

Model-based analysis of oligonucleotide arrays: expression index computation and outlier detection
- PMID: 11134512
- PMCID: PMC14539
- DOI: 10.1073/pnas.98.1.31
Model-based analysis of oligonucleotide arrays: expression index computation and outlier detection
Abstract
Recent advances in cDNA and oligonucleotide DNA arrays have made it possible to measure the abundance of mRNA transcripts for many genes simultaneously. The analysis of such experiments is nontrivial because of large data size and many levels of variation introduced at different stages of the experiments. The analysis is further complicated by the large differences that may exist among different probes used to interrogate the same gene. However, an attractive feature of high-density oligonucleotide arrays such as those produced by photolithography and inkjet technology is the standardization of chip manufacturing and hybridization process. As a result, probe-specific biases, although significant, are highly reproducible and predictable, and their adverse effect can be reduced by proper modeling and analysis methods. Here, we propose a statistical model for the probe-level data, and develop model-based estimates for gene expression indexes. We also present model-based methods for identifying and handling cross-hybridizing probes and contaminating array regions. Applications of these results will be presented elsewhere.
Figures
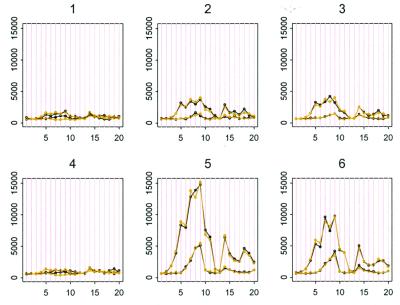
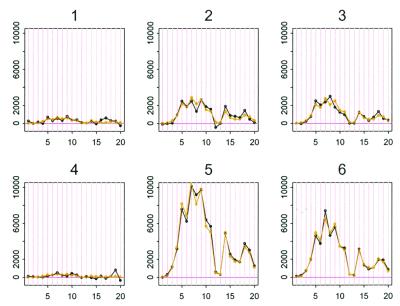
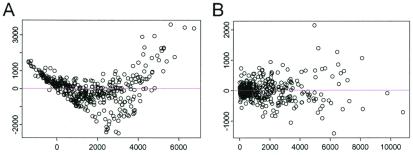
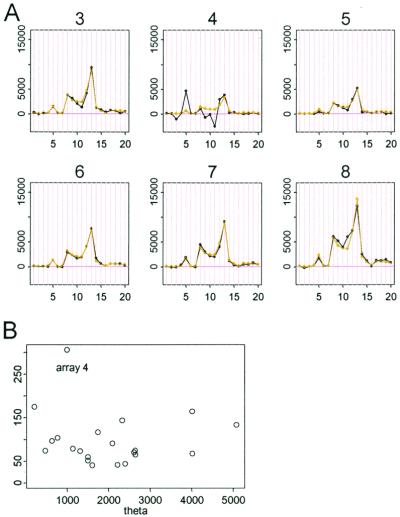
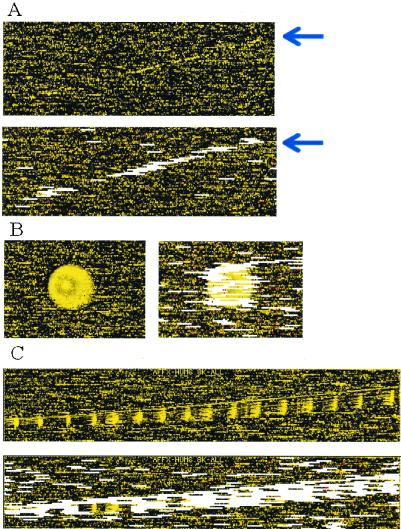
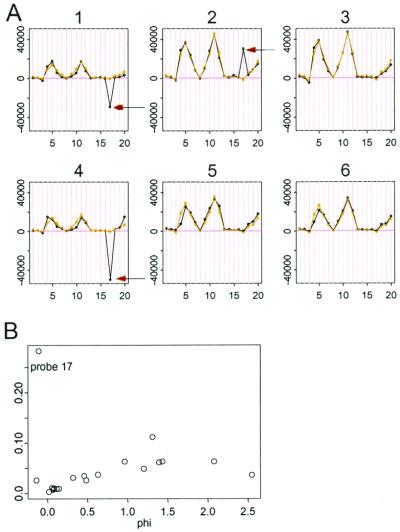
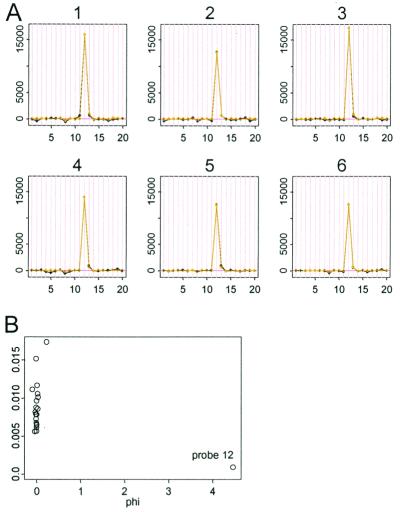

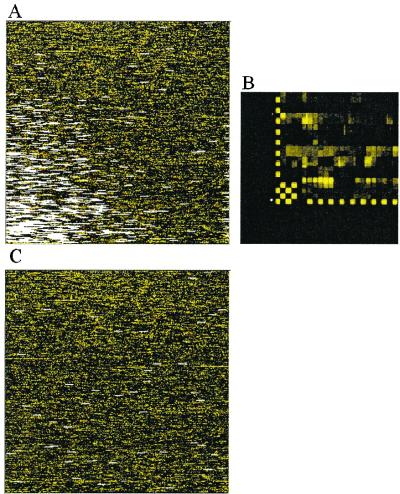

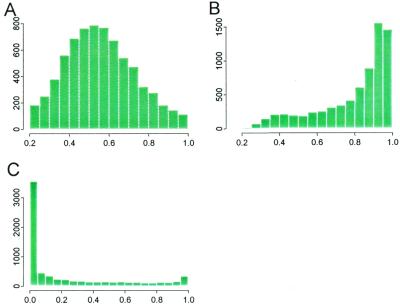
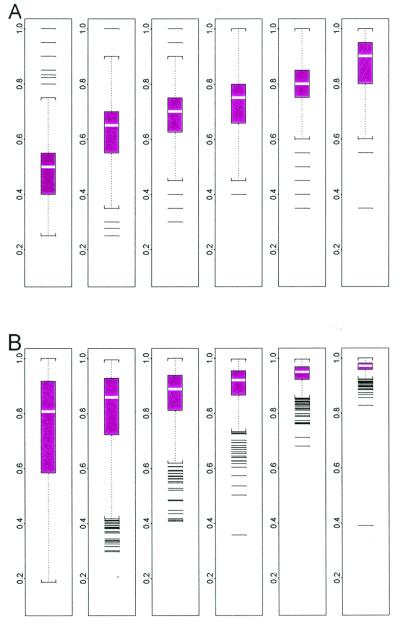
References
-
- Lockhart D, Dong H, Byrne M, Follettie M, Gallo M, Chee M, Mittmann M, Wang C, Kobayashi M, Horton H, et al. Nat Biotechnol. 1996;14:1675–1680. - PubMed
-
- Lipshutz R J, Fodor S, Gingeras T, Lockhart D. Nat Genet, supplement. 1999;21:20–24. - PubMed
-
- Wodicka L, Dong H, Mittmann M, Ho M, Lockhart D. Nat Biotechnol. 1997;15:1359–1367. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
