

doi: 10.1093/nar/30.1.235.
The PROSITE database, its status in 2002
Affiliations
- PMID: 11752303
- PMCID: PMC99105
- DOI: 10.1093/nar/30.1.235
Item in Clipboard
The PROSITE database, its status in 2002
Nucleic Acids Res.
.
Abstract
PROSITE [Bairoch and Bucher (1994) Nucleic Acids Res., 22, 3583-3589; Hofmann et al. (1999) Nucleic Acids Res., 27, 215-219] is a method of identifying the functions of uncharacterized proteins translated from genomic or cDNA sequences. The PROSITE database (http://www.expasy.org/prosite/) consists of biologically significant patterns and profiles designed in such a way that with appropriate computational tools it can rapidly and reliably help to determine to which known family of proteins (if any) a new sequence belongs, or which known domain(s) it contains.
Figures
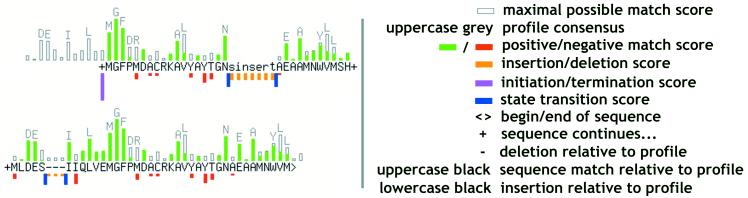
Graphical representation of a match.
References
-
- Doolittle R.F. (1986) Of URFs and ORFs: A Primer on How to Analyze Derived Amino Acid Sequences. University Science Books, Mill Valley, CA, pp. 3–36.
-
- Lesk A.M. (1988) PartII Sources of information. The NBRF protein sequence database. In Lesk,A.M. (ed.), Computational Molecular Biology, Oxford University Press, Oxford, UK, pp. 17–26.
-
- Bucher P. and Bairoch,A. (1994) A generalized profile syntax for biomolecular sequence motifs and its function in automatic sequence interpretation. In Altman,R., Brutlag,D., Karp,P., Lathrop,R. and Searls,D. (eds), Proceedings of the Second International Conference on Intelligent Systems for Molecular Biology. AAAI Press, Menlo Park, pp. 53–61. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
