

Comprehensive de novo structure prediction in a systems-biology context for the archaea Halobacterium sp. NRC-1
- PMID: 15287974
- PMCID: PMC507877
- DOI: 10.1186/gb-2004-5-8-r52
Comprehensive de novo structure prediction in a systems-biology context for the archaea Halobacterium sp. NRC-1
Abstract
Background: Large fractions of all fully sequenced genomes code for proteins of unknown function. Annotating these proteins of unknown function remains a critical bottleneck for systems biology and is crucial to understanding the biological relevance of genome-wide changes in mRNA and protein expression, protein-protein and protein-DNA interactions. The work reported here demonstrates that de novo structure prediction is now a viable option for providing general function information for many proteins of unknown function.
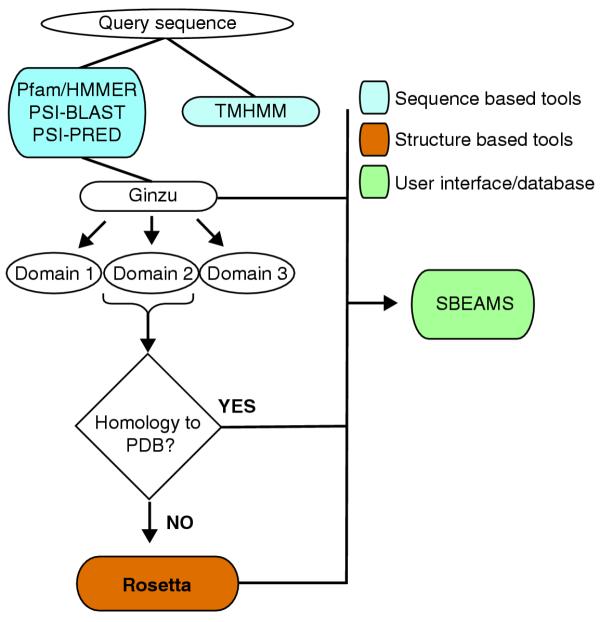
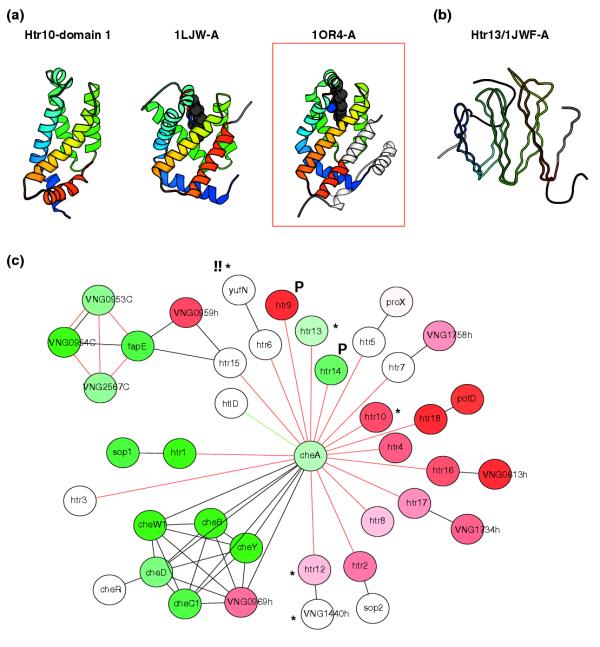
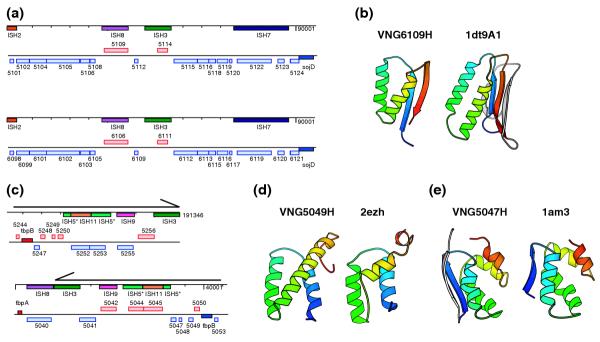
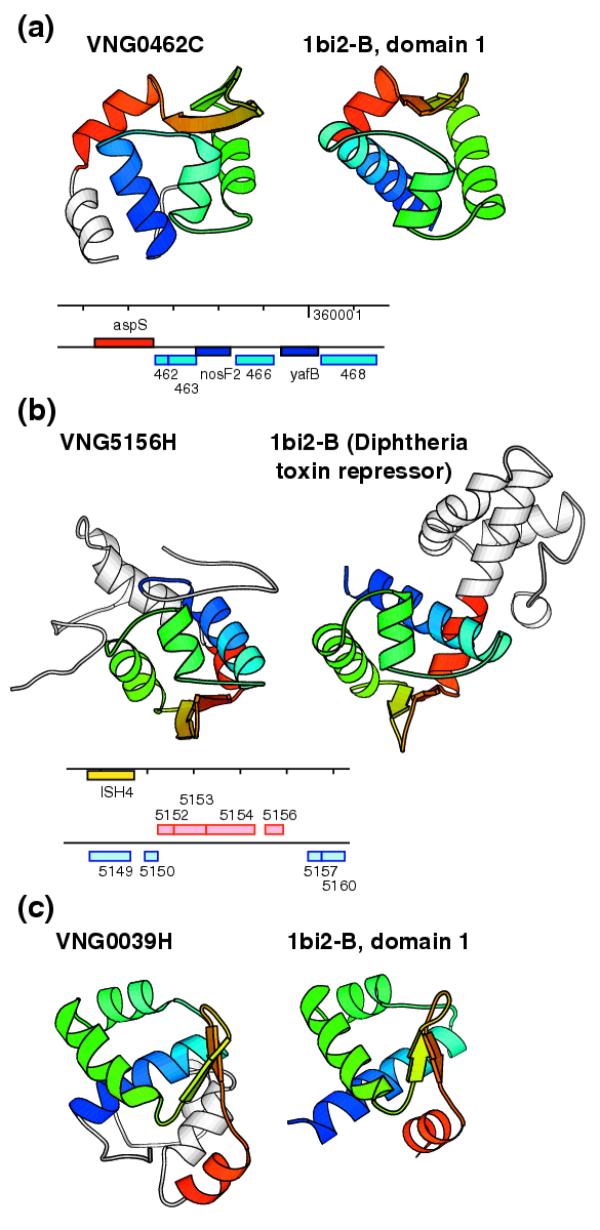
Results: We have used Rosetta de novo structure prediction to predict three-dimensional structures for 1,185 proteins and protein domains (<150 residues in length) found in Halobacterium NRC-1, a widely studied halophilic archaeon. Predicted structures were searched against the Protein Data Bank to identify fold similarities and extrapolate putative functions. They were analyzed in the context of a predicted association network composed of several sources of functional associations such as: predicted protein interactions, predicted operons, phylogenetic profile similarity and domain fusion. To illustrate this approach, we highlight three cases where our combined procedure has provided novel insights into our understanding of chemotaxis, possible prophage remnants in Halobacterium NRC-1 and archaeal transcriptional regulators.
Conclusions: Simultaneous analysis of the association network, coordinated mRNA level changes in microarray experiments and genome-wide structure prediction has allowed us to glean significant biological insights into the roles of several Halobacterium NRC-1 proteins of previously unknown function, and significantly reduce the number of proteins encoded in the genome of this haloarchaeon for which no annotation is available.
Figures
Similar articles
-
