

PlantGDB, plant genome database and analysis tools
- PMID: 14681433
- PMCID: PMC308780
- DOI: 10.1093/nar/gkh046
PlantGDB, plant genome database and analysis tools
Abstract
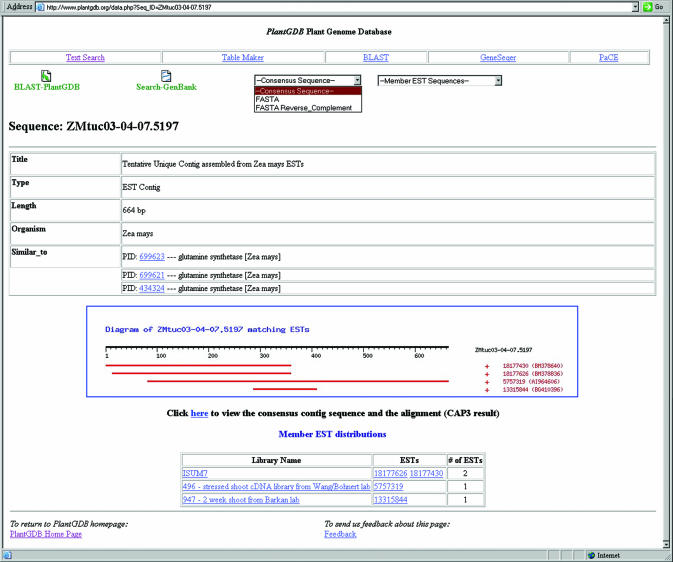
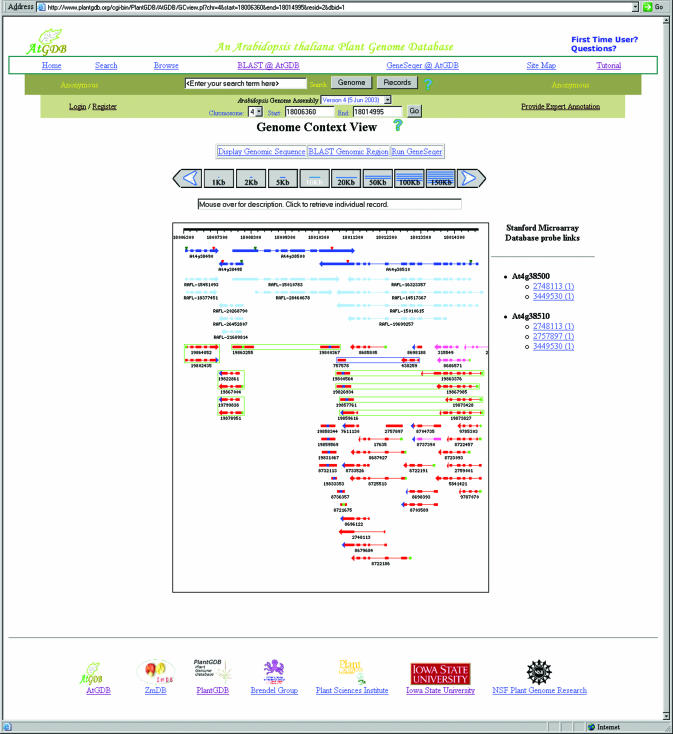
PlantGDB (http://www.plantgdb.org/) is a database of molecular sequence data for all plant species with significant sequencing efforts. The database organizes EST sequences into contigs that represent tentative unique genes. Contigs are annotated and, whenever possible, linked to their respective genomic DNA. Genome sequence fragments are assembled similarly. The goal of the PlantGDB web site is to establish the basis for identifying sets of genes common to all plants or specific to particular species by integrating a number of bioinformatics tools that facilitate gene prediction and cross- species comparisons. For species with large-scale genome sequencing efforts, PlantGDB provides genome browsing capabilities that integrate all available EST and cDNA evidence for current gene models (for Arabidopsis thaliana, see the AtGDB site at http://www.plantgdb.org/AtGDB/).
Figures
References
-
- Fleischmann R.D., Adams,M.D., White,O., Clayton,R.A., Kirkness,E.F., Kerlavage,A.R., Bult,C.J., Tomb,J.F., Dougherty,B.A., Merrick,J.M. et al. (1995) Whole-genome random sequencing and assembly of Haemophilus influenzae Rd. Science, 269, 496–512. - PubMed
-
- Jordan I.K., Rogozin,I.B., Wolf,Y.I. and Koonin,E.V. (2002) Microevolutionary genomics of bacteria. Theor. Popul. Biol., 61, 435–447. - PubMed
-
- The Arabidopsis Genome Initiative (2000) Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature, 408, 796–815. - PubMed
-
- Goff S.A., Ricke,D., Lan,T.-H., Presting,G., Wang,R., Dunn,M., Glazebrook,J., Sessions,A., Oeller,P., Varma,H. et al. (2002) A draft sequence of the rice genome (Oryza sativa L. ssp. japonica). Science, 296, 92–100. - PubMed
-
- Yu J., Hu,S., Wang,J., Wong,G.K.-S., Li,S., Liu,B., Deng,Y., Dai,L., Zhou,Y., Zhang,X. et al. (2002) A draft sequence of the rice genome (Oryza sativa L. ssp. indica). Science, 296, 79–92. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
