

PSSM-based prediction of DNA binding sites in proteins
- PMID: 15720719
- PMCID: PMC550660
- DOI: 10.1186/1471-2105-6-33
PSSM-based prediction of DNA binding sites in proteins
Abstract
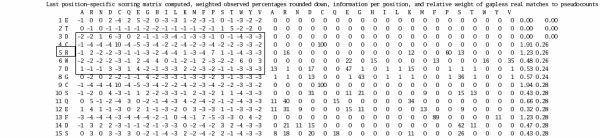
Background: Detection of DNA-binding sites in proteins is of enormous interest for technologies targeting gene regulation and manipulation. We have previously shown that a residue and its sequence neighbor information can be used to predict DNA-binding candidates in a protein sequence. This sequence-based prediction method is applicable even if no sequence homology with a previously known DNA-binding protein is observed. Here we implement a neural network based algorithm to utilize evolutionary information of amino acid sequences in terms of their position specific scoring matrices (PSSMs) for a better prediction of DNA-binding sites.
Results: An average of sensitivity and specificity using PSSMs is up to 8.7% better than the prediction with sequence information only. Much smaller data sets could be used to generate PSSM with minimal loss of prediction accuracy.
Conclusion: One problem in using PSSM-derived prediction is obtaining lengthy and time-consuming alignments against large sequence databases. In order to speed up the process of generating PSSMs, we tried to use different reference data sets (sequence space) against which a target protein is scanned for PSI-BLAST iterations. We find that a very small set of proteins can actually be used as such a reference data without losing much of the prediction value. This makes the process of generating PSSMs very rapid and even amenable to be used at a genome level. A web server has been developed to provide these predictions of DNA-binding sites for any new protein from its amino acid sequence.
Availability: Online predictions based on this method are available at http://www.netasa.org/dbs-pssm/
Figures

References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
