

Compound library development guided by protein structure similarity clustering and natural product structure
- PMID: 15548605
- PMCID: PMC534721
- DOI: 10.1073/pnas.0404719101
Compound library development guided by protein structure similarity clustering and natural product structure
Abstract
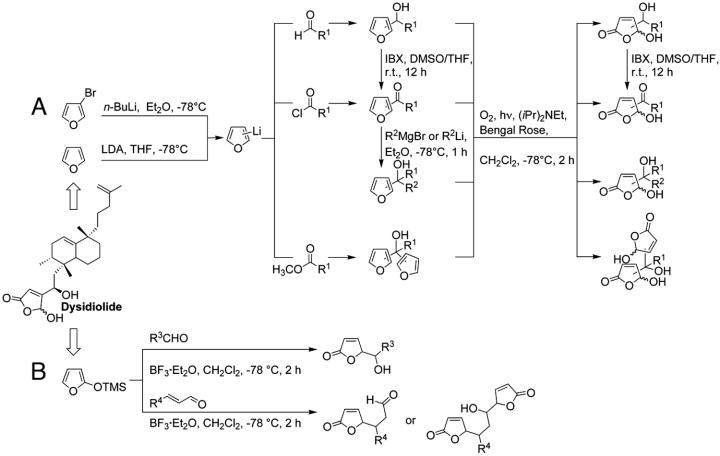
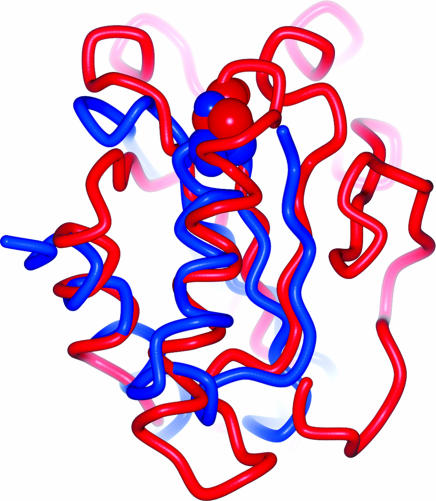
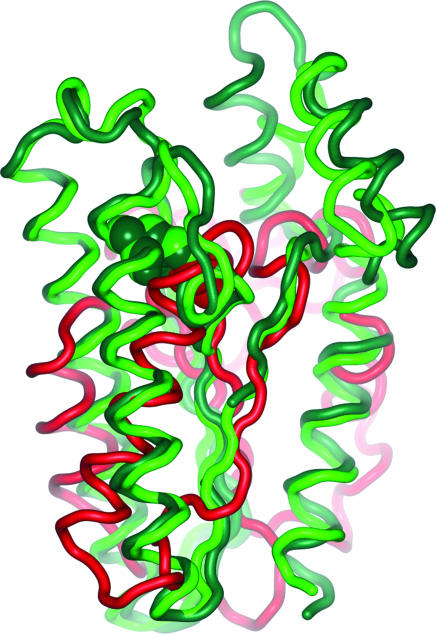
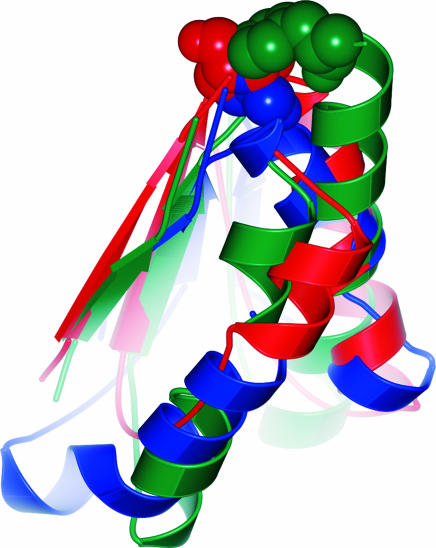
To identify biologically relevant and drug-like protein ligands for medicinal chemistry and chemical biology research the grouping of proteins according to evolutionary relationships and conservation of molecular recognition is an established method. We propose to employ structure similarity clustering of the ligand-sensing cores of protein domains (PSSC) in conjunction with natural product guided compound library development as a synergistic approach for the identification of biologically prevalidated ligands with high fidelity. This is supported by the concepts that (i) in nature spatial structure is more conserved than amino acid sequence, (ii) the number of fold types characteristic for all protein domains is limited, and (iii) the underlying frameworks of natural product classes with multiple biological activities provide evolutionarily selected starting points in structural space. On the basis of domain core similarity considerations and irrespective of sequence similarity, Cdc25A phosphatase, acetylcholinesterase, and 11beta-hydroxysteroid dehydrogenases type 1 and type 2 were grouped into a similarity cluster. A 147-member compound collection derived from the naturally occurring Cdc25A inhibitor dysidiolide yielded potent and selective inhibitors of the other members of the similarity cluster with a hit rate of 2-3%. Protein structure similarity clustering may provide an experimental opportunity to identify supersites in proteins.
