

Carbohydrate-binding modules: fine-tuning polysaccharide recognition
- PMID: 15214846
- PMCID: PMC1133952
- DOI: 10.1042/BJ20040892
Carbohydrate-binding modules: fine-tuning polysaccharide recognition
Abstract
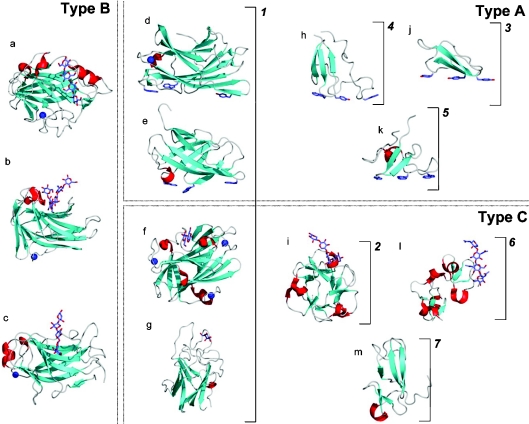
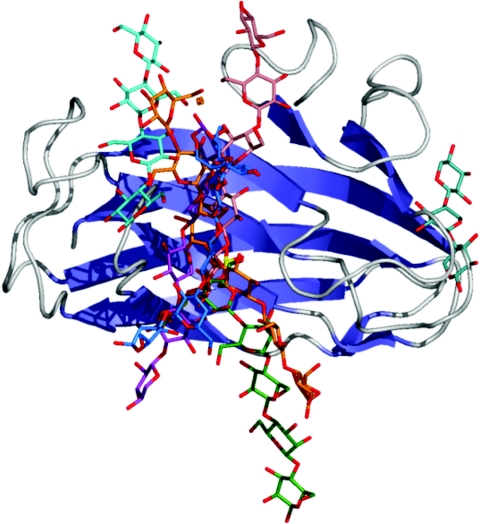
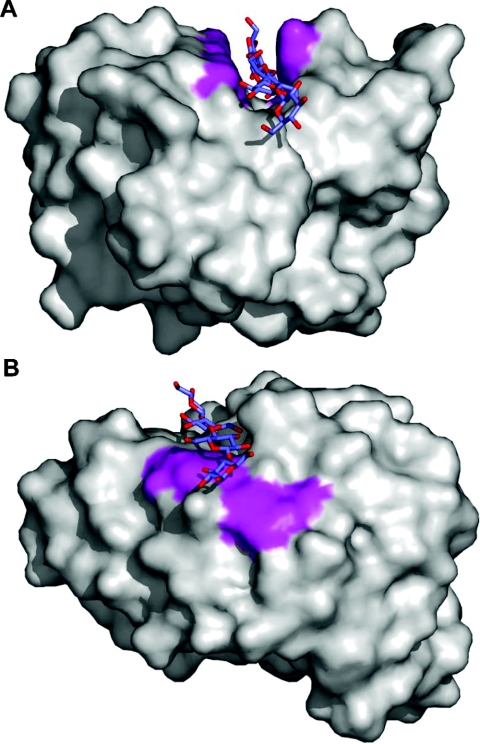
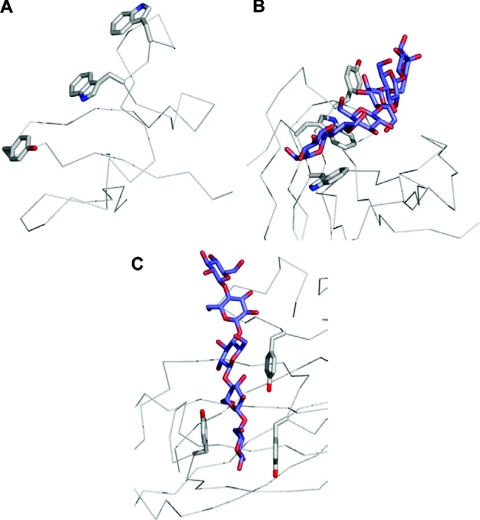
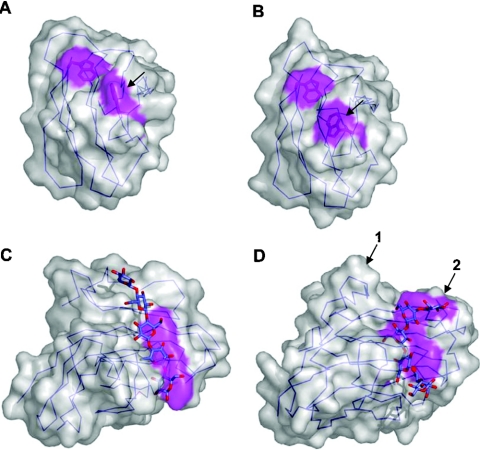
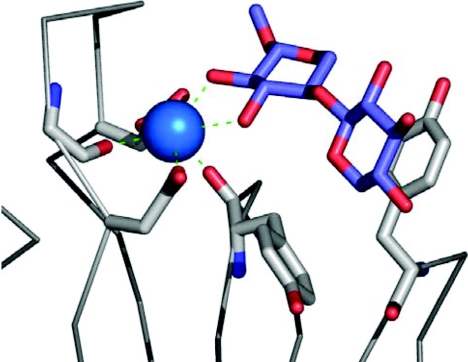
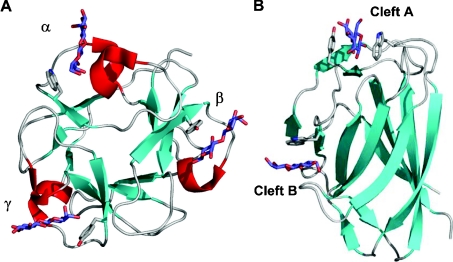
The enzymic degradation of insoluble polysaccharides is one of the most important reactions on earth. Despite this, glycoside hydrolases attack such polysaccharides relatively inefficiently as their target glycosidic bonds are often inaccessible to the active site of the appropriate enzymes. In order to overcome these problems, many of the glycoside hydrolases that utilize insoluble substrates are modular, comprising catalytic modules appended to one or more non-catalytic CBMs (carbohydrate-binding modules). CBMs promote the association of the enzyme with the substrate. In view of the central role that CBMs play in the enzymic hydrolysis of plant structural and storage polysaccharides, the ligand specificity displayed by these protein modules and the mechanism by which they recognize their target carbohydrates have received considerable attention since their discovery almost 20 years ago. In the last few years, CBM research has harnessed structural, functional and bioinformatic approaches to elucidate the molecular determinants that drive CBM-carbohydrate recognition. The present review summarizes the impact structural biology has had on our understanding of the mechanisms by which CBMs bind to their target ligands.
Figures

References
-
- Van Tilbeurgh H., Tomme P., Claeyssens M., Bhikhabhai R., Pettersson G. Limited proteolysis of the cellobiohydrolase I from Trichoderma reesei. FEBS Lett. 1986;204:223–227.
-
- Tomme P., Van Tilbeurgh H., Pettersson G., Van Damme J., Vandekerckhove J., Knowles J., Teeri T., Claeyssens M. Studies of the cellulolytic system of Trichoderma reesei QM 9414: analysis of domain function in two cellobiohydrolases by limited proteolysis. Eur. J. Biochem. 1988;170:575–581. - PubMed
-
- Gilkes N. R., Warren R. A. J., Miller R. C., Jr, Kilburn D. G. Precise excision of the cellulose binding domains from two Cellulomonas fimi cellulases by a homologous protease and the effect on catalysis. J. Biol. Chem. 1988;263:10401–10407. - PubMed
-
- Boraston A. B., McLean B. W., Kormos J. M., Alam M., Gilkes N. R., Haynes C. A., Tomme P., Kilburn D. G., Warren R. A. J. Carbohydrate-binding modules: diversity of structure and function. In: Gilbert H. J., Davies G. J., Henrissat B., Svensson B., editors. Recent Advances in Carbohydrate Bioengineering. Cambridge: Royal Society of Chemistry; 1999. pp. 202–211.
-
- Coutinho P. M., Henrissat B. Carbohydrate-active enzymes: an integrated database approach. In: Gilbert H. J., Davies G. J., Henrissat B., Svensson B., editors. Recent Advances in Carbohydrate Bioengineering. Cambridge: Royal Society of Chemistry; 1999. pp. 3–12.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources