

doi: 10.1016/j.bandl.2005.06.001.
Epub 2005 Jul 22.
Neural modeling and imaging of the cortical interactions underlying syllable production
Affiliations
- PMID: 16040108
- PMCID: PMC1473986
- DOI: 10.1016/j.bandl.2005.06.001
Item in Clipboard
Neural modeling and imaging of the cortical interactions underlying syllable production
Brain Lang.
2006 Mar.
Abstract
This paper describes a neural model of speech acquisition and production that accounts for a wide range of acoustic, kinematic, and neuroimaging data concerning the control of speech movements. The model is a neural network whose components correspond to regions of the cerebral cortex and cerebellum, including premotor, motor, auditory, and somatosensory cortical areas. Computer simulations of the model verify its ability to account for compensation to lip and jaw perturbations during speech. Specific anatomical locations of the model's components are estimated, and these estimates are used to simulate fMRI experiments of simple syllable production.
Figures
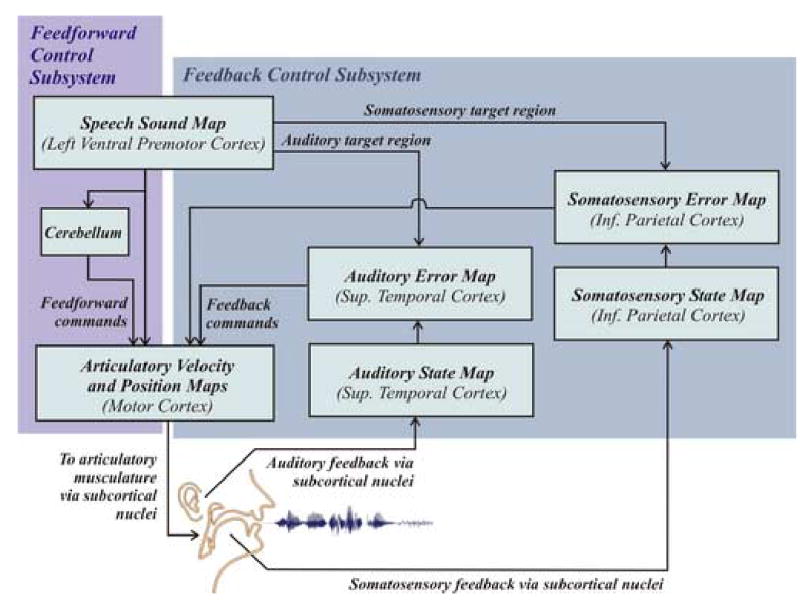
Hypothesized neural processing stages involved in speech acquisition and production according to the DIVA model. Projections to and from the cerebellum are simplified for clarity.
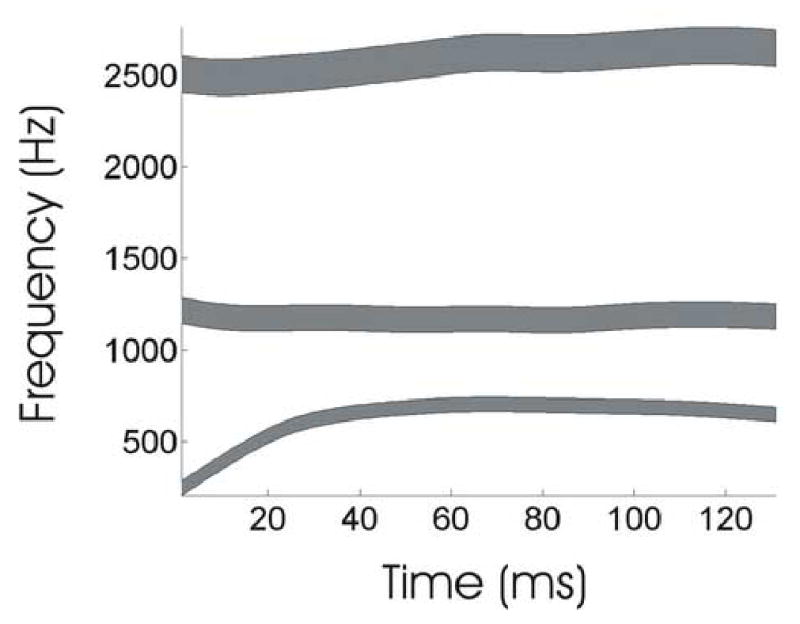
Auditory target region for the first three formants of the syllable “ba” as learned by the model from an audio sample of an adult male speaker.
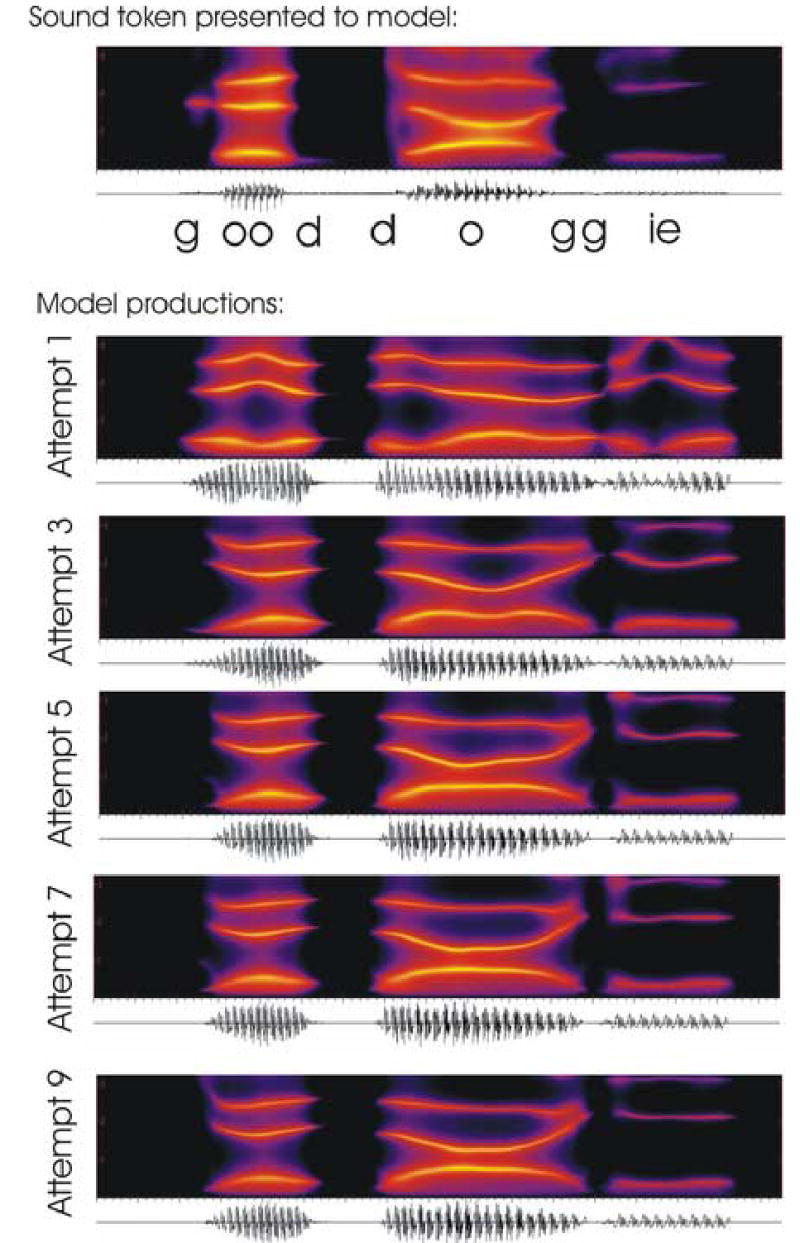
Spectrograms showing the first three formants of the utterance “good doggie” as produced by an adult male speaker (top panel) and by the model (bottom panels). The model first learns an acoustic target for the utterance based on the sample it is presented (top panel). Then the model attempts to produce the sound, at first primarily under feedback control (Attempt 1), then with progressively improved feedforward commands supplementing the feedback control (Attempts 3, 5, 7, and 9). By the 9th attempt the feedforward control signals are accurate enough for the model to closely imitate the formant trajectories from the sample utterance.
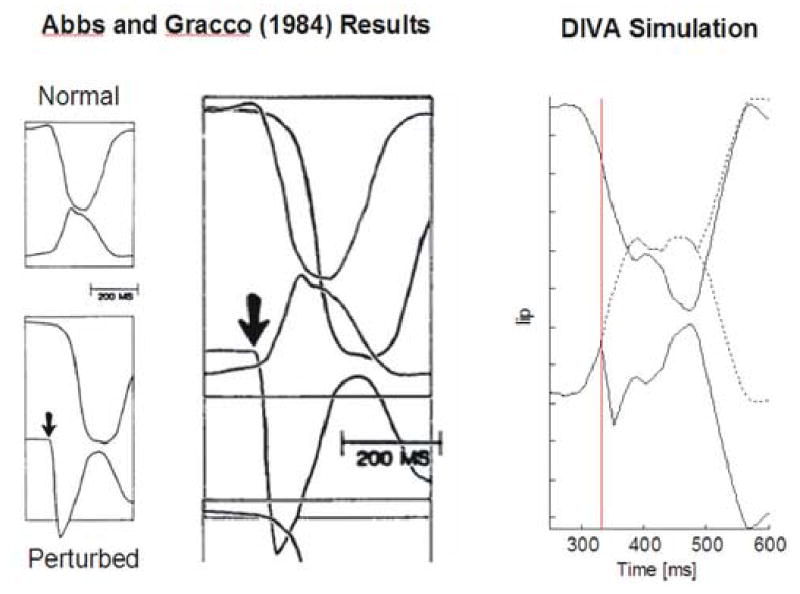
Abbs and Gracco (1984) lip perturbation experimental results (left) and model simulation results (right). Far left panels show upper and lower lip positions during bilabial consonant production in the normal (top) and perturbed (bottom) conditions of the Abbs and Gracco (1984) experiment; shown to the right of this is a superposition of the normal and perturbed trials in a single image. Arrows indicate onset of perturbation. [Adapted from Abbs and Gracco (1984).] The right panel shows the lip heights from model simulations of the control (dashed lines) and perturbed (solid lines) conditions for the same perturbation, applied as the model starts to produce the /b/ in /aba/ (vertical line). The solid lines demonstrate the compensation provided by the upper and lower lips, which achieve contact despite the perturbation. The latency of the model’s compensatory response is within the range measured by Abbs and Gracco (1984).
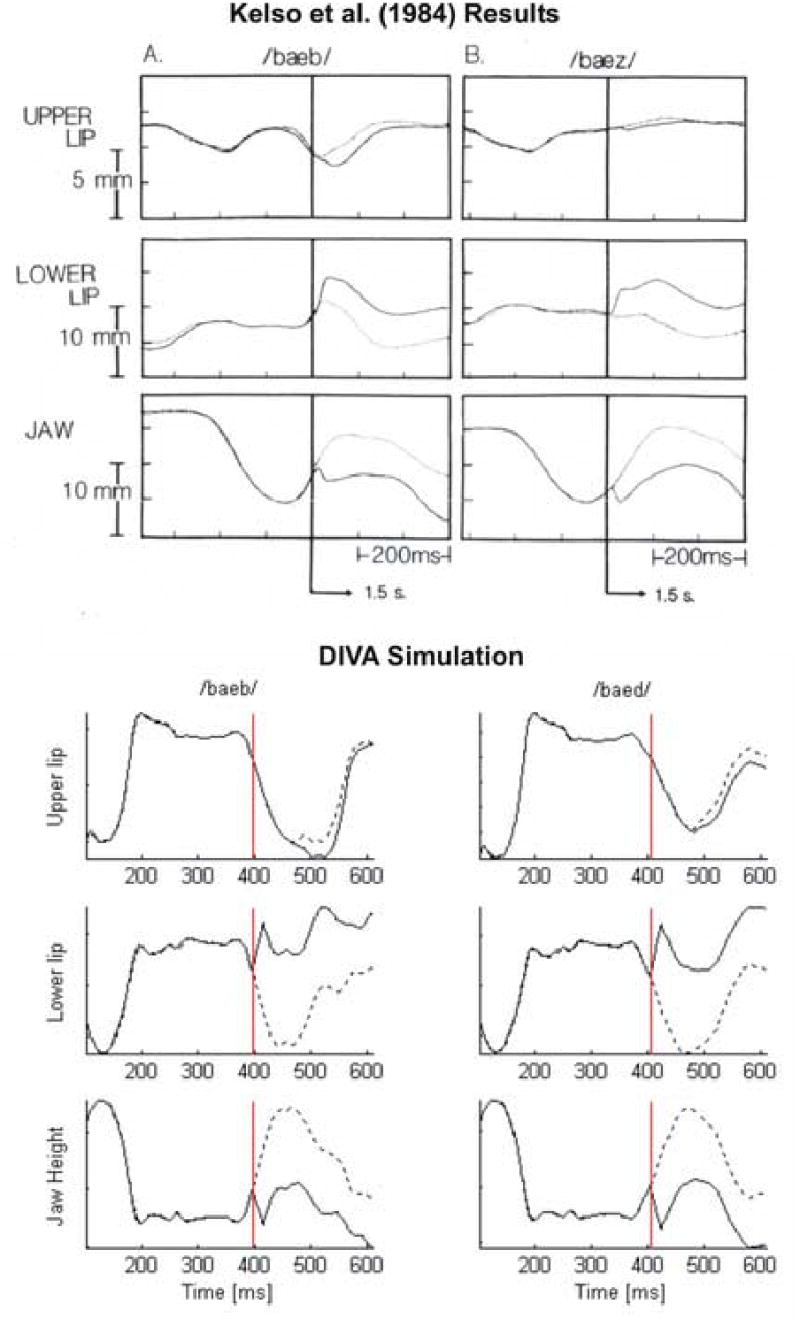
Top: Results of Kelso et al. (1984) jaw perturbation experiment. Dotted lines indicate normal (unperturbed) trials, and solid lines indicate perturbed trials. The vertical line indicates onset of perturbation. Lower lip position is measured relative to jaw. Subjects produce compensatory downward movement of the upper lip for the bilabial stop /b/ but not for the alveolar stop /d/. [Adapted from (Kelso, Tuller, Vatikiotis-Bateson, & Fowler, 1984).] Bottom: Corresponding DIVA simulation. As in the Kelso et al. (1984) experiment, the model produces a compensatory downward movement of the upper lip for the bilabial stop /b/ but not for the alveolar stop /d/.

Rendered lateral surfaces of the SPM standard brain indicating locations of the model components as described in the text. Medial regions (anterior paravermal cerebellum and deep cerebellar nuclei) are omitted. Unless otherwise noted, labels along the central sulcus correspond to a motor (anterior) and a somatosensory (posterior) representation for each articulator. Abbreviation key: Aud = auditory state cells; ΔA = auditory error cells; ΔS = somatosensory error cells; Lat Cbm = superior lateral cerebellum; Resp = motor respiratory region; SSM = speech sound map. *Palate representation is somatosensory only. †Respiratory representation is motor only.
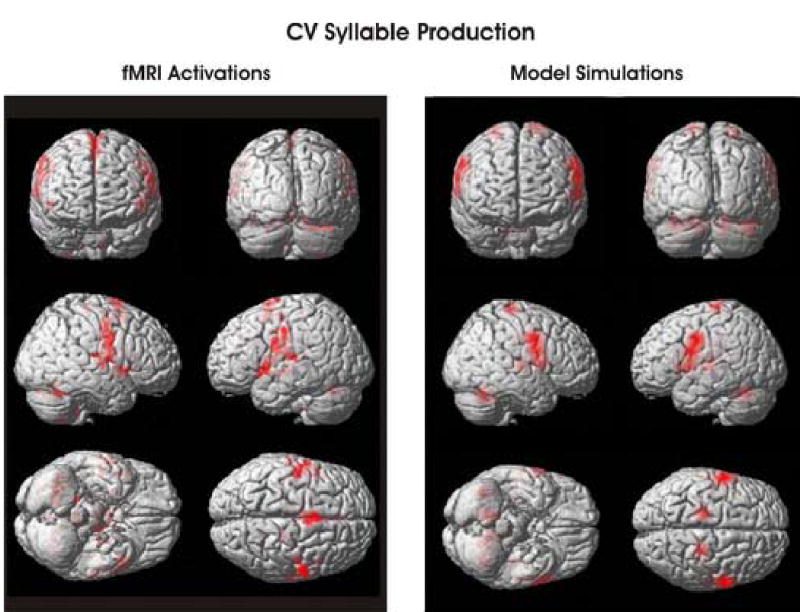
fMRI activations measured in human subjects while they read simple syllables from a screen (left) and simulated fMRI activations derived from the model’s cell activities during simple syllable production (right). See text for details.
References
-
- Abbs JH, Gracco VL. Control of complex motor gestures: orofacial muscle responses to load perturbations of lip during speech. Journal of Neurophysiology. 1984;51:705–723. - PubMed
-
- Ackermann H, Vogel M, Petersen D, Poremba M. Speech deficits in ischaemic cerebellar lesions. Journal of Neurology. 1992;239:223–227. - PubMed
-
- Arbib, M.A. (in press). From monkey-like action recognition to human language: An evolutionary framework for linguistics. Behavioral and Brain Sciences - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
