

Columba: an integrated database of proteins, structures, and annotations
- PMID: 15801979
- PMCID: PMC1087474
- DOI: 10.1186/1471-2105-6-81
Columba: an integrated database of proteins, structures, and annotations
Abstract
Background: Structural and functional research often requires the computation of sets of protein structures based on certain properties of the proteins, such as sequence features, fold classification, or functional annotation. Compiling such sets using current web resources is tedious because the necessary data are spread over many different databases. To facilitate this task, we have created COLUMBA, an integrated database of annotations of protein structures.
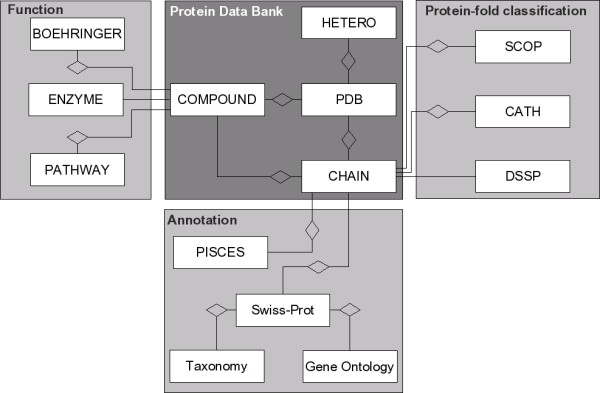
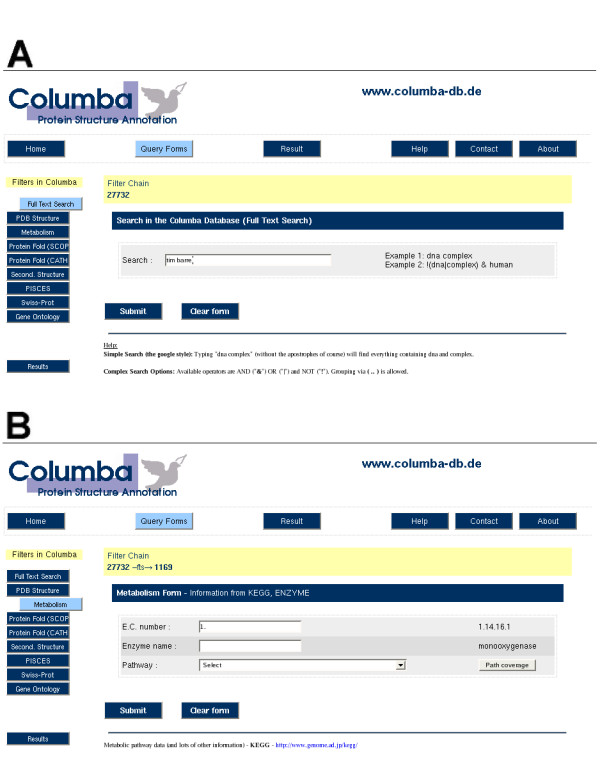
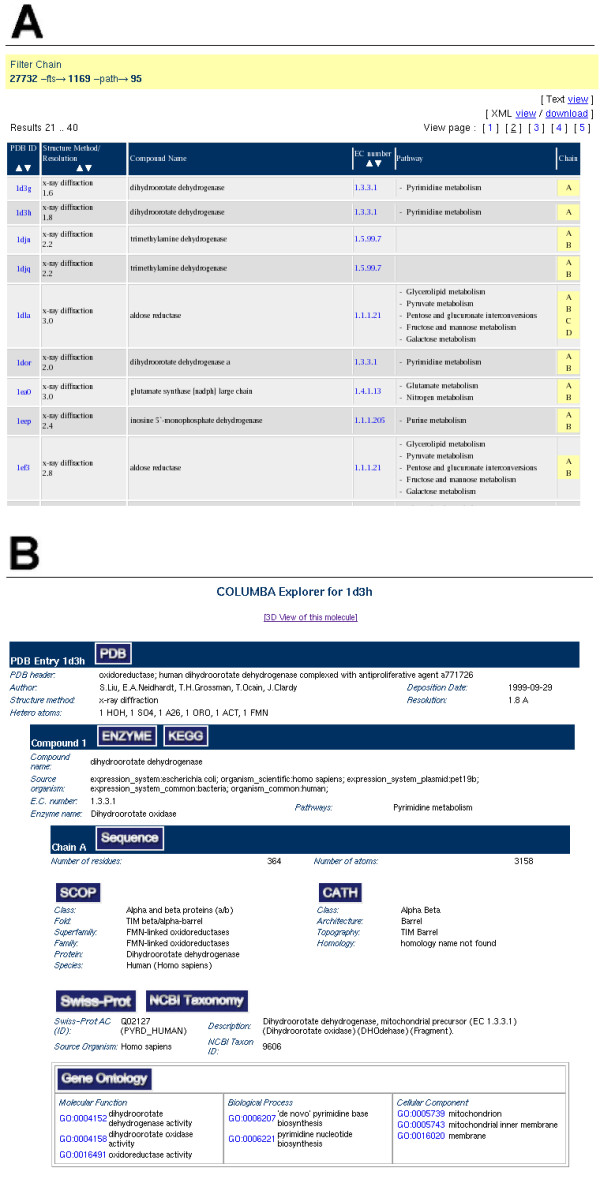
Description: COLUMBA currently integrates twelve different databases, including PDB, KEGG, Swiss-Prot, CATH, SCOP, the Gene Ontology, and ENZYME. The database can be searched using either keyword search or data source-specific web forms. Users can thus quickly select and download PDB entries that, for instance, participate in a particular pathway, are classified as containing a certain CATH architecture, are annotated as having a certain molecular function in the Gene Ontology, and whose structures have a resolution under a defined threshold. The results of queries are provided in both machine-readable extensible markup language and human-readable format. The structures themselves can be viewed interactively on the web.
Conclusion: The COLUMBA database facilitates the creation of protein structure data sets for many structure-based studies. It allows to combine queries on a number of structure-related databases not covered by other projects at present. Thus, information on both many and few protein structures can be used efficiently. The web interface for COLUMBA is available at http://www.columba-db.de.
Figures
Similar articles
-
