

A surprisingly large RNase P RNA in Candida glabrata
- PMID: 15987816
- PMCID: PMC1370791
- DOI: 10.1261/rna.2130705
A surprisingly large RNase P RNA in Candida glabrata
Abstract
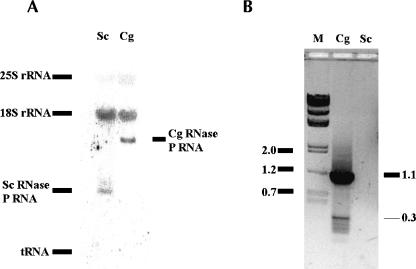
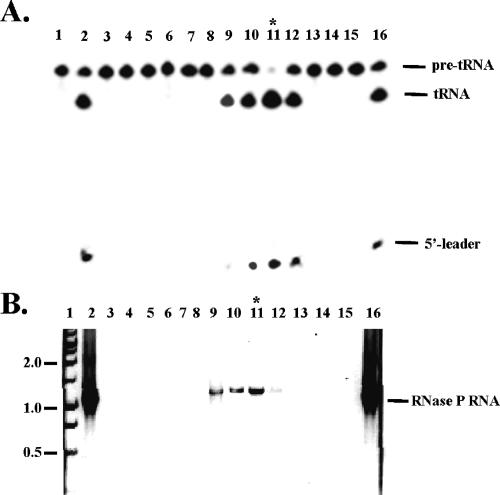
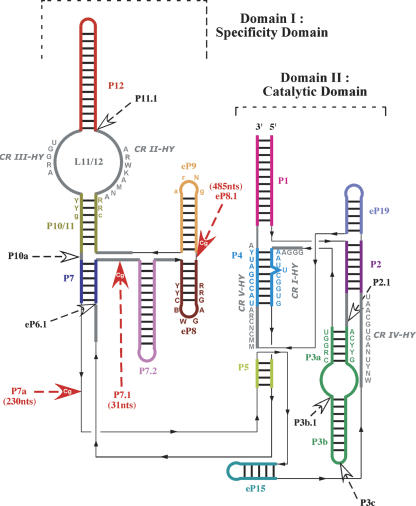
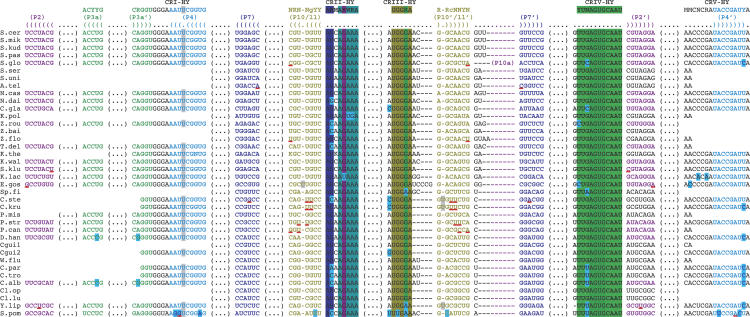
We have found an extremely large ribonuclease P (RNase P) RNA (RPR1) in the human pathogen Candida glabrata and verified that this molecule is expressed and present in the active enzyme complex of this hemiascomycete yeast. A structural alignment of the C. glabrata sequence with 36 other hemiascomycete RNase P RNAs (abbreviated as P RNAs) allows us to characterize the types of insertions. In addition, 15 P RNA sequences were newly characterized by searching in the recently sequenced genomes Candida albicans, C. glabrata, Debaryomyces hansenii, Eremothecium gossypii, Kluyveromyces lactis, Kluyveromyces waltii, Naumovia castellii, Saccharomyces kudriavzevii, Saccharomyces mikatae, and Yarrowia lipolytica; and by PCR amplification for other Candida species (Candida guilliermondii, Candida krusei, Candida parapsilosis, Candida stellatoidea, and Candida tropicalis). The phylogenetic comparative analysis identifies a hemiascomycete secondary structure consensus that presents a conserved core in all species with variable insertions or deletions. The most significant variability is found in C. glabrata P RNA in which three insertions exceeding in total 700 nt are present in the Specificity domain. This P RNA is more than twice the length of any other homologous P RNAs known in the three domains of life and is eight times the size of the smallest. RNase P RNA, therefore, represents one of the most diversified noncoding RNAs in terms of size variation and structural diversity.
Figures
Similar articles
-
Large telomerase RNA, telomere length heterogeneity and escape from senescence in Candida glabrata.FEBS Lett. 2009 Nov 19;583(22):3605-10. doi: 10.1016/j.febslet.2009.10.034. Epub 2009 Oct 17. FEBS Lett. 2009. PMID: 19840797
-
Nucleotide sequence analysis of the 5.8S rDNA and adjacent ITS2 region of Candida albicans and related species.Yeast. 1993 Nov;9(11):1199-206. doi: 10.1002/yea.320091106. Yeast. 1993. PMID: 8109169
-
Molecular modeling of the three-dimensional architecture of the RNA component of yeast RNase MRP.J Mol Biol. 1999 Oct 1;292(4):827-36. doi: 10.1006/jmbi.1999.3116. J Mol Biol. 1999. PMID: 10525408
-
Mitochondrial RNase P: the RNA family grows.Nucleic Acids Symp Ser. 1997;(36):42-4. Nucleic Acids Symp Ser. 1997. PMID: 9478201 Review.
-
Structure of ribonuclease P--a universal ribozyme.Curr Opin Struct Biol. 2006 Jun;16(3):327-35. doi: 10.1016/j.sbi.2006.04.002. Epub 2006 May 2. Curr Opin Struct Biol. 2006. PMID: 16650980 Review.
Cited by
-
Lipoic acid metabolism in microbial pathogens.Microbiol Mol Biol Rev. 2010 Jun;74(2):200-28. doi: 10.1128/MMBR.00008-10. Microbiol Mol Biol Rev. 2010. PMID: 20508247 Free PMC article. Review.
-
Genome structure and dynamics of the yeast pathogen Candida glabrata.FEMS Yeast Res. 2014 Jun;14(4):529-35. doi: 10.1111/1567-1364.12145. Epub 2014 Mar 10. FEMS Yeast Res. 2014. PMID: 24528571 Free PMC article. Review.
-
Defining the transcriptomic landscape of Candida glabrata by RNA-Seq.Nucleic Acids Res. 2015 Feb 18;43(3):1392-406. doi: 10.1093/nar/gku1357. Epub 2015 Jan 13. Nucleic Acids Res. 2015. PMID: 25586221 Free PMC article.
-
Gene expansion shapes genome architecture in the human pathogen Lichtheimia corymbifera: an evolutionary genomics analysis in the ancient terrestrial mucorales (Mucoromycotina).PLoS Genet. 2014 Aug 14;10(8):e1004496. doi: 10.1371/journal.pgen.1004496. eCollection 2014 Aug. PLoS Genet. 2014. PMID: 25121733 Free PMC article.
-
Genome Diversity and Evolution in the Budding Yeasts (Saccharomycotina).Genetics. 2017 Jun;206(2):717-750. doi: 10.1534/genetics.116.199216. Genetics. 2017. PMID: 28592505 Free PMC article. Review.
References
-
- Altman, S. and Kirsebom, L. 1999. Ribonuclease P. In The RNA world (eds. R.F. Gesteland et al.), pp. 351–380. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
-
- Cliften, P., Sudarsanam, P., Desikan, A., Fulton, L., Fulton, B., Majors, J., Waterston, R., Cohen, B.A., and Johnston, M. 2003. Finding functional features in Saccharomyces genomes by phylogenetic footprinting. Science 301: 71–76. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials