

Diversity of PspA: mosaic genes and evidence for past recombination in Streptococcus pneumoniae
- PMID: 10992499
- PMCID: PMC101551
- DOI: 10.1128/IAI.68.10.5889-5900.2000
Diversity of PspA: mosaic genes and evidence for past recombination in Streptococcus pneumoniae
Abstract
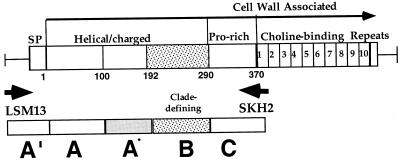
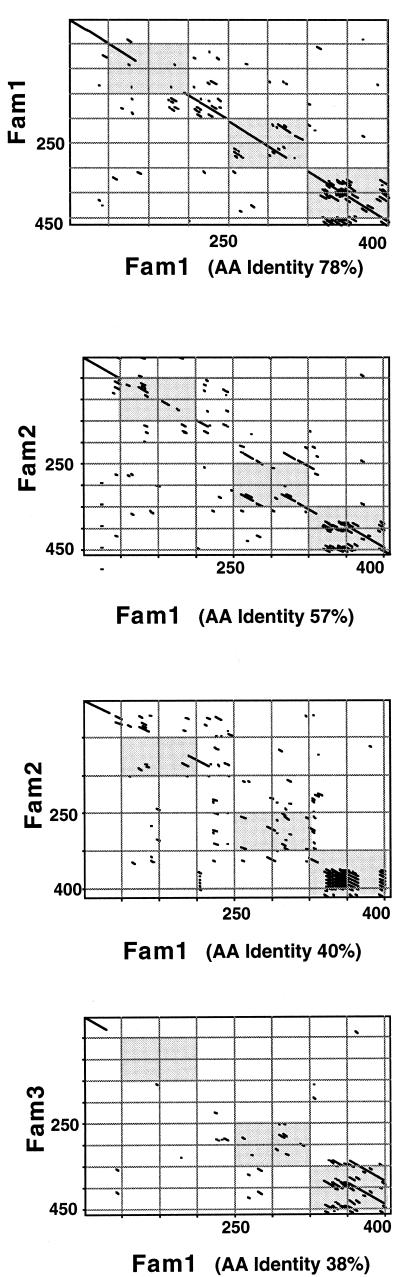
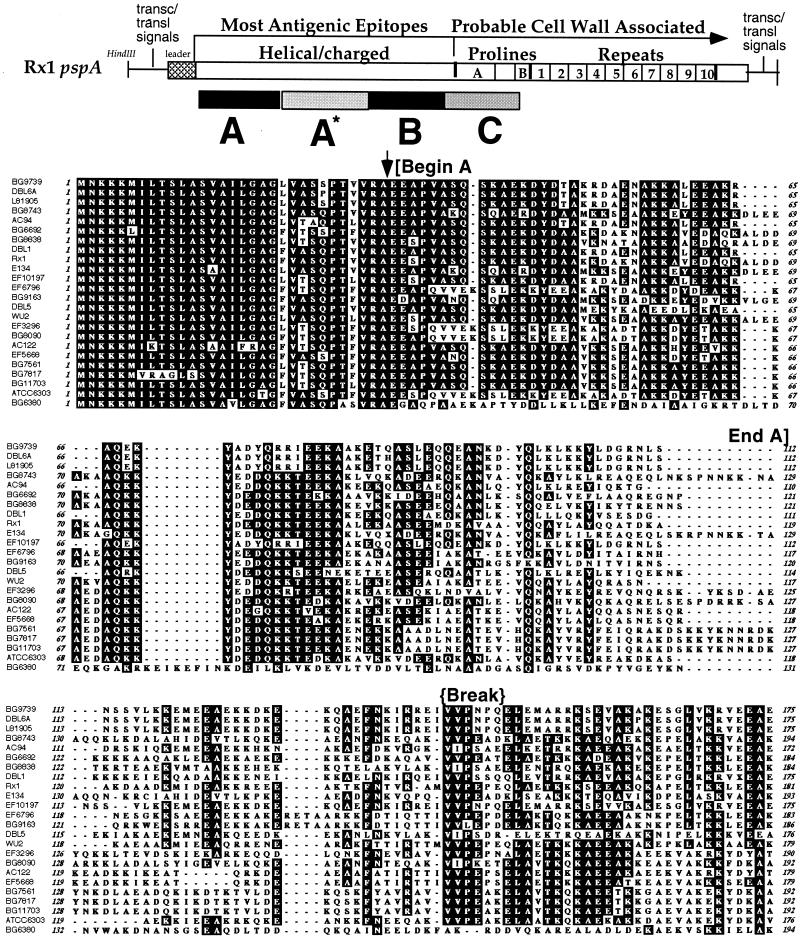
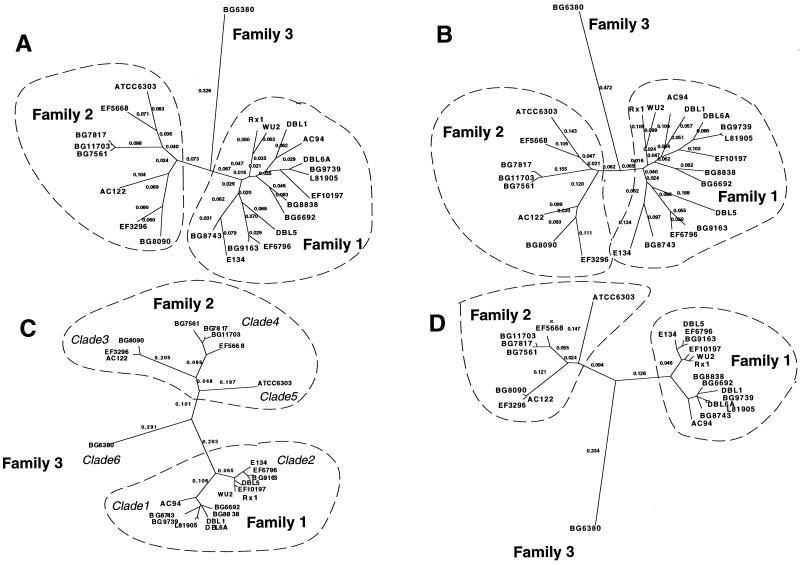
Pneumococcal surface protein A (PspA) is a serologically variable protein of Streptococcus pneumoniae. Twenty-four diverse alleles of the pspA gene were sequenced to investigate the genetic basis for serologic diversity and to evaluate the potential of diversity to have an impact on PspA's use in human vaccination. The 24 pspA gene sequences from unrelated strains revealed two major allelic types, termed "families," subdivided into clades. A highly mosaic gene structure was observed in which individual mosaic sequence blocks in PspAs diverged from each other by over 20% in many cases. This level of divergence exceeds that observed for blocks in the penicillin-binding proteins of S. pneumoniae or in many cross-species comparisons of gene loci. Conversely, because the mosaic pattern is so complex, each pair of pspA genes also has numerous shared blocks, but the position of conserved blocks differs from gene pair to gene pair. A central region of pspA, important for eliciting protective antibodies, was found in six clades, which each diverge from the other clades by >20%. Sequence relationships among the 24 alleles analyzed over