

Twin priming: a proposed mechanism for the creation of inversions in L1 retrotransposition
- PMID: 11731496
- PMCID: PMC311219
- DOI: 10.1101/gr.205701
Twin priming: a proposed mechanism for the creation of inversions in L1 retrotransposition
Abstract
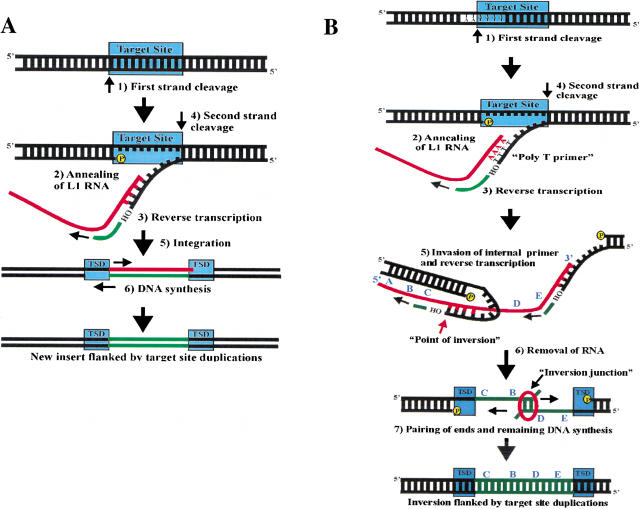
L1 retrotransposons are pervasive in the human genome. Approximately 25% of recent L1 insertions in the genome are inverted and truncated at the 5' end of the element, but the mechanism of L1 inversion has been a complete mystery. We analyzed recent L1 inversions from the genomic database and discovered several findings that suggested a mechanism for the creation of L1 inversions, which we call twin priming. Twin priming is a consequence of target primed reverse transcription (TPRT), a coupled reverse transcription/integration reaction that L1 elements are thought to use during their retrotransposition. In TPRT, the L1 endonuclease cleaves DNA at its target site to produce a double-strand break with two single-strand overhangs. During twin priming, one of the overhangs anneals to the poly(A) tail of the L1 RNA, and the other overhang anneals internally on the RNA. The overhangs then serve as primers for reverse transcription. The data further indicate that a process identical to microhomology-driven single-strand annealing resolves L1 inversion intermediates.
Figures



References
-
- Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. Basic local alignment search tool. J Mol Biol. 1990;215:403–410. - PubMed
-
- Boissinot S, Entezam A, Furano AV. Selection against deleterious LINE-1-containing loci in the human lineage. Mol Biol Evol. 2001;18:926–935. - PubMed
-
- Choi Y, Ishiguro N, Shinagawa M, Kim CJ, Okamoto Y, Minami S, Ogihara K. Molecular structure of canine LINE-1 elements in canine transmissible venereal tumor. Anim Genet. 1999;30:51–53. - PubMed
-
- Cost GJ, Boeke JD. Targeting of human retrotransposon integration is directed by the specificity of the L1 endonuclease for regions of unusual DNA structure. Biochemistry. 1998;37:18081–18093. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous