

Finding scientific topics
- PMID: 14872004
- PMCID: PMC387300
- DOI: 10.1073/pnas.0307752101
Finding scientific topics
Abstract
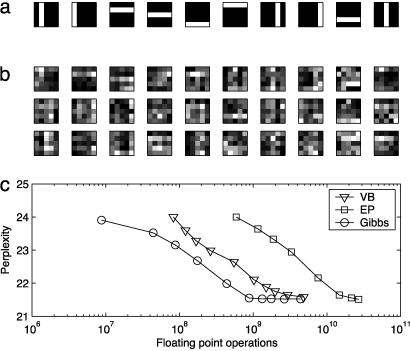
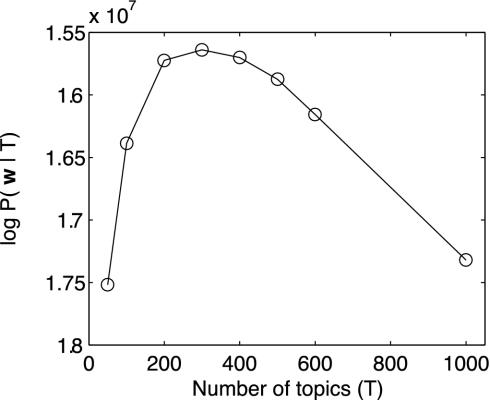
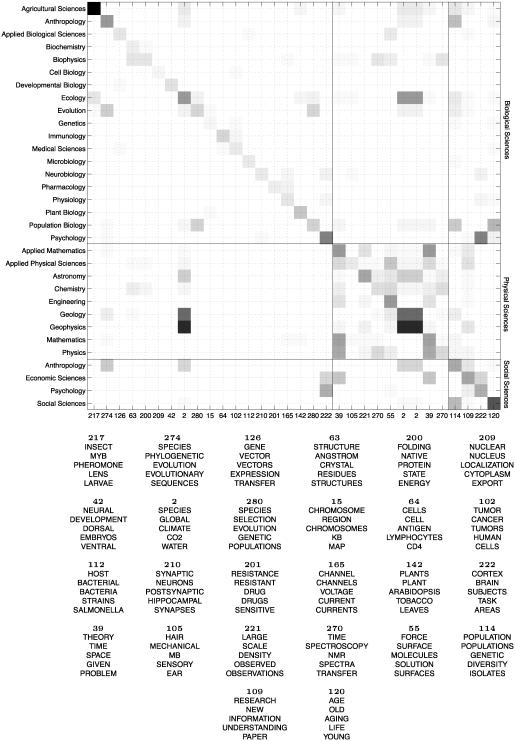
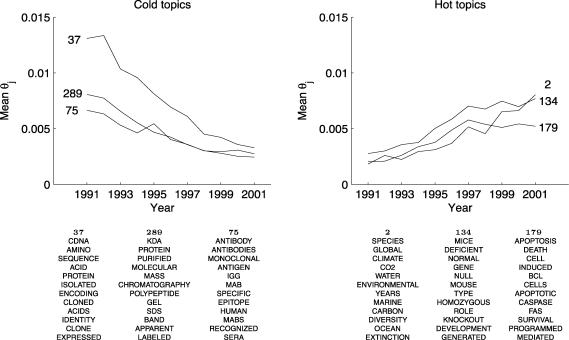
A first step in identifying the content of a document is determining which topics that document addresses. We describe a generative model for documents, introduced by Blei, Ng, and Jordan [Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003) J. Machine Learn. Res. 3, 993-1022], in which each document is generated by choosing a distribution over topics and then choosing each word in the document from a topic selected according to this distribution. We then present a Markov chain Monte Carlo algorithm for inference in this model. We use this algorithm to analyze abstracts from PNAS by using Bayesian model selection to establish the number of topics. We show that the extracted topics capture meaningful structure in the data, consistent with the class designations provided by the authors of the articles, and outline further applications of this analysis, including identifying "hot topics" by examining temporal dynamics and tagging abstracts to illustrate semantic content.
Figures


Similar articles
-
Mapping topics and topic bursts in PNAS.Proc Natl Acad Sci U S A. 2004 Apr 6;101 Suppl 1(Suppl 1):5287-90. doi: 10.1073/pnas.0307626100. Epub 2004 Feb 20. Proc Natl Acad Sci U S A. 2004. PMID: 14978278 Free PMC article.
-
The simultaneous evolution of author and paper networks.Proc Natl Acad Sci U S A. 2004 Apr 6;101 Suppl 1(Suppl 1):5266-73. doi: 10.1073/pnas.0307625100. Epub 2004 Feb 19. Proc Natl Acad Sci U S A. 2004. PMID: 14976254 Free PMC article.
-
Mixed-membership models of scientific publications.Proc Natl Acad Sci U S A. 2004 Apr 6;101 Suppl 1(Suppl 1):5220-7. doi: 10.1073/pnas.0307760101. Epub 2004 Mar 12. Proc Natl Acad Sci U S A. 2004. PMID: 15020766 Free PMC article.
-
Metropolis sampling in pedigree analysis.Stat Methods Med Res. 1993;2(3):263-82. doi: 10.1177/096228029300200305. Stat Methods Med Res. 1993. PMID: 8261261 Review.
-
Basic Bayesian methods.Methods Mol Biol. 2007;404:319-38. doi: 10.1007/978-1-59745-530-5_16. Methods Mol Biol. 2007. PMID: 18450057 Review.
Cited by
-
Synonym, topic model and predicate-based query expansion for retrieving clinical documents.AMIA Annu Symp Proc. 2012;2012:1050-9. Epub 2012 Nov 3. AMIA Annu Symp Proc. 2012. PMID: 23304381 Free PMC article.
-
Language Bias in Health Research: External Factors That Influence Latent Language Patterns.Front Res Metr Anal. 2020 Aug 20;5:4. doi: 10.3389/frma.2020.00004. eCollection 2020. Front Res Metr Anal. 2020. PMID: 33870042 Free PMC article.
-
Decoding the Real-Time Neurobiological Properties of Incremental Semantic Interpretation.Cereb Cortex. 2021 Jan 1;31(1):233-247. doi: 10.1093/cercor/bhaa222. Cereb Cortex. 2021. PMID: 32869058 Free PMC article.
-
On the unsupervised analysis of domain-specific Chinese texts.Proc Natl Acad Sci U S A. 2016 May 31;113(22):6154-9. doi: 10.1073/pnas.1516510113. Epub 2016 May 16. Proc Natl Acad Sci U S A. 2016. PMID: 27185919 Free PMC article.
-
Prediction of complications in diabetes mellitus using machine learning models with transplanted topic model features.Biomed Eng Lett. 2023 Oct 6;14(1):163-171. doi: 10.1007/s13534-023-00322-7. eCollection 2024 Jan. Biomed Eng Lett. 2023. PMID: 38186952 Free PMC article.
References
-
- Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003) J. Machine Learn. Res. 3, 993-1022.
-
- Hofmann, T. (2001) Machine Learn. J. 42, 177-196.
-
- Cohn, D. & Hofmann, T. (2001) in Advances in Neural Information Processing Systems 13 (MIT Press, Cambridge, MA), pp. 430-436.
-
- Iyer, R. & Ostendorf, M. (1996) in Proceedings of the International Conference on Spoken Language Processing (Applied Science & Engineering Laboratories, Alfred I. duPont Inst., Wilmington, DE), Vol 1., pp. 236-239.
-
- Bigi, B., De Mori, R., El-Beze, M. & Spriet, T. (1997) in 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings (IEEE, Piscataway, NJ), pp. 535-542.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