Systems level insights into the stress response to UV radiation in the halophilic archaeon Halobacterium NRC-1.Genome Res. 2004 Jun;14(6):1025-35. doi: 10.1101/gr.1993504. Epub 2004 May 12. Genome Res. 2004. PMID: 15140832 Free PMC article.
-
Coordinate regulation of energy transduction modules in Halobacterium sp. analyzed by a global systems approach.Proc Natl Acad Sci U S A. 2002 Nov 12;99(23):14913-8. doi: 10.1073/pnas.192558999. Epub 2002 Oct 28. Proc Natl Acad Sci U S A. 2002. PMID: 12403819 Free PMC article.
-
The Inferelator: an algorithm for learning parsimonious regulatory networks from systems-biology data sets de novo.Genome Biol. 2006;7(5):R36. doi: 10.1186/gb-2006-7-5-r36. Epub 2006 May 10. Genome Biol. 2006. PMID: 16686963 Free PMC article.
-
Protein transport in the halophilic archaeon Halobacterium sp. NRC-1: a major role for the twin-arginine translocation pathway?Microbiology (Reading). 2002 Nov;148(Pt 11):3335-3346. doi: 10.1099/00221287-148-11-3335. Microbiology (Reading). 2002. PMID: 12427925 Review. No abstract available.
-
Regulation of gas vesicle formation in halophilic archaea.J Mol Microbiol Biotechnol. 2002 May;4(3):175-81. J Mol Microbiol Biotechnol. 2002. PMID: 11931543 Review.
Cited by
-
A systems view of haloarchaeal strategies to withstand stress from transition metals.Genome Res. 2006 Jul;16(7):841-54. doi: 10.1101/gr.5189606. Epub 2006 Jun 2. Genome Res. 2006. PMID: 16751342 Free PMC article.
-
Coordination of frontline defense mechanisms under severe oxidative stress.Mol Syst Biol. 2010 Jul;6:393. doi: 10.1038/msb.2010.50. Mol Syst Biol. 2010. PMID: 20664639 Free PMC article.
-
Comparative Analysis of rRNA Removal Methods for RNA-Seq Differential Expression in Halophilic Archaea.Biomolecules. 2022 May 10;12(5):682. doi: 10.3390/biom12050682. Biomolecules. 2022. PMID: 35625610 Free PMC article.
-
Bacterial 'Grounded' Prophages: Hotspots for Genetic Renovation and Innovation.Front Genet. 2019 Feb 12;10:65. doi: 10.3389/fgene.2019.00065. eCollection 2019. Front Genet. 2019. PMID: 30809245 Free PMC article.
-
A role for programmed cell death in the microbial loop.PLoS One. 2013 May 8;8(5):e62595. doi: 10.1371/journal.pone.0062595. Print 2013. PLoS One. 2013. PMID: 23667496 Free PMC article.
References
-
- DasSarma S, Fleischmann EM. Halophiles. Plainview, NY: Cold Spring Harbor Laboratory Press; 1995.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
