

Finding scientific topics
- PMID: 14872004
- PMCID: PMC387300
- DOI: 10.1073/pnas.0307752101
Finding scientific topics
Abstract
A first step in identifying the content of a document is determining which topics that document addresses. We describe a generative model for documents, introduced by Blei, Ng, and Jordan [Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003) J. Machine Learn. Res. 3, 993-1022], in which each document is generated by choosing a distribution over topics and then choosing each word in the document from a topic selected according to this distribution. We then present a Markov chain Monte Carlo algorithm for inference in this model. We use this algorithm to analyze abstracts from PNAS by using Bayesian model selection to establish the number of topics. We show that the extracted topics capture meaningful structure in the data, consistent with the class designations provided by the authors of the articles, and outline further applications of this analysis, including identifying "hot topics" by examining temporal dynamics and tagging abstracts to illustrate semantic content.
Figures
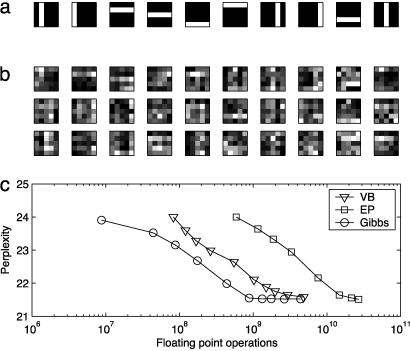

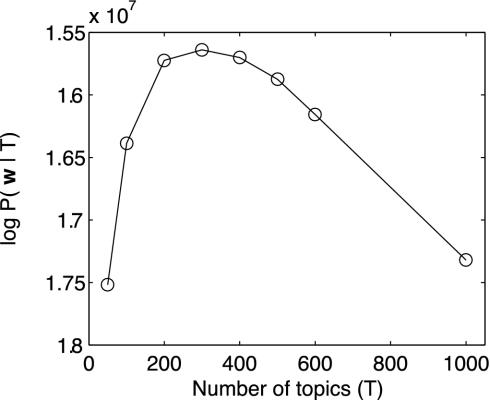
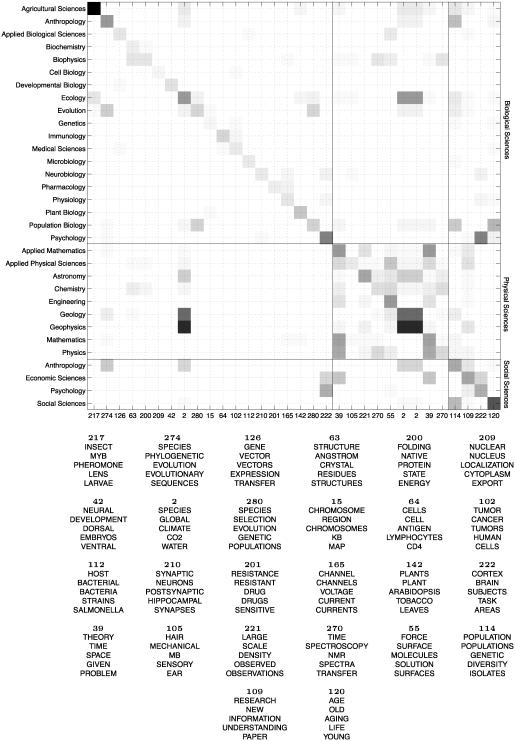
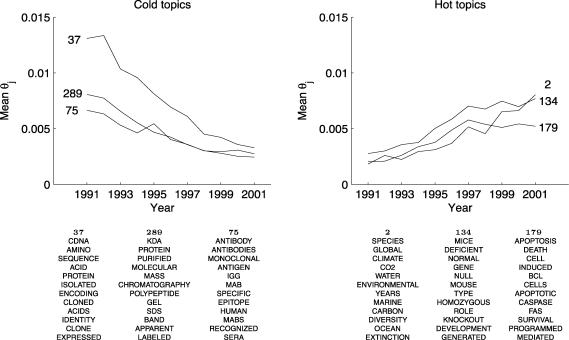

References
-
- Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003) J. Machine Learn. Res. 3, 993-1022.
-
- Hofmann, T. (2001) Machine Learn. J. 42, 177-196.
-
- Cohn, D. & Hofmann, T. (2001) in Advances in Neural Information Processing Systems 13 (MIT Press, Cambridge, MA), pp. 430-436.
-
- Iyer, R. & Ostendorf, M. (1996) in Proceedings of the International Conference on Spoken Language Processing (Applied Science & Engineering Laboratories, Alfred I. duPont Inst., Wilmington, DE), Vol 1., pp. 236-239.
-
- Bigi, B., De Mori, R., El-Beze, M. & Spriet, T. (1997) in 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings (IEEE, Piscataway, NJ), pp. 535-542.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
