

Structural classification of zinc fingers: survey and summary
- PMID: 12527760
- PMCID: PMC140525
- DOI: 10.1093/nar/gkg161
Structural classification of zinc fingers: survey and summary
Abstract
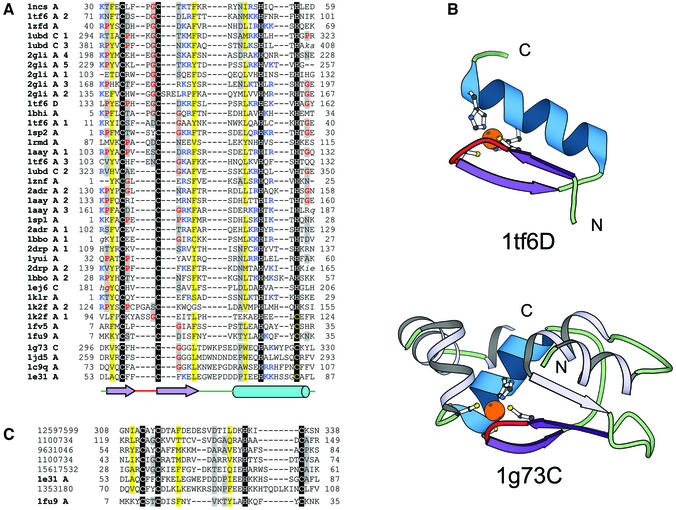
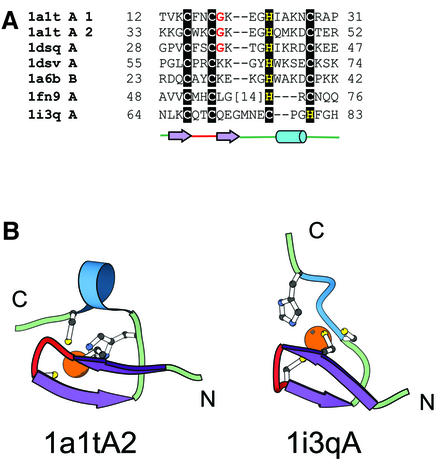
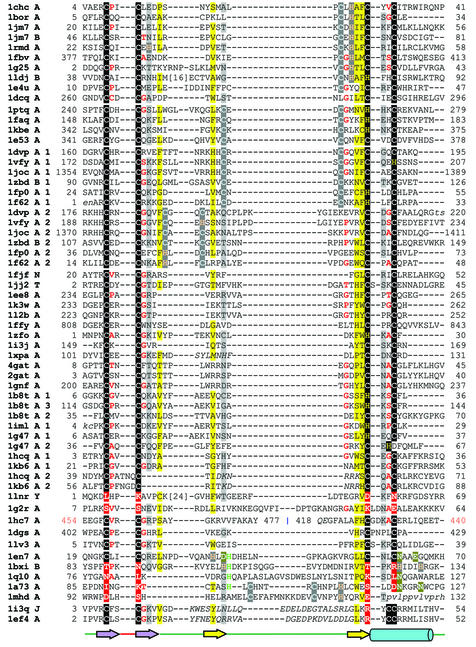
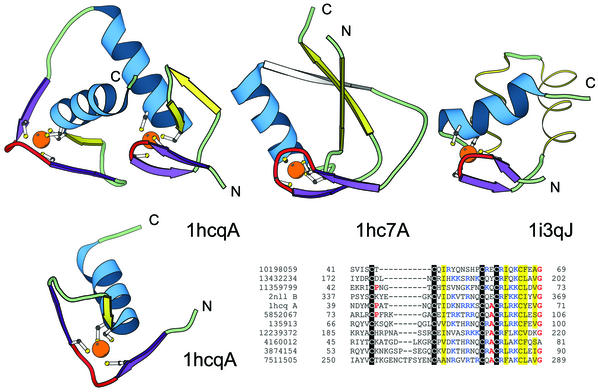
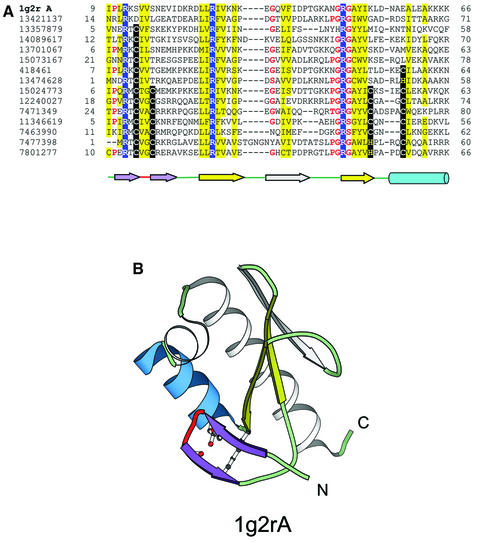
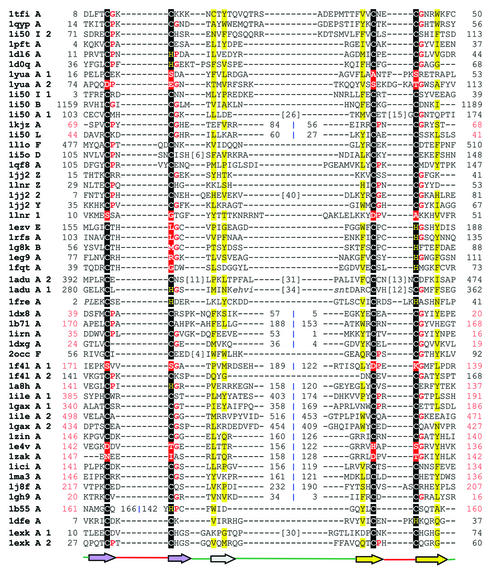
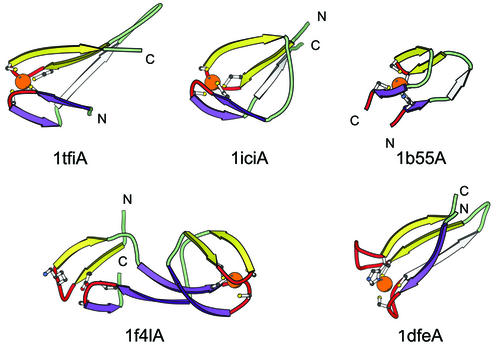
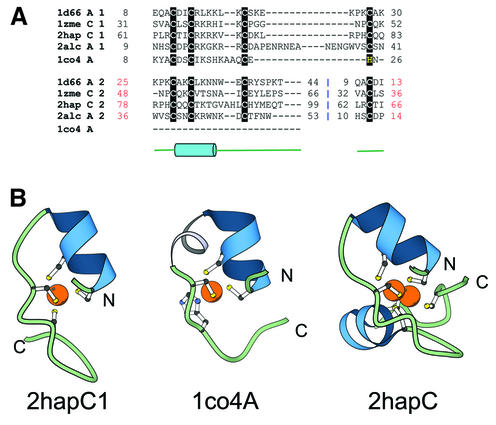
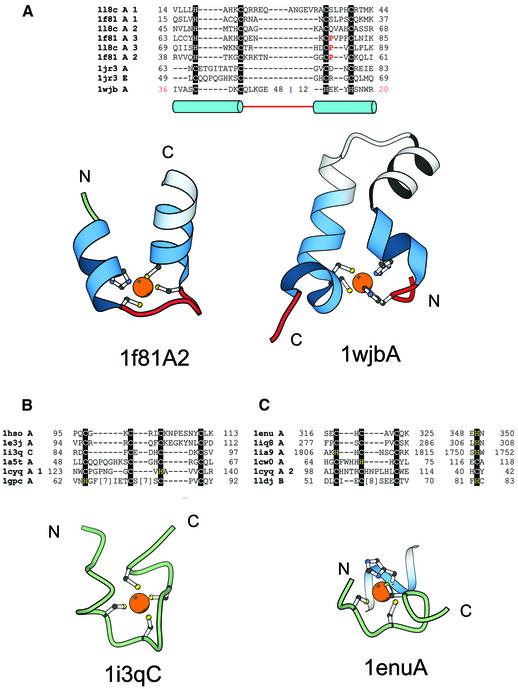
Zinc fingers are small protein domains in which zinc plays a structural role contributing to the stability of the domain. Zinc fingers are structurally diverse and are present among proteins that perform a broad range of functions in various cellular processes, such as replication and repair, transcription and translation, metabolism and signaling, cell proliferation and apoptosis. Zinc fingers typically function as interaction modules and bind to a wide variety of compounds, such as nucleic acids, proteins and small molecules. Here we present a comprehensive classification of zinc finger spatial structures. We find that each available zinc finger structure can be placed into one of eight fold groups that we define based on the structural properties in the vicinity of the zinc-binding site. Three of these fold groups comprise the majority of zinc fingers, namely, C2H2-like finger, treble clef finger and the zinc ribbon. Evolutionary relatedness of proteins within fold groups is not implied, but each group is divided into families of potential homologs. We compare our classification to existing groupings of zinc fingers and find that we define more encompassing fold groups, which bring together proteins whose similarities have previously remained unappreciated. We analyze functional properties of different zinc fingers and overlay them onto our classification. The classification helps in understanding the relationship between the structure, function and evolutionary history of these domains. The results are available as an online database of zinc finger structures.
Figures
References
-
- Berman H.M., Battistuz,T., Bhat,T.N., Bluhm,W.F., Bourne,P.E., Burkhardt,K., Feng,Z., Gilliland,G.L., Iype,L., Jain,S. et al. (2002) The protein data bank. Acta Crystallogr. D Biol. Crystallogr., 58, 899–907. - PubMed
-
- Murzin A.G. (1998) How far divergent evolution goes in proteins. Curr. Opin. Struct. Biol., 8, 380–387. - PubMed
-
- Shindyalov I.N. and Bourne,P.E. (1998) Protein structure alignment by incremental combinatorial extension (CE) of the optimal path. Protein Eng., 11, 739–747. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
