

Evolutionary appearance of genes encoding proteins associated with box H/ACA snoRNAs: cbf5p in Euglena gracilis, an early diverging eukaryote, and candidate Gar1p and Nop10p homologs in archaebacteria
- PMID: 10871366
- PMCID: PMC102724
- DOI: 10.1093/nar/28.12.2342
Evolutionary appearance of genes encoding proteins associated with box H/ACA snoRNAs: cbf5p in Euglena gracilis, an early diverging eukaryote, and candidate Gar1p and Nop10p homologs in archaebacteria
Abstract
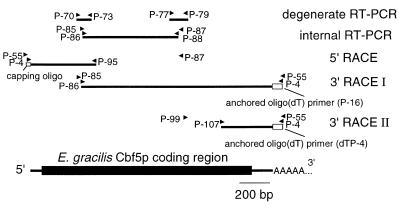
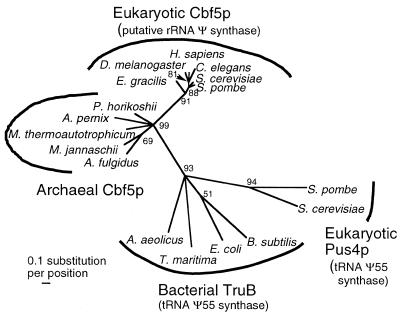
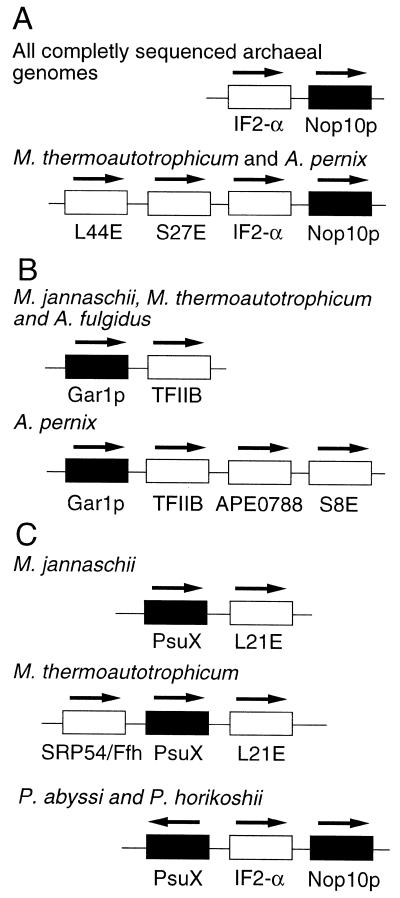
A reverse transcription-polymerase chain reaction (RT-PCR) approach was used to clone a cDNA encoding the Euglena gracilis homolog of yeast Cbf5p, a protein component of the box H/ACA class of snoRNPs that mediate pseudouridine formation in eukaryotic rRNA. Cbf5p is a putative pseudouridine synthase, and the Euglena homolog is the first full-length Cbf5p sequence to be reported for an early diverging unicellular eukaryote (protist). Phylogenetic analysis of putative pseudouridine synthase sequences confirms that archaebacterial and eukaryotic (including Euglena) Cbf5p proteins are specifically related and are distinct from the TruB/Pus4p clade that is responsible for formation of pseudouridine at position 55 in eubacterial (TruB) and eukaryotic (Pus4p) tRNAs. Using a bioinformatics approach, we also identified archaebacterial genes encoding candidate homologs of yeast Gar1p and Nop10p, two additional proteins known to be associated with eukaryotic box H/ACA snoRNPs. These observations raise the possibility that pseudouridine formation in archaebacterial rRNA may be dependent on analogs of the eukaryotic box H/ACA snoRNPs, whose evolutionary origin may therefore predate the split between Archaea (archaebacteria) and Eucarya (eukaryotes). Database searches further revealed, in archaebacterial and some eukaryotic genomes, two previously unrecognized groups of genes (here designated 'PsuX' and 'PsuY') distantly related to the Cbf5p/TruB gene family.
Figures




Similar articles
-
Cbf5p, a potential pseudouridine synthase, and Nhp2p, a putative RNA-binding protein, are present together with Gar1p in all H BOX/ACA-motif snoRNPs and constitute a common bipartite structure.RNA. 1998 Dec;4(12):1549-68. doi: 10.1017/s1355838298980761. RNA. 1998. PMID: 9848653 Free PMC article.
-
Cbf5p, the putative pseudouridine synthase of H/ACA-type snoRNPs, can form a complex with Gar1p and Nop10p in absence of Nhp2p and box H/ACA snoRNAs.RNA. 2004 Nov;10(11):1704-12. doi: 10.1261/rna.7770604. Epub 2004 Sep 23. RNA. 2004. PMID: 15388873 Free PMC article.
-
The box H + ACA snoRNAs carry Cbf5p, the putative rRNA pseudouridine synthase.Genes Dev. 1998 Feb 15;12(4):527-37. doi: 10.1101/gad.12.4.527. Genes Dev. 1998. PMID: 9472021 Free PMC article.
-
The neomuran origin of archaebacteria, the negibacterial root of the universal tree and bacterial megaclassification.Int J Syst Evol Microbiol. 2002 Jan;52(Pt 1):7-76. doi: 10.1099/00207713-52-1-7. Int J Syst Evol Microbiol. 2002. PMID: 11837318 Review.
-
The vertebrate E1/U17 small nucleolar ribonucleoprotein particle.J Cell Biochem. 2006 Jun 1;98(3):486-95. doi: 10.1002/jcb.20821. J Cell Biochem. 2006. PMID: 16475166 Review.
Cited by
-
Discovery of Pyrobaculum small RNA families with atypical pseudouridine guide RNA features.RNA. 2012 Mar;18(3):402-11. doi: 10.1261/rna.031385.111. Epub 2012 Jan 26. RNA. 2012. PMID: 22282340 Free PMC article.
-
The many facets of H/ACA ribonucleoproteins.Chromosoma. 2005 May;114(1):1-14. doi: 10.1007/s00412-005-0333-9. Epub 2005 Mar 16. Chromosoma. 2005. PMID: 15770508 Free PMC article. Review.
-
Comparative study of two box H/ACA ribonucleoprotein pseudouridine-synthases: relation between conformational dynamics of the guide RNA, enzyme assembly and activity.PLoS One. 2013 Jul 29;8(7):e70313. doi: 10.1371/journal.pone.0070313. Print 2013. PLoS One. 2013. PMID: 23922977 Free PMC article.
-
Archaeal proteins Nop10 and Gar1 increase the catalytic activity of Cbf5 in pseudouridylating tRNA.Sci Rep. 2012;2:663. doi: 10.1038/srep00663. Epub 2012 Sep 17. Sci Rep. 2012. PMID: 22993689 Free PMC article.
-
Mammalian nuclear TRUB1, mitochondrial TRUB2, and cytoplasmic PUS10 produce conserved pseudouridine 55 in different sets of tRNA.RNA. 2021 Jan;27(1):66-79. doi: 10.1261/rna.076810.120. Epub 2020 Oct 6. RNA. 2021. PMID: 33023933 Free PMC article.
References
-
- Eichler D.C. and Craig,N. (1994) Prog. Nucleic Acid Res. Mol. Biol., 49, 197–239. - PubMed
-
- Venema J. and Tollervey,D. (1995) Yeast, 11, 1629–1650. - PubMed
-
- Morrissey J.P. and Tollervey,D. (1995) Trends Biochem. Sci., 20, 78–82. - PubMed
-
- Schnare M.N. and Gray,M.W. (1990) J. Mol. Biol., 215, 73–83. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
