

SURFACE: a database of protein surface regions for functional annotation
- PMID: 14681403
- PMCID: PMC308788
- DOI: 10.1093/nar/gkh054
SURFACE: a database of protein surface regions for functional annotation
Abstract
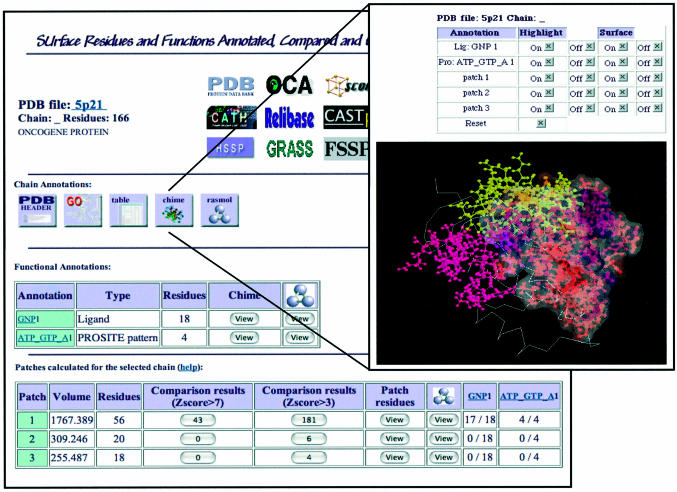
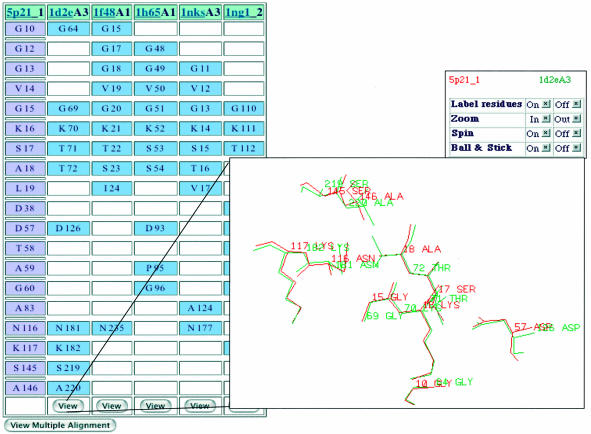
The SURFACE (SUrface Residues and Functions Annotated, Compared and Evaluated, URL http://cbm.bio.uniroma2.it/surface/) database is a repository of annotated and compared protein surface regions. SURFACE contains the results of a large-scale protein annotation and local structural comparison project. A non-redundant set of protein chains is used to build a database of protein surface patches, defined as putative surface functional sites. Each patch is annotated with sequence and structure-derived information about function or interaction abilities. A new procedure for structure comparison is used to perform an all-versus-all patches comparison. Selection of the results obtained with stringent parameters offers a similarity score that can be used to associate different patches and allows reliable annotation by similarity. Annotation exerted through the comparison of regions of protein surface allows the highlighting of similarities that cannot be recognized by other methods of sequence or structure comparison. A graphic representation of the surface patches, functional annotations and the structural superpositions is available through the web interface.
Figures
References
-
- Schmid M.B. (2002) Structural proteomics: the potential of high-throughput structure determination. Trends Microbiol., 10 (Suppl.), S27–S31. - PubMed
-
- Kinoshita K., Furui,J. and Nakamura,H. (2001) Identification of protein functions from a molecular surface database, eF-site. J. Struct. Funct. Genomics, 2, 9–22. - PubMed
-
- Schmitt S., Kuhn,D. and Klebe,G. (2002) A new method to detect related function among proteins independent of sequence and fold homology. J. Mol. Biol., 323, 387–406. - PubMed
-
- Holm L. and Sander,C. (1996) Mapping the protein universe. Science, 273, 595–603. - PubMed
-
- Holm L. and Sander,C. (1997) An evolutionary treasure: unification of a broad set of amidohydrolases related to urease. Proteins, 28, 72–82. - PubMed
