PAT: a protein analysis toolkit for integrated biocomputing on the web
- PMID: 15980554
- PMCID: PMC1160216
- DOI: 10.1093/nar/gki455
PAT: a protein analysis toolkit for integrated biocomputing on the web
Abstract
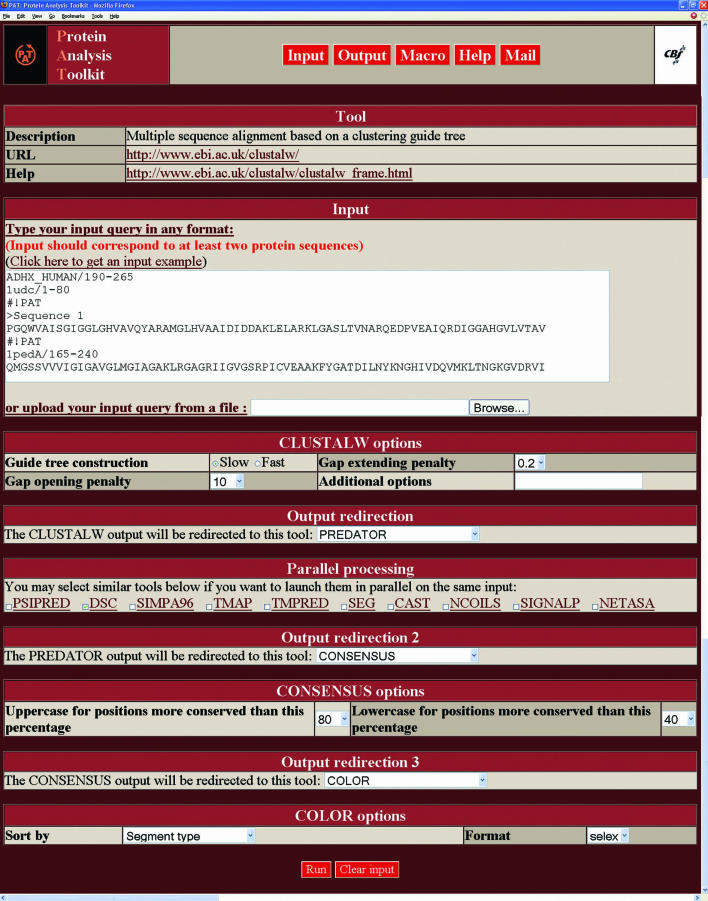
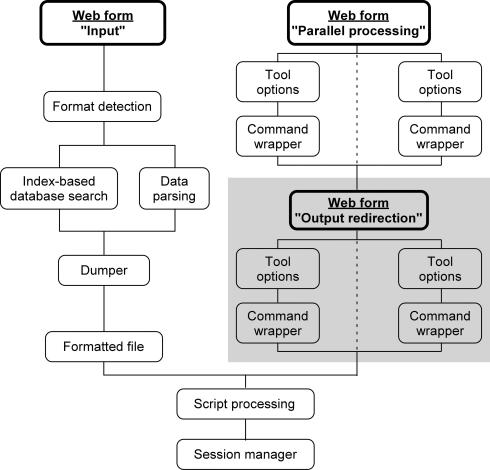
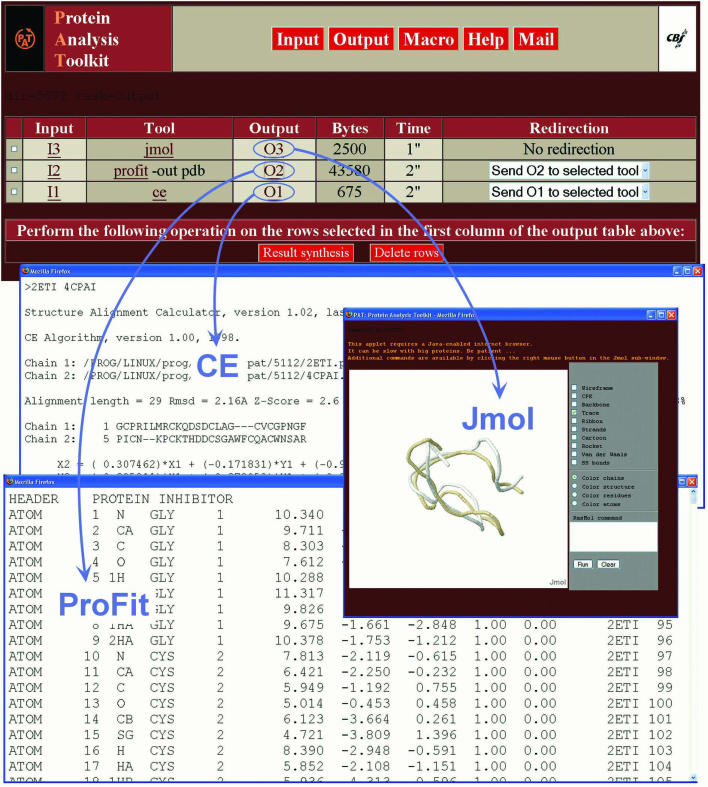
PAT, for Protein Analysis Toolkit, is an integrated biocomputing server. The main goal of its design was to facilitate the combination of different processing tools for complex protein analyses and to simplify the automation of repetitive tasks. The PAT server provides a standardized web interface to a wide range of protein analysis tools. It is designed as a streamlined analysis environment that implements many features which strongly simplify studies dealing with protein sequences and structures and improve productivity. PAT is able to read and write data in many bioinformatics formats and to create any desired pipeline by seamlessly sending the output of a tool to the input of another tool. PAT can retrieve protein entries from identifier-based queries by using pre-computed database indexes. Users can easily formulate complex queries combining different analysis tools with few mouse clicks, or via a dedicated macro language, and a web session manager provides direct access to any temporary file generated during the user session. PAT is freely accessible on the Internet at http://pat.cbs.cnrs.fr.
Figures