the hRad30A family, indicated in hatched red, differs from the
analogous sequence present in the other proteins, indicated in solid
red. The DinB-specific sequences are indicated by x,
y and z. Zinc binding motifs are
indicated as C2H2 or C2HC. Numbers
in parentheses indicate protein length in amino acids. Sc, S.
cerevisiae; SP, S. pombe;
h, human; Ec, E. coli; Ce, C.
elegans; BRCT, BRCA1 C-terminal domain. The asterisks on Ce
F22B7.6 and Sp SPCC5533.07C indicate that these protein sequences were
derived from the alternate predicted mRNA splice sites in the 3′
regions of these genes that would produce a longer protein. Alignments
were generated by using the macaw and clustal w
programs.
Comment on
-
Human and mouse homologs of Escherichia coli DinB (DNA polymerase IV), members of the UmuC/DinB superfamily.Proc Natl Acad Sci U S A. 1999 Oct 12;96(21):11922-7. doi: 10.1073/pnas.96.21.11922. Proc Natl Acad Sci U S A. 1999. PMID: 10518552 Free PMC article.
References
-
- Rupp W D, Wilde C E I, Reno D L, Howard-Flanders P. J Mol Biol. 1971;61:25–44. - PubMed
-
- Higgins N P, Kato K, Strauss B. J Mol Biol. 1976;101:417–425. - PubMed
-
- Friedberg E C, Walker G C, Siede W. DNA Repair and Mutagenesis. Washington, DC: Am. Soc. Microbiol. Press; 1995.
-
- Nelson J R, Lawrence C W, Hinkle D C. Nature (London) 1996;382:729–731. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