Figures

Similar articles
-
Design of compound libraries based on natural product scaffolds and protein structure similarity clustering (PSSC).Mol Biosyst. 2005 May;1(1):36-45. doi: 10.1039/b503623b. Epub 2005 Apr 19. Mol Biosyst. 2005. PMID: 16880961 Review.
-
Bioactivity-guided navigation of chemical space.Acc Chem Res. 2010 Aug 17;43(8):1103-14. doi: 10.1021/ar100014h. Acc Chem Res. 2010. PMID: 20481515
-
Protein structure similarity clustering (PSSC) and natural product structure as inspiration sources for drug development and chemical genomics.Curr Opin Chem Biol. 2005 Jun;9(3):232-9. doi: 10.1016/j.cbpa.2005.03.003. Curr Opin Chem Biol. 2005. PMID: 15939324 Review.
-
Protein structure similarity clustering and natural product structure as guiding principles for chemical genomics.Ernst Schering Res Found Workshop. 2006;(58):89-109. doi: 10.1007/978-3-540-37635-4_7. Ernst Schering Res Found Workshop. 2006. PMID: 16709001 Review.
-
Protein structure similarity clustering and natural product structure as guiding principles in drug discovery.Drug Discov Today. 2005 Apr 1;10(7):471-83. doi: 10.1016/S1359-6446(05)03419-7. Drug Discov Today. 2005. PMID: 15809193 Review.
Cited by
-
Mouse 11β-hydroxysteroid dehydrogenase type 2 for human application: homology modeling, structural analysis and ligand-receptor interaction.Cancer Inform. 2011;10:287-95. doi: 10.4137/CIN.S8725. Epub 2011 Dec 1. Cancer Inform. 2011. PMID: 22174566 Free PMC article.
-
The Time and Place for Nature in Drug Discovery.JACS Au. 2022 Oct 14;2(11):2400-2416. doi: 10.1021/jacsau.2c00415. eCollection 2022 Nov 28. JACS Au. 2022. PMID: 36465532 Free PMC article. Review.
-
Small molecule macroarray construction via palladium-mediated carbon-carbon bond-forming reactions: highly efficient synthesis and screening of stilbene arrays.Chemistry. 2010 Mar 1;16(9):2692-5. doi: 10.1002/chem.200903445. Chemistry. 2010. PMID: 20135652 Free PMC article. No abstract available.
-
1,4-Dihydropyridine derivatives with T-type calcium channel blocking activity attenuate inflammatory and neuropathic pain.Pflugers Arch. 2015 Jun;467(6):1237-47. doi: 10.1007/s00424-014-1566-3. Epub 2014 Jul 3. Pflugers Arch. 2015. PMID: 24990197
-
CATS: A Tool for Clustering the Ensemble of Intrinsically Disordered Peptides on a Flat Energy Landscape.J Phys Chem B. 2018 Dec 13;122(49):11807-11816. doi: 10.1021/acs.jpcb.8b08852. Epub 2018 Nov 7. J Phys Chem B. 2018. PMID: 30362738 Free PMC article.
References
-
- Breinbauer, R., Vetter, I. R. & Waldmann, H. (2002) Angew. Chem. Int. Ed. 41, 2878–2890. - PubMed
-
- Koch, M. A., Breinbauer, R. & Waldmann, H. (2003) Biol. Chem. 384, 1265–1272. - PubMed
-
- Walters, W. P., Ajay & Murcko, M. A. (1999) Curr. Opin. Chem. Biol. 3, 384–387. - PubMed
-
- Ajay, Walters, W. P. & Murcko, M. A. (1998) J. Med. Chem. 41, 3314–3324. - PubMed
-
- Sadowski, J. & Kubinyi, H. (1998) J. Med. Chem. 41, 3325–3329. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
