

VIDA: a virus database system for the organization of animal virus genome open reading frames
- PMID: 11125070
- PMCID: PMC29831
- DOI: 10.1093/nar/29.1.133
VIDA: a virus database system for the organization of animal virus genome open reading frames
Abstract
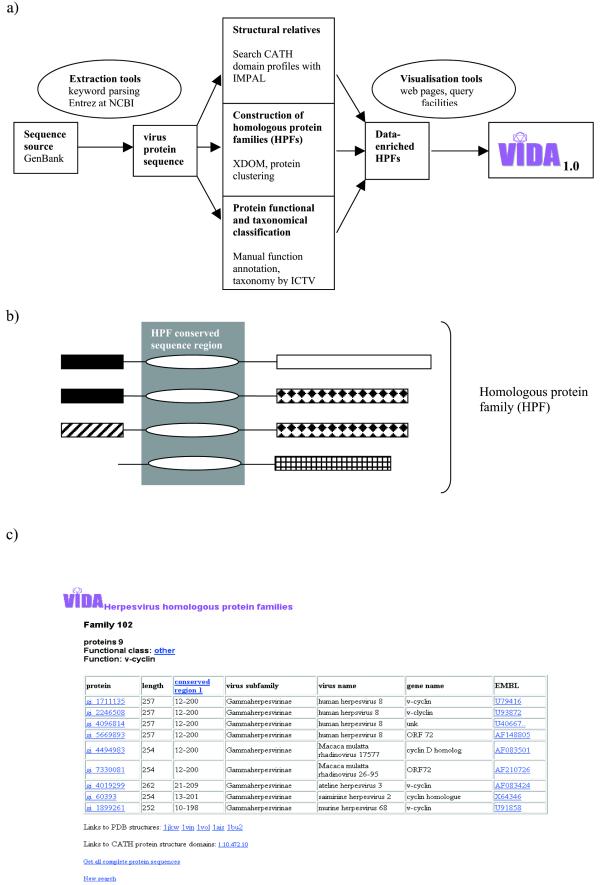
VIDA is a new virus database that organizes open reading frames (ORFs) from partial and complete genomic sequences from animal viruses. Currently VIDA includes all sequences from GenBank for Herpesviridae, Coronaviridae and Arteriviridae. The ORFs are organized into homologous protein families, which are identified on the basis of sequence similarity relationships. Conserved sequence regions of potential functional importance are identified and can be retrieved as sequence alignments. We use a controlled taxonomical and functional classification for all the proteins and protein families in the database. When available, protein structures that are related to the families have also been included. The database is available for online search and sequence information retrieval at http://www.biochem.ucl.ac.uk/bsm/virus_database/ VIDA.html.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
