

Evidence that rice and other cereals are ancient aneuploids
- PMID: 12953120
- PMCID: PMC181340
- DOI: 10.1105/tpc.014019
Evidence that rice and other cereals are ancient aneuploids
Abstract
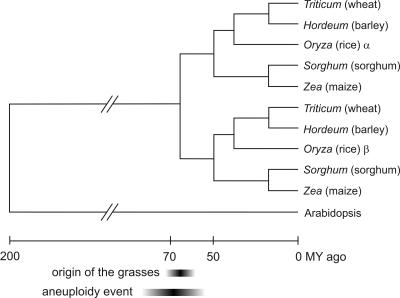
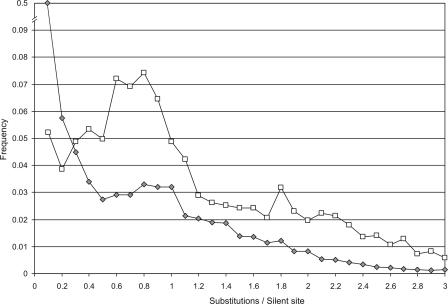
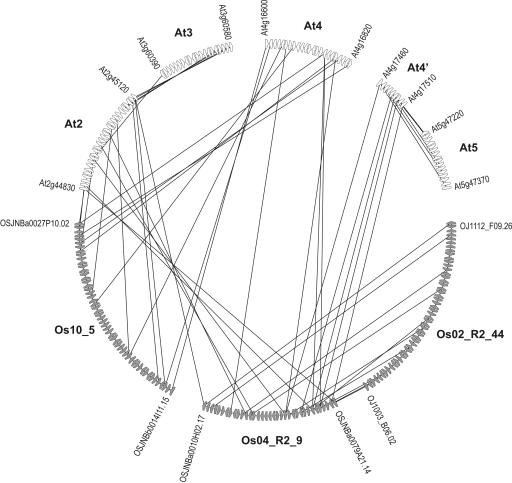
Detailed analyses of the genomes of several model organisms revealed that large-scale gene or even entire-genome duplications have played prominent roles in the evolutionary history of many eukaryotes. Recently, strong evidence has been presented that the genomic structure of the dicotyledonous model plant species Arabidopsis is the result of multiple rounds of entire-genome duplications. Here, we analyze the genome of the monocotyledonous model plant species rice, for which a draft of the genomic sequence was published recently. We show that a substantial fraction of all rice genes ( approximately 15%) are found in duplicated segments. Dating of these block duplications, their nonuniform distribution over the different rice chromosomes, and comparison with the duplication history of Arabidopsis suggest that rice is not an ancient polyploid, as suggested previously, but an ancient aneuploid that has experienced the duplication of one-or a large part of one-chromosome in its evolutionary past, approximately 70 million years ago. This date predates the divergence of most of the cereals, and relative dating by phylogenetic analysis shows that this duplication event is shared by most if not all of them.
Figures
References
-
- Arabidopsis Genome Initiative (2000). Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 408, 796–815. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
