

Clustering the annotation space of proteins
- PMID: 15703069
- PMCID: PMC552314
- DOI: 10.1186/1471-2105-6-24
Clustering the annotation space of proteins
Abstract
Background: Current protein clustering methods rely on either sequence or functional similarities between proteins, thereby limiting inferences to one of these areas.
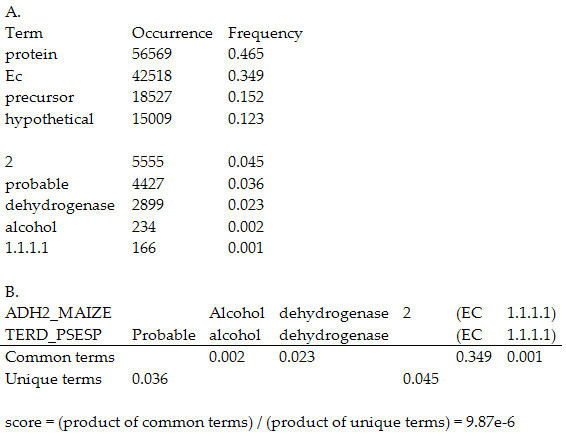
Results: Here we report a new approach, named CLAN, which clusters proteins according to both annotation and sequence similarity. This approach is extremely fast, clustering the complete SwissProt database within minutes. It is also accurate, recovering consistent protein families agreeing on average in more than 97% with sequence-based protein families from Pfam. Discrepancies between sequence- and annotation-based clusters were scrutinized and the reasons reported. We demonstrate examples for each of these cases, and thoroughly discuss an example of a propagated error in SwissProt: a vacuolar ATPase subunit M9.2 erroneously annotated as vacuolar ATP synthase subunit H. CLAN algorithm is available from the authors and the CLAN database is accessible at http://maine.ebi.ac.uk:8000/cgi-bin/clan/ClanSearch.pl
Conclusions: CLAN creates refined function-and-sequence specific protein families that can be used for identification and annotation of unknown family members. It also allows easy identification of erroneous annotations by spotting inconsistencies between similarities on annotation and sequence levels.
Figures
Similar articles
-
MILANO--custom annotation of microarray results using automatic literature searches.BMC Bioinformatics. 2005 Jan 20;6:12. doi: 10.1186/1471-2105-6-12. BMC Bioinformatics. 2005. PMID: 15661078 Free PMC article.
-
Predicting functional sites with an automated algorithm suitable for heterogeneous datasets.BMC Bioinformatics. 2005 May 13;6:116. doi: 10.1186/1471-2105-6-116. BMC Bioinformatics. 2005. PMID: 15890082 Free PMC article.
-
Automatic annotation of protein function based on family identification.Proteins. 2003 Nov 15;53(3):683-92. doi: 10.1002/prot.10449. Proteins. 2003. PMID: 14579359
-
The CATH protein family database: a resource for structural and functional annotation of genomes.Proteomics. 2002 Jan;2(1):11-21. Proteomics. 2002. PMID: 11788987 Review.
-
Evolutionary families of peptidase inhibitors.Biochem J. 2004 Mar 15;378(Pt 3):705-16. doi: 10.1042/BJ20031825. Biochem J. 2004. PMID: 14705960 Free PMC article. Review.
Cited by
-
BLANNOTATOR: enhanced homology-based function prediction of bacterial proteins.BMC Bioinformatics. 2012 Feb 15;13:33. doi: 10.1186/1471-2105-13-33. BMC Bioinformatics. 2012. PMID: 22335941 Free PMC article.
-
Annotation inconsistencies beyond sequence similarity-based function prediction - phylogeny and genome structure.Stand Genomic Sci. 2015 Nov 19;10:108. doi: 10.1186/s40793-015-0101-2. eCollection 2015. Stand Genomic Sci. 2015. PMID: 26594309 Free PMC article.
-
Cluster analysis of protein array results via similarity of Gene Ontology annotation.BMC Bioinformatics. 2006 Jul 12;7:338. doi: 10.1186/1471-2105-7-338. BMC Bioinformatics. 2006. PMID: 16836750 Free PMC article.
-
Novel knowledge-based mean force potential at the profile level.BMC Bioinformatics. 2006 Jun 27;7:324. doi: 10.1186/1471-2105-7-324. BMC Bioinformatics. 2006. PMID: 16803615 Free PMC article.
-
A bioinformatician's guide to metagenomics.Microbiol Mol Biol Rev. 2008 Dec;72(4):557-78, Table of Contents. doi: 10.1128/MMBR.00009-08. Microbiol Mol Biol Rev. 2008. PMID: 19052320 Free PMC article. Review.
References
-
- Yandell MD, Majoros WH. Genomics and natural language processing. Nat Rev Genet. 2002;3:601–10. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
