

Protein-mediated error correction for de novo DNA synthesis
- PMID: 15561997
- PMCID: PMC534640
- DOI: 10.1093/nar/gnh160
Protein-mediated error correction for de novo DNA synthesis
Abstract
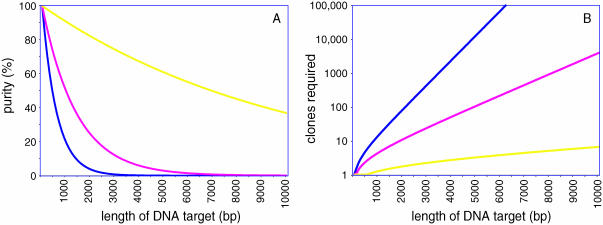
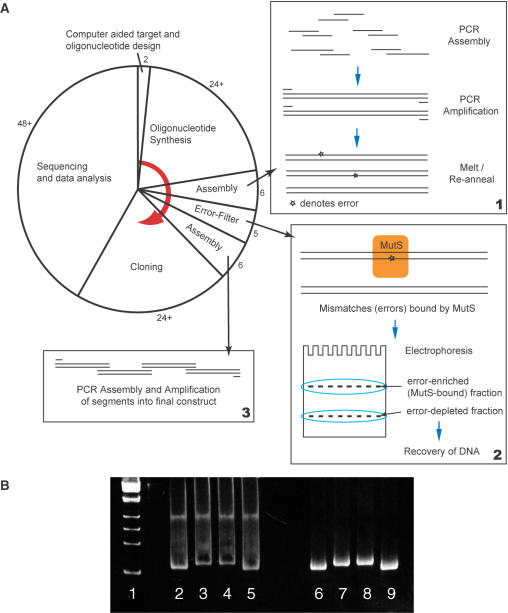
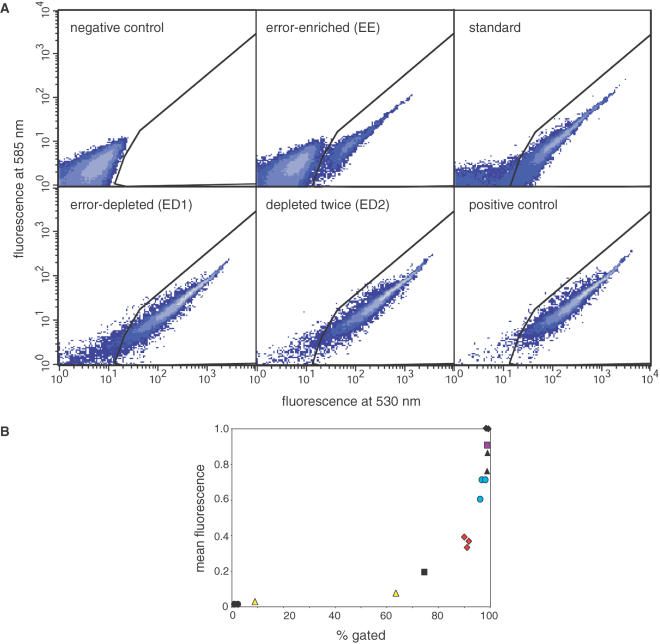
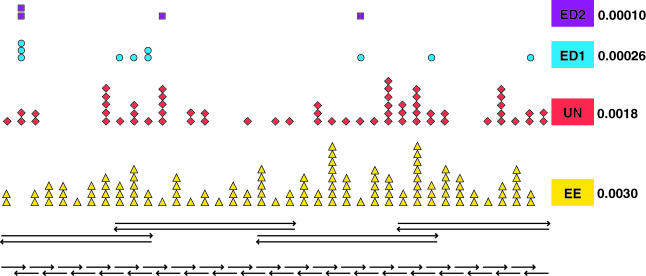
The availability of inexpensive, on demand synthetic DNA has enabled numerous powerful applications in biotechnology, in turn driving considerable present interest in the de novo synthesis of increasingly longer DNA constructs. The synthesis of DNA from oligonucleotides into products even as large as small viral genomes has been accomplished. Despite such achievements, the costs and time required to generate such long constructs has, to date, precluded gene-length (and longer) DNA synthesis from being an everyday research tool in the same manner as PCR and DNA sequencing. A critical barrier to low-cost, high-throughput de novo DNA synthesis is the frequency at which errors pervade the final product. Here, we employ a DNA mismatch-binding protein, MutS (from Thermus aquaticus) to remove failure products from synthetic genes. This method reduced errors by >15-fold relative to conventional gene synthesis techniques, yielding DNA with one error per 10 000 base pairs. The approach is general, scalable and can be iterated multiple times for greater fidelity. Reductions in both costs and time required are demonstrated for the synthesis of a 2.5 kb gene.
Figures
References
-
- Khorana H.G. (1968) Nucleic acid synthesis in the study of the genetic code, in Nobel Lectures: Physiology or Medicine (1963–1970). Elsevier Science Ltd, Amsterdam, pp. 341–369.
-
- Agarwal K.L., Buchi,H., Caruthers,M.H., Gupta,N., Khorana,H.G., Kleppe,K., Kumar,A., Ohtsuka,E., Rajbhandary,U.L., Van de Sande,J.H. et al. (1974) Total synthesis of the gene for an alanine transfer ribonucleic acid from yeast. Nature, 227, 27–34. - PubMed
-
- Venter J.C., Adams,M.D., Myers,E.W., Li,P.W., Mural,R.J., Sutton,G.G., Smith,H.O., Yandell,M., Evans,C.A., Holt,R.A. et al. (2001) The sequence of the human genome. Science, 291, 1304–1351. - PubMed
-
- Lander E.S., Linton,L.M., Birren,B., Nusbaum,C., Zody,M.C., Baldwin,J., Devon,K., Dewar,K., Doyle,M., FitzHugh,W. et al. (2001) Initial sequencing and analysis of the human genome. Nature, 409, 860–921. - PubMed
-
- Kleppe K., Ohtsuka,E., Kleppe,R., Molineux,I. and Khorana,H.G. (1971) Studies on polynucleotides. XCVI. Repair replications of short synthetic DNA's as catalyzed by DNA polymerases. J. Mol. Biol., 56, 341–361. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
