

A two-stage unsupervised learning algorithm reproduces multisensory enhancement in a neural network model of the corticotectal system
- PMID: 12890764
- PMCID: PMC6740726
- DOI: 10.1523/JNEUROSCI.23-17-06713.2003
A two-stage unsupervised learning algorithm reproduces multisensory enhancement in a neural network model of the corticotectal system
Abstract
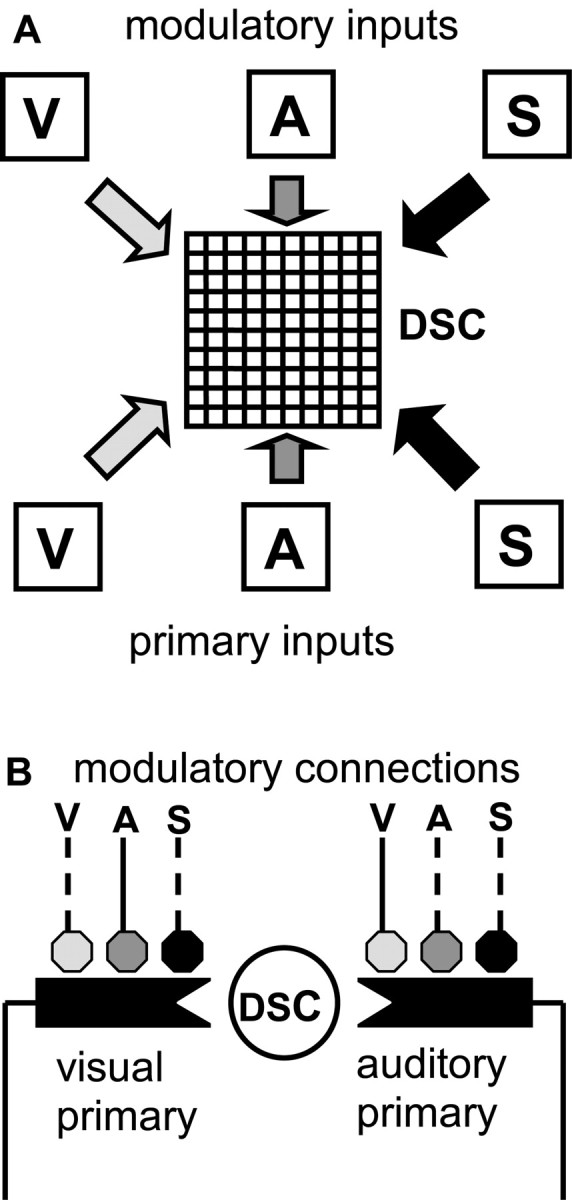
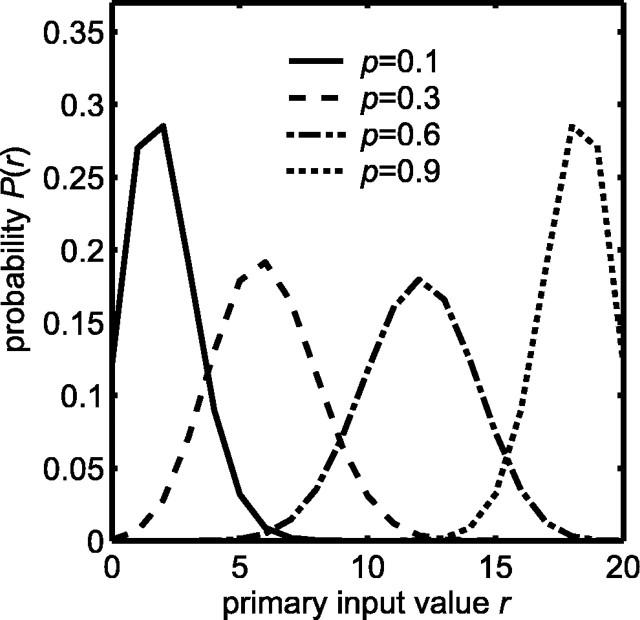
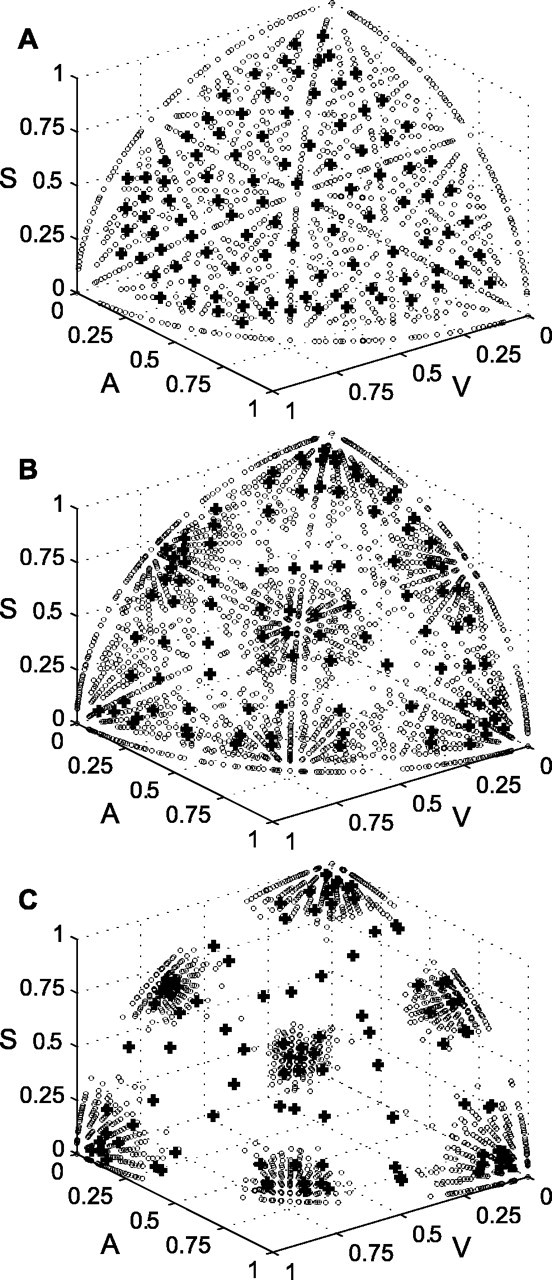
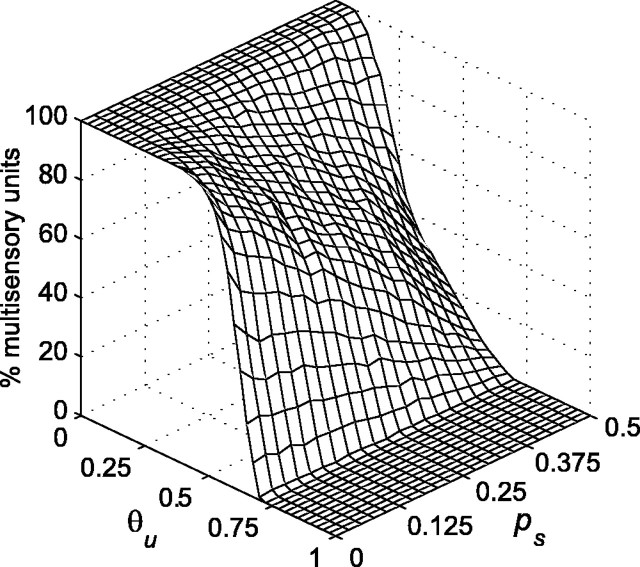
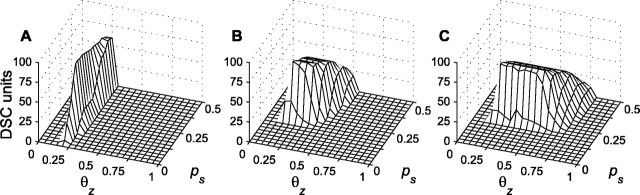
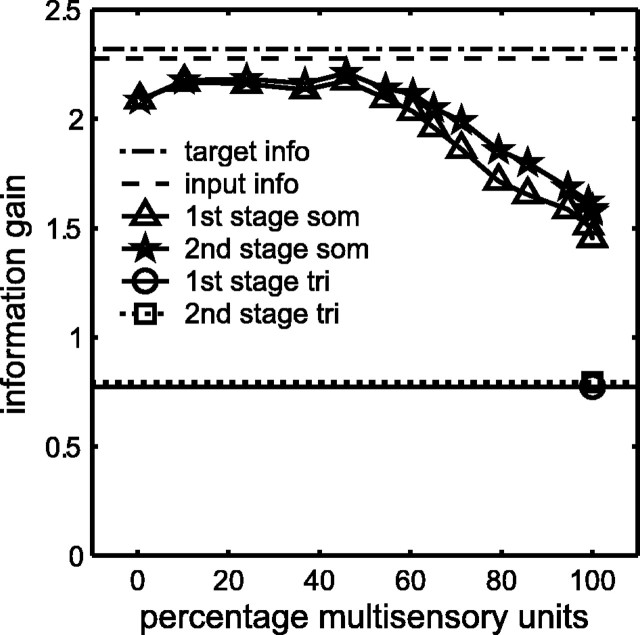
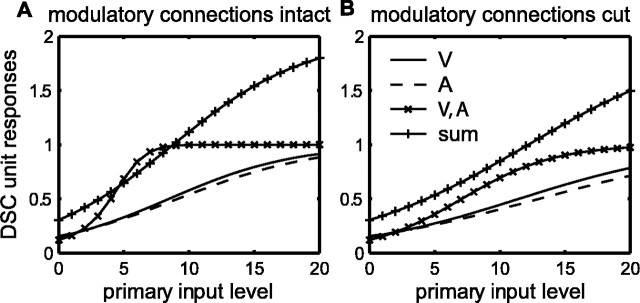
Multisensory enhancement (MSE) is the augmentation of the response to sensory stimulation of one modality by stimulation of a different modality. It has been described for multisensory neurons in the deep superior colliculus (DSC) of mammals, which function to detect, and direct orienting movements toward, the sources of stimulation (targets). MSE would seem to improve the ability of DSC neurons to detect targets, but many