

Review
doi: 10.1186/gb-2002-3-12-research0081.
Epub 2002 Dec 23.
An integrated computational pipeline and database to support whole-genome sequence annotation
Affiliations
- PMID: 12537570
- PMCID: PMC151183
- DOI: 10.1186/gb-2002-3-12-research0081
Item in Clipboard
Review
An integrated computational pipeline and database to support whole-genome sequence annotation
Genome Biol.
2002.
Abstract
We describe here our experience in annotating the Drosophila melanogaster genome sequence, in the course of which we developed several new open-source software tools and a database schema to support large-scale genome annotation. We have developed these into an integrated and reusable software system for whole-genome annotation. The key contributions to overall annotation quality are the marshalling of high-quality sequences for alignments and the design of a system with an adaptable and expandable flexible architecture.
Figures
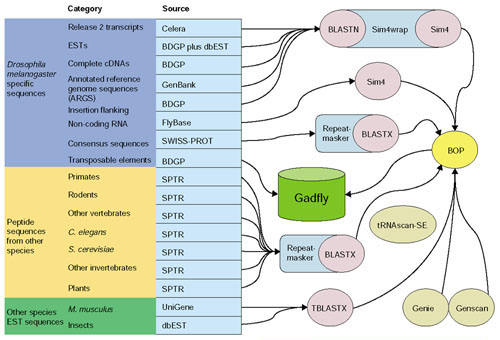
Gadfly data sources and analyses. This figure provides an overview of the pipeline analyses that flow into the central annotation database (Gadfly) and are provided to the curators for annotation. The D. melanogaster-specific datasets (dark blue) are one of the following: nucleic acids, peptides (from SPTR: SWISS-PROT/TrEMBL/TrEMBLNEW [31]), or transposable elements (the source of the sequences are listed in the light-blue column). The nucleic acids are aligned using sim4 and the peptides using BLASTX. The transposable elements are the product of a more detailed analysis [46] and their coordinates were recorded directly in Gadfly. The peptide datasets from other species (yellow) were obtained from SWISS-PROT and aligned using BLASTX. We used TBLASTX to translate (in all six frames) and align the rodent UniGene [47] and insect ESTs from dbEST [48] (green). For ab initio predictions on the genomic sequence we used Genie [42], Genscan [43] and tRNAscan-SE [44]. BOP was used to filter BLAST and sim4 results and parse all the results to output GAME XML; the results were recorded in Gadfly by loading the XML into the database.
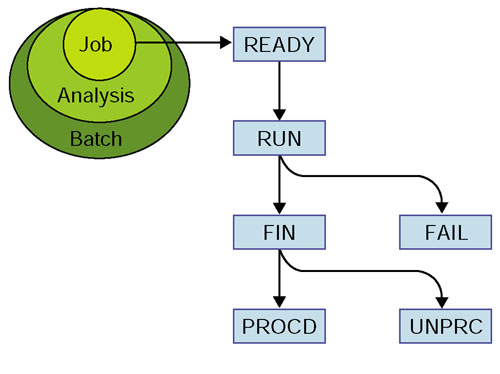
Pipeline job management. The pipeline database tracks the status of jobs, analyses and batches. As indicated by the ovals, a batch is a collection of analyses, and an analysis is a set of jobs. A job is a single execution of a program on a single sequence (for example, BLASTX similarity searching of a unit of genomic sequence). All three have a current task status. The slowest running in the set dictates the status of an analysis and a batch. Thus, in terms of analyses, the analysis status is the same as the status of the slowest job in that analysis, and for batches, the status is the same as the slowest analysis in that batch. The allowed values for the status attribute are READY, RUN, FIN, PROCD, UNPRC and FAIL. With respect to jobs, READY means the jobs are ready to be sent to the pipeline queue, RUN means the jobs are on the queue or being run, FIN means the jobs have run but have not yet been processed by BOP to extract the results from the raw data, UNPRC generally means there was an error in the processing step, FAIL means there was an error in job execution, and PROCD means the jobs have run and been processed by BOP.
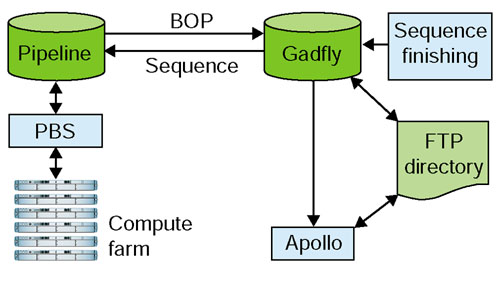
Pipeline dataflow. Finished genomic sequence is deposited in Gadfly, and then fed to the pipeline database, which manages jobs, dispatching them to the compute farm via PBS. When a job finishes, the pipeline database stores the output. BOP filters this output and exports GAME XML to Gadfly. A cycle of annotation consists of curators loading GAME XML into Apollo, either directly from Gadfly or from a data directory. Modified annotations are then written to a directory and loaded into Gadfly.
References
-
- Ensembl Analysis Pipeline http://www.ensembl.org/Docs/wiki/html/EnsemblDocs/Pipeline.html
-
- NCBI genome sequence and annotation process http://www.ncbi.nlm.nih.gov/genome/guide/build.html#annot
-
- Saccharomyces genome database http://genome-www.stanford.edu/Saccharomyces/
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