three windows were discordant, indicating that intragenic recombination has occurred within this locus. The extensive recombination which generated the mosaic pattern seen in the pspA locus suggests that natural selection has operated in the history of this gene locus and underscores the likelihood that PspA may be important in the interaction between the pneumococcus and its human host.
Figures




References
-
- Abeyta M. Ph.D. dissertation. Birmingham: University of Alabama at Birmingham; 1999.
-
- Atherton J C, Cao P, Peek R M, Jr, Tummuru M K, Blaser M J, Cover T L. Mosaicism in vacuolating cytotoxin alleles of Helicobacter pylori. Association of specific vacA types with cytotoxin production and peptic ulceration. J Biol Chem. 1995;270:17771–17777. - PubMed
-
- Atherton J C, Sharp P M, Cover T L, Gonzalez-Valencia G, Peek R M, Jr, Thompson S A, Hawkey C J, Blaser M J. Vacuolating cytotoxin (vacA) alleles of Helicobacter pylori comprise two geographically widespread types, m1 and m2, and have evolved through limited recombination. Curr Microbiol. 1999;39:211–218. - PMC - PubMed
-
- Breiman R, Butler J C, Tenover F C, Elliot J, Facklam R R. Emergence of drug-resistant pneumococcal infections in the United States. JAMA. 1994;271:1831–1835. - PubMed
-
- Briles D E, Hollingshead S, Brooks-Walter A, Nabors G S, Ferguson L, Schilling M, Gravenstein S, Braun P, King J, Swift A. The potential to use PspA and other pneumococcal proteins to elicit protection against pneumococcal infection. Vaccine. 2000;18:1707–1711. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
