

The mosaic structure of human pericentromeric DNA: a strategy for characterizing complex regions of the human genome
- PMID: 10854415
- PMCID: PMC310890
- DOI: 10.1101/gr.10.6.839
The mosaic structure of human pericentromeric DNA: a strategy for characterizing complex regions of the human genome
Abstract
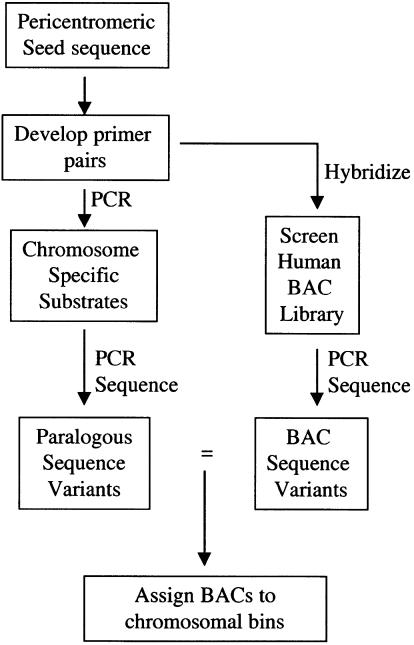
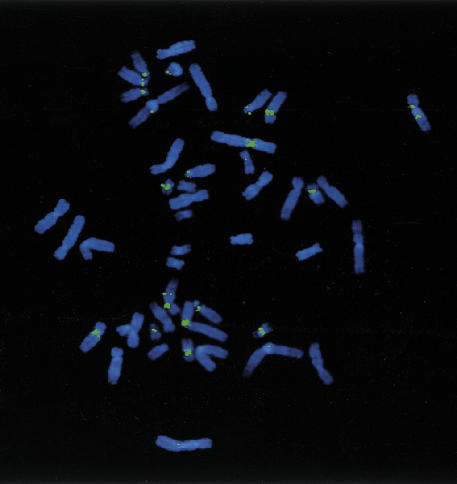
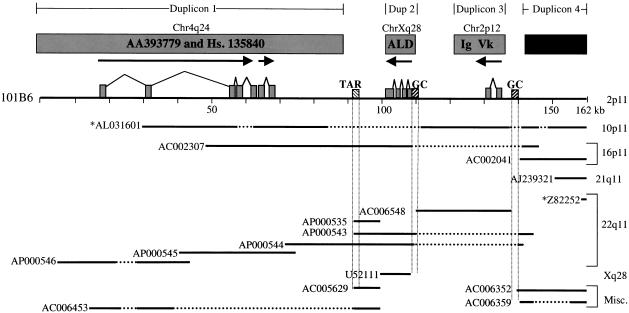
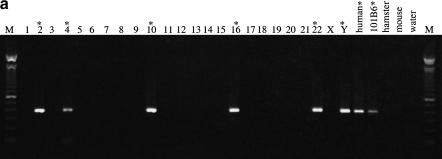
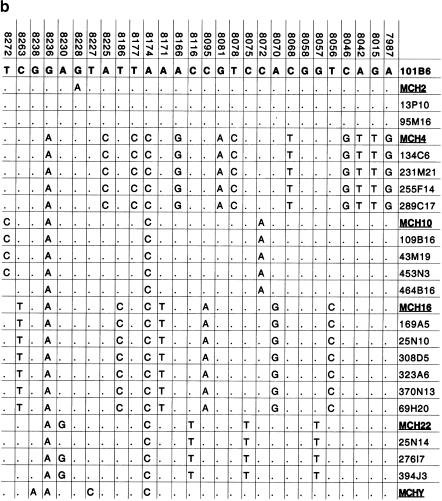
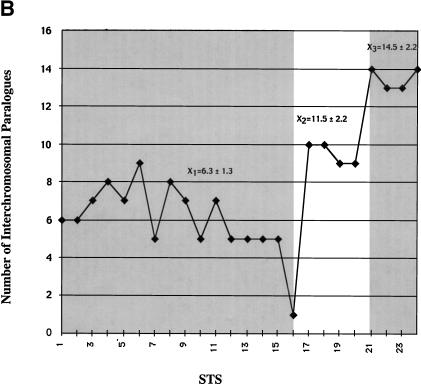
The pericentromeric regions of human chromosomes pose particular problems for both mapping and sequencing. These difficulties are due, in large part, to the presence of duplicated genomic segments that are distributed among multiple human chromosomes. To ensure contiguity of genomic sequence in these regions, we designed a sequence-based strategy to characterize different pericentromeric regions using a single (162 kb) 2p11 seed sequence as a point of reference. Molecular and cytogenetic techniques were first used to construct a paralogy map that delineated the interchromosomal distribution of duplicated segments throughout the human genome. Monochromosomal hybrid DNAs were PCR amplified by primer pairs designed to the 2p11 reference sequence. The PCR products were directly sequenced and used to develop a catalog of sequence tags for each duplicon for each chromosome. A total of 685 paralogous sequence variants were generated by sequencing 34.7 kb of paralogous pericentromeric sequence. Using PCR products as hybridization probes, we were able to identify 702 human BAC clones, of which a subset, 107 clones, were analyzed at the sequence level. We used diagnostic paralogous sequence variants to assign 65 of these BACs to at least 9 chromosomal pericentromeric regions: 1q12, 2p11, 9p11/q12, 10p11, 14q11, 15q11, 16p11, 17p11, and 22q11. Comparisons with existing sequence and physical maps for the human genome suggest that many of these BACs map to regions of the genome with sequence gaps. Our analysis indicates that large portions of pericentromeric DNA are virtually devoid of unique sequences. Instead, they consist of a mosaic of different genomic segments that have had different propensities for duplication. These biologic properties may be exploited for the rapid characterization of, not only pericentromeric DNA, but also other complex paralogous regions of the human genome.
Figures



References
-
- Amos-Landgraf JM, Ji Y, Gottlieb W, Depinet T, Wandstrat AE, Cassidy SB, Driscoll DJ, Rogan PK, Schwartz S, Nicholls RD. Chromosome breakage in the Prader-Willi and Angelman syndromes involves recombination between large, transcribed repeats at proximal and distal breakpoints. Am J Hum Genet. 1999;65:370–386. - PMC - PubMed
-
- Arnold N, Stanyon R, Jauch A, O'Brien P, Wienberg J. Identification of complex chromosome rearrangements in the gibbon by fluorescent in situ hybridization (FISH) of a human chromosome 2q specific microlibrary, yeast artificial chromosomes, and reciprocal chromosome painting. Cytogenet Cell Genet. 1996;74:80–85. - PubMed
-
- Brand-Arpon V, Rouquier S, Massa H, de Jong PJ, Ferraz C, Ioannou PA, Demaille JG, Trask BJ, Giorgi D. A genomic region encompassing a cluster of olfactory receptor genes and a myosin light chain kinase (MYLK) gene is duplicated on human chromosome regions 3q13–q21 and 3p13. Genomics. 1999;56:98–110. - PubMed
-
- Brown TA. Genomes. New York: Bios Scientific Publishers: Wiley-Liss; 1999.
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources