

Toward high-throughput genotyping: dynamic and automatic software for manipulating large-scale genotype data using fluorescently labeled dinucleotide markers
- PMID: 11435414
- PMCID: PMC311084
- DOI: 10.1101/gr.159701
Toward high-throughput genotyping: dynamic and automatic software for manipulating large-scale genotype data using fluorescently labeled dinucleotide markers
Abstract
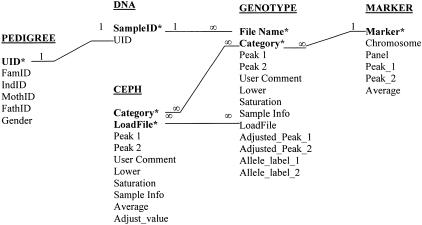
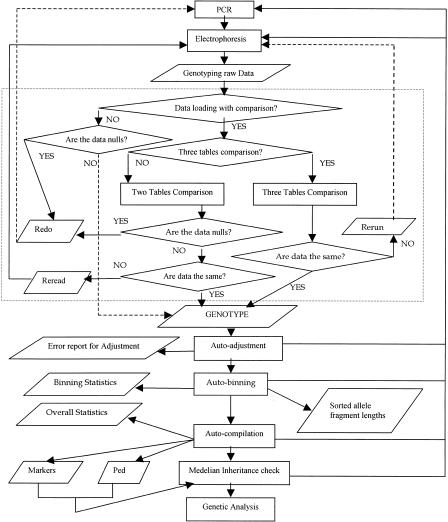
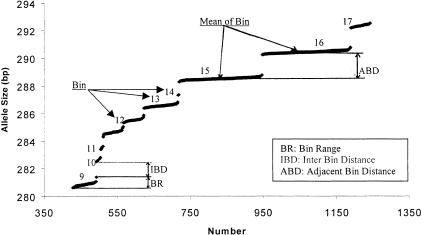
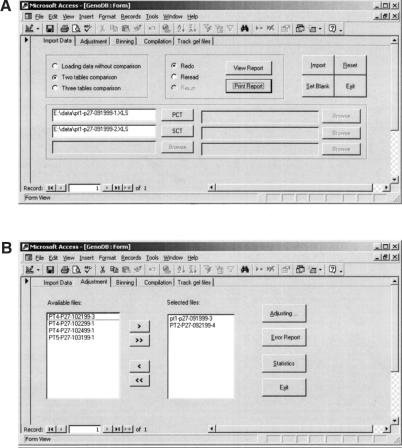
To efficiently manipulate large amounts of genotype data generated with fluorescently labeled dinucleotide markers, we developed a Microsoft database management system, named. offers several advantages. First, it accommodates the dynamic nature of the accumulations of genotype data during the genotyping process; some data need to be confirmed or replaced by repeat lab procedures. By using, the raw genotype data can be imported easily and continuously and incorporated into the database during the genotyping process that may continue over an extended period of time in large projects. Second, almost all of the procedures are automatic, including autocomparison of the raw data read by different technicians from the same gel, autoadjustment among the allele fragment-size data from cross-runs or cross-platforms, autobinning of alleles, and autocompilation of genotype data for suitable programs to perform inheritance check in pedigrees. Third, provides functions to track electrophoresis gel files to locate gel or sample sources for any resultant genotype data, which is extremely helpful for double-checking consistency of raw and final data and for directing repeat experiments. In addition, the user-friendly graphic interface of renders processing of large amounts of data much less labor-intensive. Furthermore, has built-in mechanisms to detect some genotyping errors and to assess the quality of genotype data that then are summarized in the statistic reports automatically generated by. The can easily handle >500,000 genotype data entries, a number more than sufficient for typical whole-genome linkage studies. The modules and programs we developed for the can be extended to other database platforms, such as Microsoft SQL server, if the capability to handle still greater quantities of genotype data simultaneously is desired.
Figures
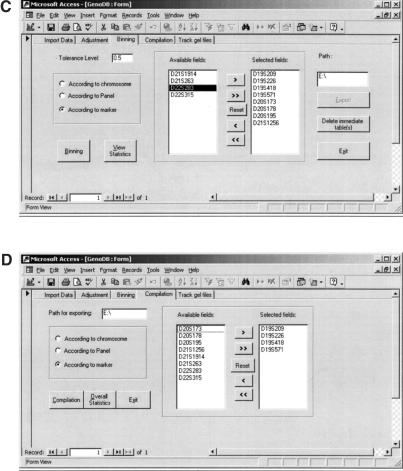
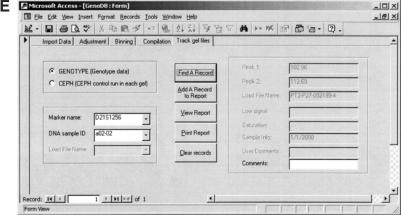
References
-
- ABI PRISM. Genotyper version 2.1, user's manual. Foster City, CA: Perkin-Elmer Applied Biosystems; 1996.
-
- ABI PRISM. Linkage mapping set version 2, user's manual. Foster City, CA: Perkin-Elmer Applied Biosystems; 1997.
-
- Chen PP. The entity-relationship model — toward a unified view of data. ACM Trans Database Syst. 1976;1:9–36.
-
- Cheung KH, Nadkarni P, Silversten S, Kidd JR, Pakstis AJ, Miller P, Kidd KK. PhenDB: An integrated client/server database for linkage and population genetics. Comput Biomed Res. 1996;29:327–337. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous