

The TIGR Gene Indices: analysis of gene transcript sequences in highly sampled eukaryotic species
- PMID: 11125077
- PMCID: PMC29813
- DOI: 10.1093/nar/29.1.159
The TIGR Gene Indices: analysis of gene transcript sequences in highly sampled eukaryotic species
Abstract
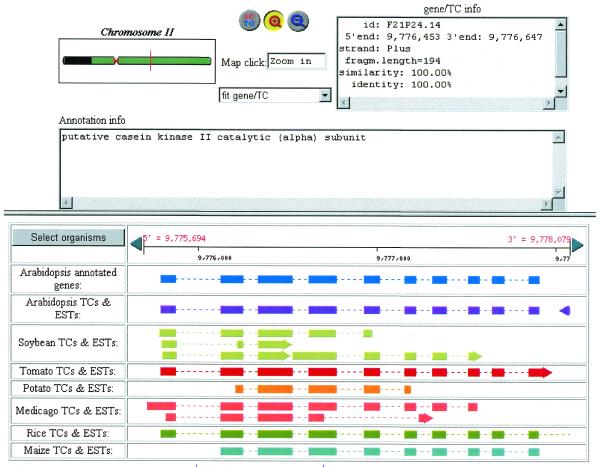
While genome sequencing projects are advancing rapidly, EST sequencing and analysis remains a primary research tool for the identification and categorization of gene sequences in a wide variety of species and an important resource for annotation of genomic sequence. The TIGR Gene Indices (http://www.tigr.org/tdb/tgi. shtml) are a collection of species-specific databases that use a highly refined protocol to analyze EST sequences in an attempt to identify the genes represented by that data and to provide additional information regarding those genes. Gene Indices are constructed by first clustering, then assembling EST and annotated gene sequences from GenBank for the targeted species. This process produces a set of unique, high-fidelity virtual transcripts, or Tentative Consensus (TC) sequences. The TC sequences can be used to provide putative genes with functional annotation, to link the transcripts to mapping and genomic sequence data, to provide links between orthologous and paralogous genes and as a resource for comparative sequence analysis.
Figures


References
-
- Adams M.D., Kelley,J.M., Gocayne,J.D., Dubnick,M., Polymeropoulos,M.H.M., Xiao,H., Merril,C.R., Wu,A., Olde,B., Moreno,R.F. et al. (1991) Complementary DNA sequencing: expressed sequence tags and human genome project. Science, 252, 1651–1656. - PubMed
-
- Boguski M.S. and Schuler,G.D. (1995) ESTablishing a human transcript map. Nature Genet., 10, 369–371. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
