

The human SWI-SNF complex protein p270 is an ARID family member with non-sequence-specific DNA binding activity
- PMID: 10757798
- PMCID: PMC85608
- DOI: 10.1128/MCB.20.9.3137-3146.2000
The human SWI-SNF complex protein p270 is an ARID family member with non-sequence-specific DNA binding activity
Abstract
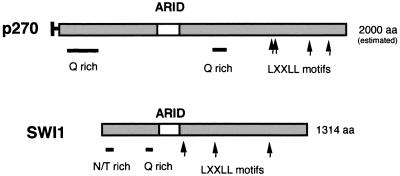
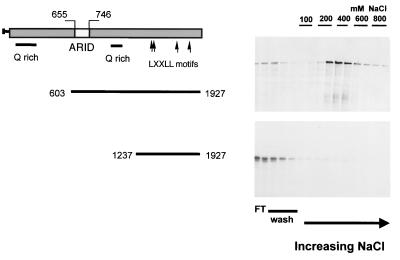
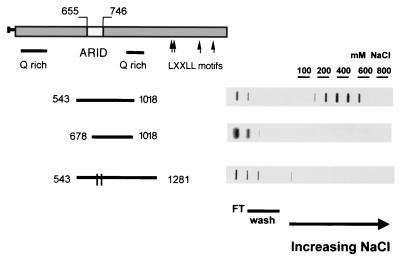
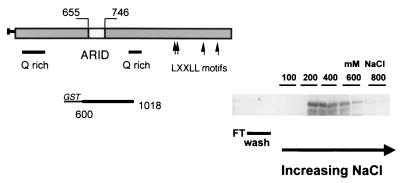
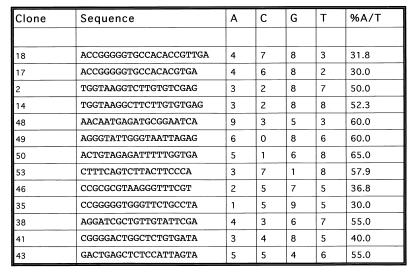
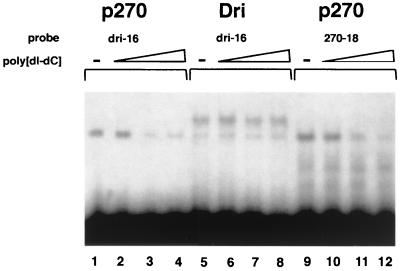
p270 is an integral member of human SWI-SNF complexes, first identified through its shared antigenic specificity with p300 and CREB binding protein. The deduced amino acid sequence of p270 reported here indicates that it is a member of an evolutionarily conserved family of proteins distinguished by the presence of a DNA binding motif termed ARID (AT-rich interactive domain). The ARID consensus and other structural features are common to both p270 and yeast SWI1, suggesting that p270 is a human counterpart of SWI1. The approximately 100-residue ARID sequence is present in a series of proteins strongly implicated in the regulation of cell growth, development, and tissue-specific gene expression. Although about a dozen ARID proteins can be identified from database searches, to date, only Bright (a regulator of B-cell-specific gene expression), dead ringer (a Drosophila melanogaster gene product required for normal development), and MRF-2 (which represses expression from the cytomegalovirus enhancer) have been analyzed directly in regard to their DNA binding properties. Each binds preferentially to AT-rich sites. In contrast, p270 shows no sequence preference in its DNA binding activity, thereby demonstrating that AT-rich binding is not an intrinsic property of ARID domains and that ARID family proteins may be involved in a wider range of DNA interactions.
Figures



References
-
- Agulnik A I, Bishop C E, Lerner J L, Agulnik S I, Solovyev V V. Analysis of mutation rates in the SMCY/SMCX genes shows that mammalian evolution is male driven. Mamm Genome. 1997;8:134–138. - PubMed
-
- Altschul S F, Boguski M S, Gish W, Wootton J C. Issues in searching molecular sequence databases. Nat Genet. 1994;6:119–129. - PubMed
-
- Altschul S F, Gish W, Miller W, Myers E W, Lippman D J. Basic local alignment search tool. J Mol Biol. 1990;215:403–410. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous