

Comparative Study
doi: 10.1093/nar/gkg438.
Computational identification of non-coding RNAs in Saccharomyces cerevisiae by comparative genomics
Affiliations
- PMID: 12853629
- PMCID: PMC165953
- DOI: 10.1093/nar/gkg438
Item in Clipboard
Comparative Study
Computational identification of non-coding RNAs in Saccharomyces cerevisiae by comparative genomics
Nucleic Acids Res.
.
Abstract
We screened for new structural non-coding RNAs (ncRNAs) in the genome sequence of the yeast Saccharomyces cerevisiae using computational comparative analysis of genome sequences from five related species of Saccharomyces. The screen identified 92 candidate ncRNA genes. Thirteen showed discrete transcripts when assayed by northern blot. Of these, eight appear to be novel ncRNAs ranging in size from 268 to 775 nt, including three new H/ACA box small nucleolar RNAs.
Figures

Northern blots for the 13 transcripts found in this screen. The candidate name is followed by either (W) or (C), indicating that the northern displayed was probed with an oligonucleotide targeting transcripts originating from the Watson or Crick strand. Flanking bands in the 100 bp ladder (which is in lane 2) are indicated in lane 1. Lanes 3–7 contain total RNA from the following growth conditions (all grown at 30°C to mid-log except where noted): lane 3, minimal media; lane 4, YPGalactose; lane 5, heat-shock 30 min at 37°C in YPD; lane 6, saturated YPD growth; lane 7, YPD. Lane 8 is the estimated size of each of the transcripts, shown as a bracketed number.

Identification of a possible translationally active ORF in candidate 85. The line below the multiple sequence alignment shows the frame of the ORF. Perfectly conserved columns are shaded. The number of perfectly conserved columns in the first, second and third codon positions are summed and normalized by the total number of perfectly conserved columns. The total number of perfectly conserved columns in this alignment is 144, so the expected distribution over the three codon positions in the random model is 0.3333 ∗ 144 = 48. Candidate 85 shows 56, 57 and 31 columns conserved in the first, second and third codon positions, respectively. The G-statistic is therefore G = 2[56 ∗ ln(56/48) + 57 ∗ ln(57/48) + 31 ∗ ln(31/48)] = 9.7. A G-value of 9.7 is >5.9, indicating that this distribution is significantly non-random at the 0.05 confidence level (P ∼ 0.01).
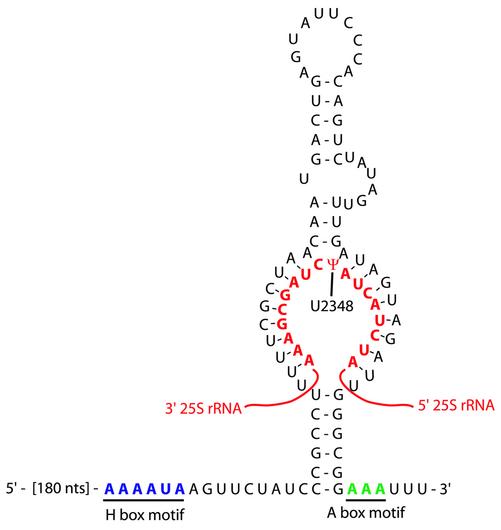
RUF2 (candidate 29) is a H/ACA box snoRNA. The 25S rRNA sequence is in shown in red. The H box (ANANNA) is in blue and the ACA box (ANA) is green. RUF2 apparently directs pseudouridylation of U-2348 of 25S rRNA. The site of pseudouridylation is denoted by ψ.
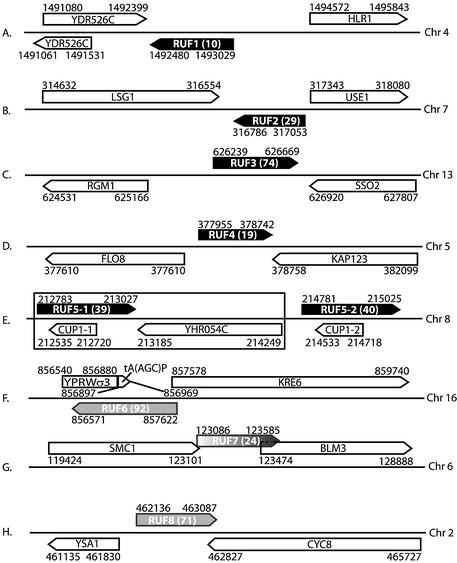
Schematic of the genomic context for the eight ncRNA candidates. SGD annotation is represented by open boxes. The ncRNAs for which complete RACE data are available are shown as black boxes, and the candidates for which there is incomplete or no RACE data are shown as gray or black-to-gray gradient boxes. The coordinates for the bounds of the genes are noted. For each RNA, the RUF names are given followed by the candidate number in parenthesis. (A) RUF1 (candidate 10). (B) RUF2 (candidate 29). (C) RUF3 (candidate 74). (D) RUF4 (candidate 19). (E) RUF5-1 (candidate 39) and RUF5-2 (candidate 40), and the CUP1 tandem array. The repeating unit is denoted by the box. (F and H) RUF6 (candidate 92) and RUF 8 (candidate 71). No RACE data are available, so the potential bounds of the gene are calculated by adding the size observed on the northern to each side of the bounds of the oligonucleotide probe. (G) RUF7 (candidate 24). Only 3′ RACE data are available (as indicated by the darker end of the box), so the bounds of the transcript are calculated by adding the size observed on the northern to the bounds of the oligonucleotide probe.
References
-
- Eddy S.R. (2001) Non-coding RNA genes and the modern RNA world. Nature Rev. Genet., 2, 919–929. - PubMed
-
- Storz G. (2002) An expanding universe of noncoding RNAs. Science, 296, 1260–1263. - PubMed
-
- Kiss T. (2002) Small nucleolar RNAs: an abundant group of noncoding RNAs with diverse cellular functions. Cell, 109, 145–148. - PubMed
-
- Pasquinelli A.E. and Ruvkun,G. (2002) Control and developmental timing by microRNAs and their targets. Annu. Rev. Cell. Dev. Biol., 18, 495–513. - PubMed
-
- Rivas E., Klein,R.J., Jones,T.A. and Eddy,S.R. (2001) Computational identification of noncoding RNAs in E. coli by comparative genomics. Curr. Biol., 11, 1369–1373. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