METIS: multiple extraction techniques for informative sentences.Bioinformatics. 2005 Nov 15;21(22):4196-7. doi: 10.1093/bioinformatics/bti675. Epub 2005 Sep 13. Bioinformatics. 2005. PMID: 16159915
-
Mapping PDB chains to UniProtKB entries.Bioinformatics. 2005 Dec 1;21(23):4297-301. doi: 10.1093/bioinformatics/bti694. Epub 2005 Sep 27. Bioinformatics. 2005. PMID: 16188924
-
Atlas - a data warehouse for integrative bioinformatics.BMC Bioinformatics. 2005 Feb 21;6:34. doi: 10.1186/1471-2105-6-34. BMC Bioinformatics. 2005. PMID: 15723693 Free PMC article.
-
LinkHub: a Semantic Web system that facilitates cross-database queries and information retrieval in proteomics.BMC Bioinformatics. 2007 May 9;8 Suppl 3(Suppl 3):S5. doi: 10.1186/1471-2105-8-S3-S5. BMC Bioinformatics. 2007. PMID: 17493288 Free PMC article. Review.
-
Automation of in-silico data analysis processes through workflow management systems.Brief Bioinform. 2008 Jan;9(1):57-68. doi: 10.1093/bib/bbm056. Epub 2007 Dec 2. Brief Bioinform. 2008. PMID: 18056132 Review.
Cited by
-
SuperMimic--fitting peptide mimetics into protein structures.BMC Bioinformatics. 2006 Jan 10;7:11. doi: 10.1186/1471-2105-7-11. BMC Bioinformatics. 2006. PMID: 16403211 Free PMC article.
-
BIOZON: a system for unification, management and analysis of heterogeneous biological data.BMC Bioinformatics. 2006 Feb 15;7:70. doi: 10.1186/1471-2105-7-70. BMC Bioinformatics. 2006. PMID: 16480510 Free PMC article.
-
TAGOPSIN: collating taxa-specific gene and protein functional and structural information.BMC Bioinformatics. 2021 Oct 23;22(1):517. doi: 10.1186/s12859-021-04429-5. BMC Bioinformatics. 2021. PMID: 34688246 Free PMC article.
-
GenoQuery: a new querying module for functional annotation in a genomic warehouse.Bioinformatics. 2008 Jul 1;24(13):i322-9. doi: 10.1093/bioinformatics/btn159. Bioinformatics. 2008. PMID: 18586731 Free PMC article.
-
Variant information systems for precision oncology.BMC Med Inform Decis Mak. 2018 Nov 21;18(1):107. doi: 10.1186/s12911-018-0665-z. BMC Med Inform Decis Mak. 2018. PMID: 30463544 Free PMC article.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
