

STRING: known and predicted protein-protein associations, integrated and transferred across organisms
- PMID: 15608232
- PMCID: PMC539959
- DOI: 10.1093/nar/gki005
STRING: known and predicted protein-protein associations, integrated and transferred across organisms
Abstract
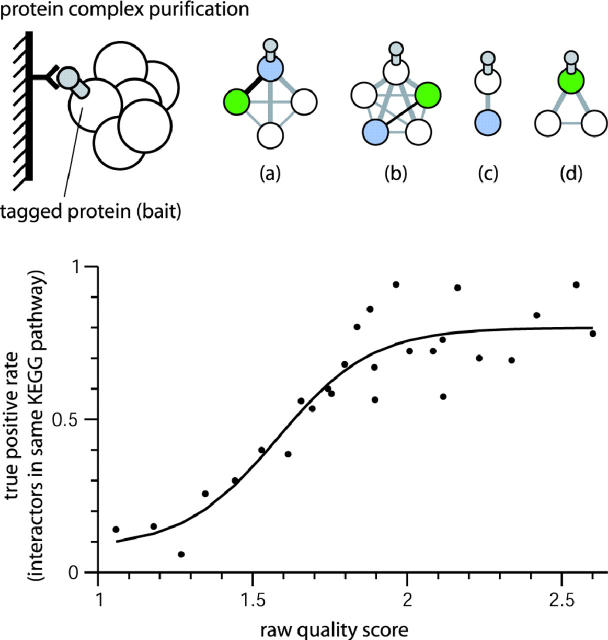
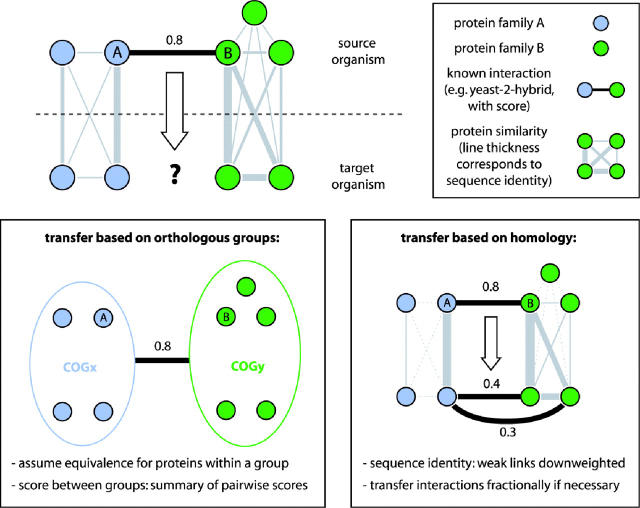
A full description of a protein's function requires knowledge of all partner proteins with which it specifically associates. From a functional perspective, 'association' can mean direct physical binding, but can also mean indirect interaction such as participation in the same metabolic pathway or cellular process. Currently, information about protein association is scattered over a wide variety of resources and model organisms. STRING aims to simplify access to this information by providing a comprehensive, yet quality-controlled collection of protein-protein associations for a large number of organisms. The associations are derived from high-throughput experimental data, from the mining of databases and literature, and from predictions based on genomic context analysis. STRING integrates and ranks these associations by benchmarking them against a common reference set, and presents evidence in a consistent and intuitive web interface. Importantly, the associations are extended beyond the organism in which they were originally described, by automatic transfer to orthologous protein pairs in other organisms, where applicable. STRING currently holds 730,000 proteins in 180 fully sequenced organisms, and is available at http://string.embl.de/.
Figures

References
-
- Zanzoni A., Montecchi-Palazzi,L., Quondam,M., Ausiello,G., Helmer-Citterich,M. and Cesareni,G. (2002) MINT: a Molecular INTeraction database. FEBS Lett., 513, 135–140. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
