

BioCreAtIvE task1A: entity identification with a stochastic tagger
- PMID: 15960838
- PMCID: PMC1869018
- DOI: 10.1186/1471-2105-6-S1-S4
BioCreAtIvE task1A: entity identification with a stochastic tagger
Abstract
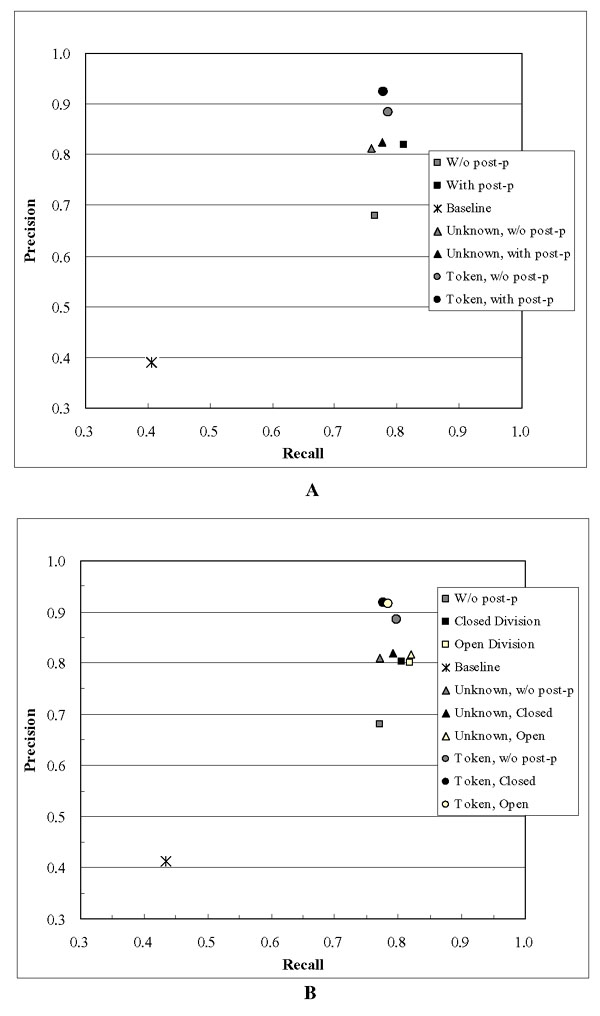
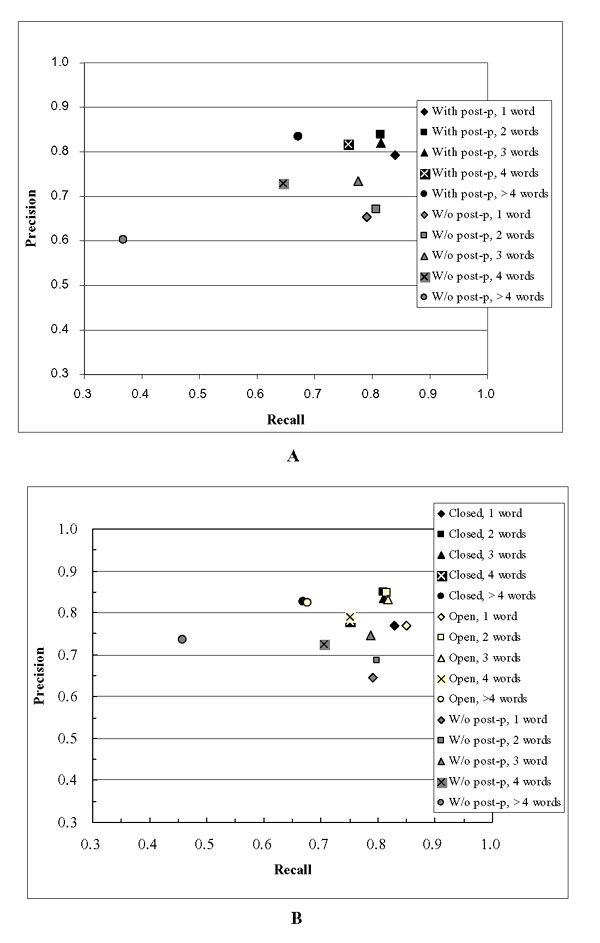
Background: Our approach to Task 1A was inspired by Tanabe and Wilbur's ABGene system. Like Tanabe and Wilbur, we approached the problem as one of part-of-speech tagging, adding a GENE tag to the standard tag set. Where their system uses the Brill tagger, we used TnT, the Trigrams 'n' Tags HMM-based part-of-speech tagger. Based on careful error analysis, we implemented a set of post-processing rules to correct both false positives and false negatives. We participated in both the open and the closed divisions; for the open division, we made use of data from NCBI.
Results: Our base system without post-processing achieved a precision and recall of 68.0% and 77.2%, respectively, giving an F-measure of 72.3%. The full system with post-processing achieved a precision and recall of 80.3% and 80.5% giving an F-measure of 80.4%. We achieved a slight improvement (F-measure = 80.9%) by employing a dictionary-based post-processing step for the open division. We placed third in both the open and the closed division.
Conclusion: Our results show that a part-of-speech tagger can be augmented with post-processing rules resulting in an entity identification system that competes well with other approaches.
Figures
References
-
- Tanabe L, Wilbur WJ. Tagging gene and protein names in full text articles. Proceedings of the workshop on biomedical natural language processing in the biomedical domain Association for Computational Linguistics. 2002. pp. 9–13.
-
- Brants T. TnT – A Statistical Part-of-Speech Tagger. Proceedings of the Sixth Applied Natural Language Processing Conference (ANLP-2000)
-
- Fukuda K, Tsunoda T, Tamura A, Takagi T. Toward information extraction: identifying protein names from biological papers. Pacific Symposium for Biocomputing. 1998;3:705–716. - PubMed
-
- Fredrik O, Eriksson G, Franzén K, Asker L, Lidén P. Notions of correctness when evaluating protein name taggers. Proceedings of the 19th International Conference on Computational Linguistics (COLING 2002) pp. 765–771.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
