

The ASTRAL Compendium in 2004
- PMID: 14681391
- PMCID: PMC308768
- DOI: 10.1093/nar/gkh034
The ASTRAL Compendium in 2004
Abstract
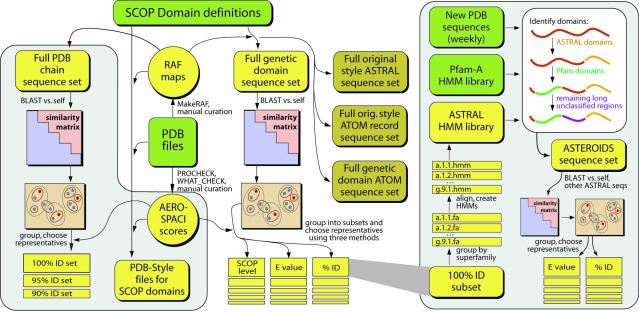
The ASTRAL Compendium provides several databases and tools to aid in the analysis of protein structures, particularly through the use of their sequences. Partially derived from the SCOP database of protein structure domains, it includes sequences for each domain and other resources useful for studying these sequences and domain structures. The current release of ASTRAL contains 54,745 domains, more than three times as many as the initial release 4 years ago. ASTRAL has undergone major transformations in the past 2 years. In addition to several complete updates each year, ASTRAL is now updated on a weekly basis with preliminary classifications of domains from newly released PDB structures. These classifications are available as a stand-alone database, as well as integrated into other ASTRAL databases such as representative subsets. To enhance the utility of ASTRAL to structural biologists, all SCOP domains are now made available as PDB-style coordinate files as well as sequences. In addition to sequences and representative subsets based on SCOP domains, sequences and subsets based on PDB chains are newly included in ASTRAL. Several search tools have been added to ASTRAL to facilitate retrieval of data by individual users and automated methods. ASTRAL may be accessed at http://astral.stanford. edu/.
Figures
References
-
- Murzin A.G., Brenner,S.E., Hubbard,T. and Chothia,C. (1995) SCOP: a structural classification of proteins database for the investigation of sequences and structures. J. Mol. Biol., 247, 536–540. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