mammalian DSC neurons are unimodal. MSE requires descending input to DSC from certain regions of parietal cortex. Paradoxically, the descending projections necessary for MSE originate from unimodal cortical neurons. MSE, and the puzzling findings associated with it, can be simulated using a model of the corticotectal system. In the model, a network of DSC units receives primary sensory input that can be augmented by modulatory cortical input. Connection weights from primary and modulatory inputs are trained in stages one (Hebb) and two (Hebb-anti-Hebb), respectively, of an unsupervised two-stage algorithm. Two-stage training causes DSC units to extract information concerning simulated targets from their inputs. It also causes the DSC to develop a mixture of unimodal and multisensory units. The percentage of DSC multisensory units is determined by the proportion of cross-modal targets and by primary input ambiguity. Multisensory DSC units develop MSE, which depends on unimodal modulatory connections. Removal of the modulatory influence greatly reduces MSE but has little effect on DSC unit responses to stimuli of a single modality. The correspondence between model and data suggests that two-stage training captures important features of self-organization in the real corticotectal system.
Figures

References
-
- Anastasio TJ, Patton PE, Belkacem-Boussaid K ( 2000) Using Bayes' rule to model multisensory enhancement in the superior colliculus. Neural Comput 12: 997-1019. - PubMed
-
- Anwyl R ( 1999) Metabotrophic glutamate receptors: electrophysiological properties and role in plasticity. Brain Res Rev 29: 83-120. - PubMed
-
- Appelbaum D ( 1996) Probability and information: an integrated approach, Chap 5.7, pp 81-84. Cambridge, UK: Cambridge UP.
-
- Binns KE ( 1999) The synaptic pharmacology underlying sensory processing in the superior colliculus. Prog Neurobiol 59: 129-159. - PubMed
-
- Binns KE, Salt TE ( 1996) Importance of NMDA receptors for multimodal integration in the deep layers of the cat superior colliculus. J Neurophysiol 75: 920-930. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources