

Chemical approaches to control gene expression
- PMID: 11097426
- PMCID: PMC5964961
- DOI: 10.3727/000000001783992696
Chemical approaches to control gene expression
Abstract
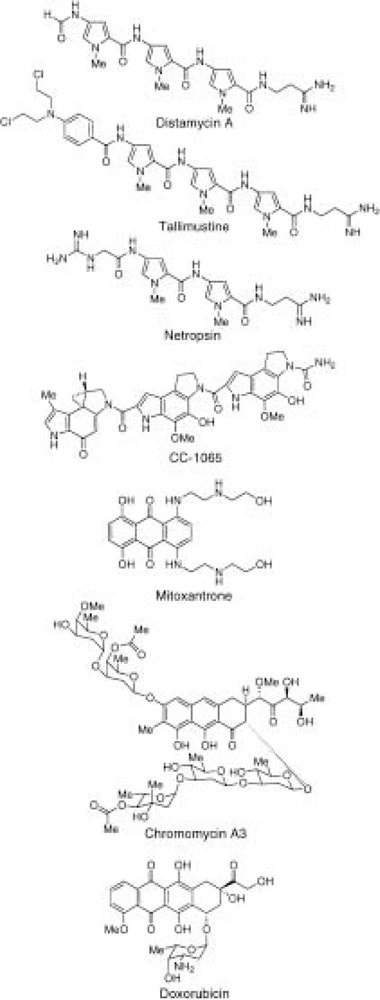
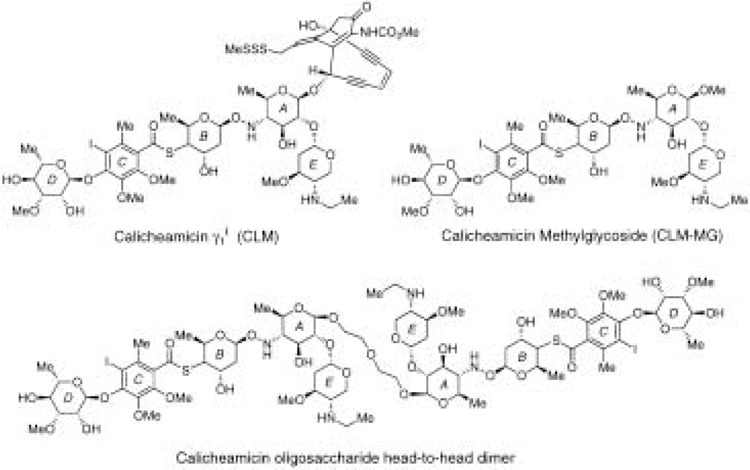
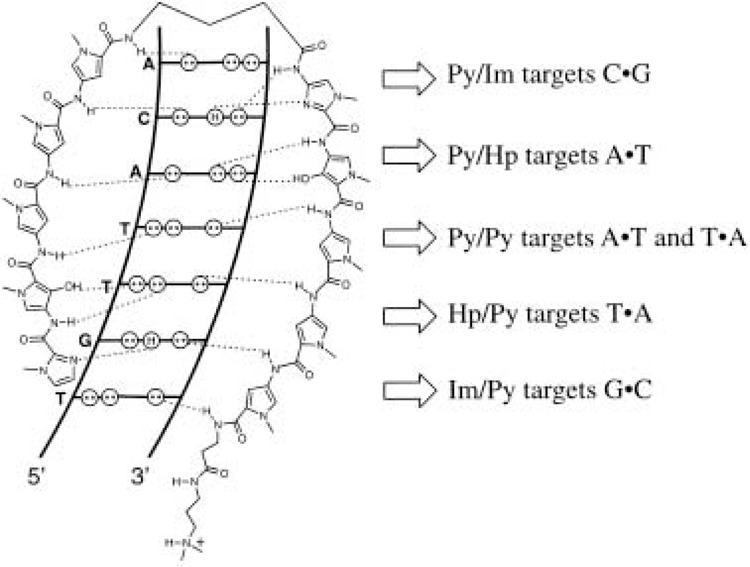
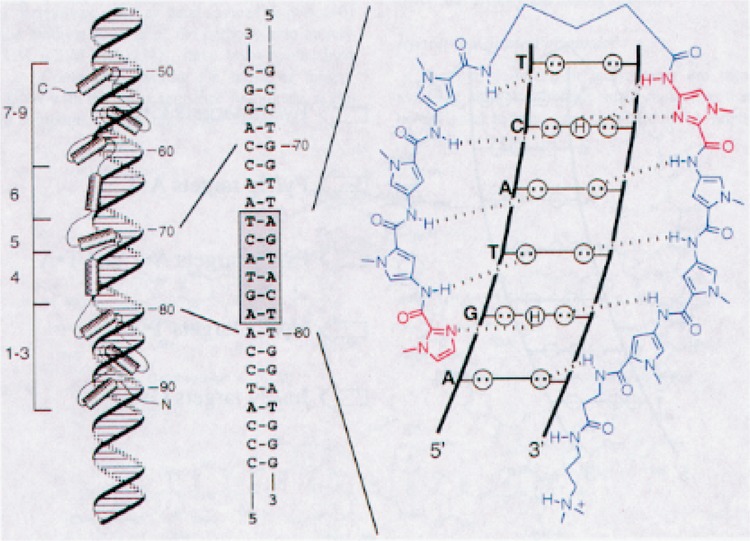
A current goal in molecular medicine is the development of new strategies to interfere with gene expression in living cells in the hope that novel therapies for human disease will result from these efforts. This review focuses on small-molecule or chemical approaches to manipulate gene expression by modulating either transcription of messenger RNA-coding genes or protein translation. The molecules under study include natural products, designed ligands, and compounds identified through functional screens of combinatorial libraries. The cellular targets for these molecules include DNA, messenger RNA, and the protein components of the transcription, RNA processing, and translational machinery. Studies with model systems have shown promise in the inhibition of both cellular and viral gene transcription and mRNA utilization. Moreover, strategies for both repression and activation of gene transcription have been described. These studies offer promise for treatment of diseases of pathogenic (viral, bacterial, etc.) and cellular origin (cancer, genetic diseases, etc.).
Figures
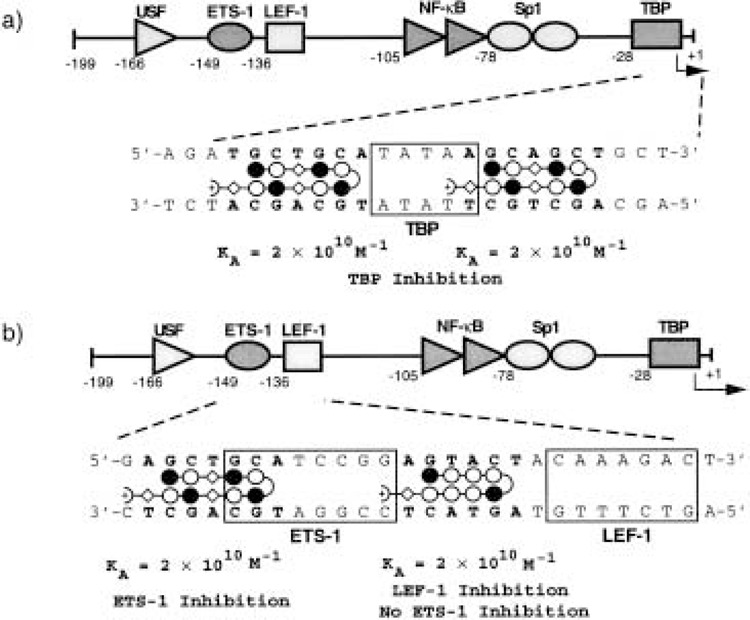
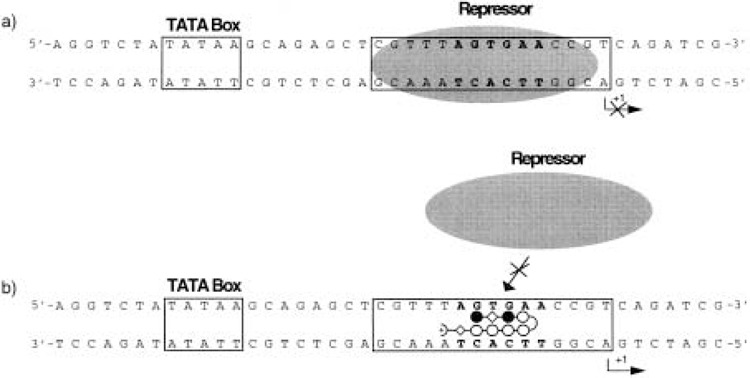
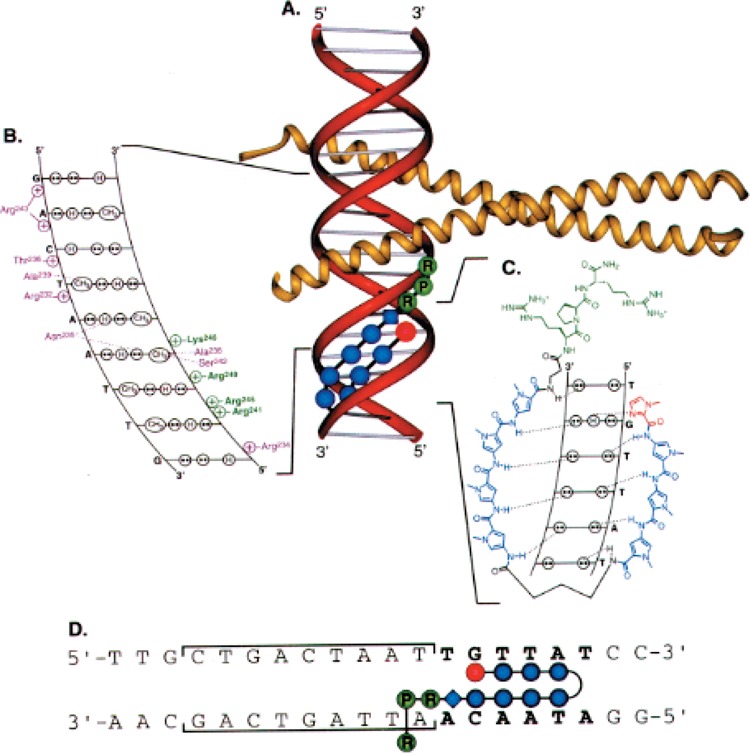
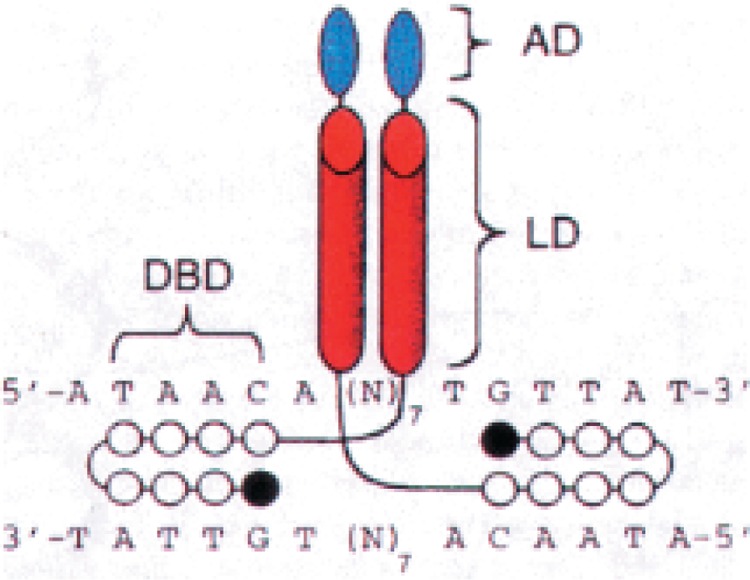
References
-
- Bianchi N.; Passadore M.; Rutigliano C.; Feriotto G.; Mischiati C.; Gambari R. Targeting of the Sp1 binding sites of HIV-1 long terminal repeat with chro-momycin. Disruption of nuclear factor.DNA complexes and inhibition of in vitro transcription. Biochem. Pharmacol. 52:1489–1498; 1996. - PubMed
-
- Breaker R. R. Catalytic DNA: In training and seeking employment. Nat. Biotechnol. 17:422–423; 1999. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources