

doi: 10.1093/nar/28.1.228.
Increased coverage of protein families with the blocks database servers
Affiliations
- PMID: 10592233
- PMCID: PMC102407
- DOI: 10.1093/nar/28.1.228
Item in Clipboard
Increased coverage of protein families with the blocks database servers
Nucleic Acids Res.
.
Abstract
The Blocks Database WWW (http://blocks.fhcrc.org ) and Email (blocks@blocks.fhcrc.org ) servers provide tools to search DNA and protein queries against the Blocks+ Database of multiple alignments, which represent conserved protein regions. Blocks+ nearly doubles the number of protein families included in the database by adding families from the Pfam-A, ProDom and Domo databases to those from PROSITE and PRINTS. Other new features include improved Block Searcher statistics, searching with NCBI's IMPALA program and 3D display of blocks on PDB structures.
Figures
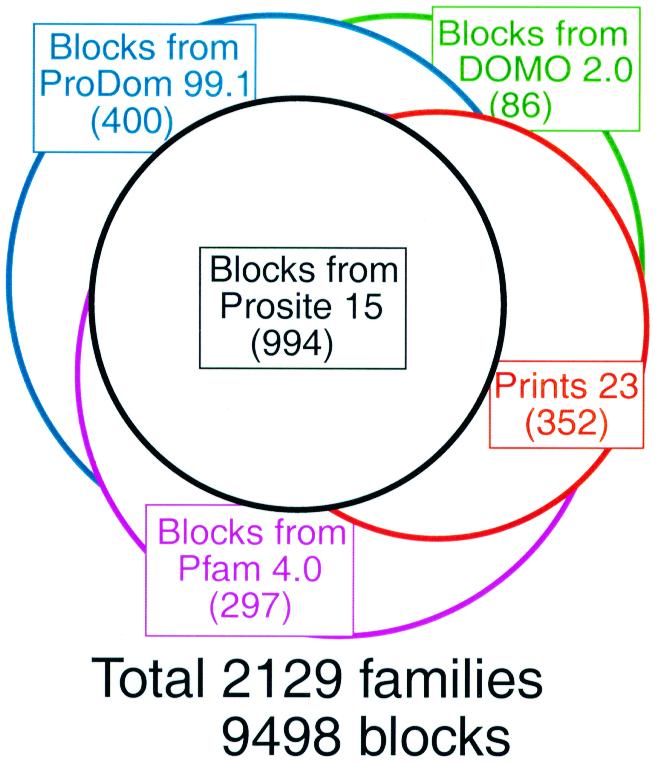
Composition of the Blocks+ Database (as of 15 June 1999).

Block Searcher and IMPALA search outputs. A hypothetical Arabidopsis thaliana protein sequence translated from predicted exons in GenBank/EMBL entry U53501 was used to query Blocks+ with a cutoff expected value of 5. Known true positive hits for this query sequence are BL00094 (cytosine DNA methyltransferases) and BL00598 (chromodomains), which are the top two hits for both Block Searcher and IMPALA Searcher. Notice that none of the other hits reported are the same for both methods. Alignments are shown for the top two hits. (a) Block Searcher output. BL00094E and BL00094F were not detected because they are missing from the query as a result of erroneous gene prediction from U53501, confirmed by direct cDNA analysis (21). Each hit consists of one or more blocks from a protein group found in the query sequence. One set of the highest-scoring blocks that are in the correct order and separated by distances comparable to the Blocks Database is selected for analysis. If this set includes multiple blocks the probability that the lower scoring blocks support the highest scoring block is reported. Maps of the database blocks and query sequence are shown: ‘AAA’ represents a block roughly in proportion to its width. ‘:’ represents the minimum distance between blocks in the database. ‘.’ represents the maximum distance between blocks in the database. ‘< >’ indicate the sequence has been truncated to fit the page. The query map is aligned on the highest scoring block. Multiple block hits that are consistent with the highest scoring block are separated by colons. The alignment of the query sequence with the sequence closest to it in the Blocks Database is shown. The distance between detected blocks is listed as (min, max): for the database entry followed by the distance in the query. Upper case in the query indicates at least one occurrence of the residue in that column of the block. (b) IMPALA Searcher output. The IMPALA alignment detects the region corresponding to BL00094A in the query sequence as a separate high scoring segment, which lies 163 aa upstream of BL00094B. The query sequence is aligned with the COBBLER sequence used to make the PSI-BLAST PSSM. In the two alignments shown no gaps have been inserted within the block regions.

Block Searcher and IMPALA search outputs. A hypothetical Arabidopsis thaliana protein sequence translated from predicted exons in GenBank/EMBL entry U53501 was used to query Blocks+ with a cutoff expected value of 5. Known true positive hits for this query sequence are BL00094 (cytosine DNA methyltransferases) and BL00598 (chromodomains), which are the top two hits for both Block Searcher and IMPALA Searcher. Notice that none of the other hits reported are the same for both methods. Alignments are shown for the top two hits. (a) Block Searcher output. BL00094E and BL00094F were not detected because they are missing from the query as a result of erroneous gene prediction from U53501, confirmed by direct cDNA analysis (21). Each hit consists of one or more blocks from a protein group found in the query sequence. One set of the highest-scoring blocks that are in the correct order and separated by distances comparable to the Blocks Database is selected for analysis. If this set includes multiple blocks the probability that the lower scoring blocks support the highest scoring block is reported. Maps of the database blocks and query sequence are shown: ‘AAA’ represents a block roughly in proportion to its width. ‘:’ represents the minimum distance between blocks in the database. ‘.’ represents the maximum distance between blocks in the database. ‘< >’ indicate the sequence has been truncated to fit the page. The query map is aligned on the highest scoring block. Multiple block hits that are consistent with the highest scoring block are separated by colons. The alignment of the query sequence with the sequence closest to it in the Blocks Database is shown. The distance between detected blocks is listed as (min, max): for the database entry followed by the distance in the query. Upper case in the query indicates at least one occurrence of the residue in that column of the block. (b) IMPALA Searcher output. The IMPALA alignment detects the region corresponding to BL00094A in the query sequence as a separate high scoring segment, which lies 163 aa upstream of BL00094B. The query sequence is aligned with the COBBLER sequence used to make the PSI-BLAST PSSM. In the two alignments shown no gaps have been inserted within the block regions.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
