

G2D: a tool for mining genes associated with disease
- PMID: 16115313
- PMCID: PMC1208881
- DOI: 10.1186/1471-2156-6-45
G2D: a tool for mining genes associated with disease
Abstract
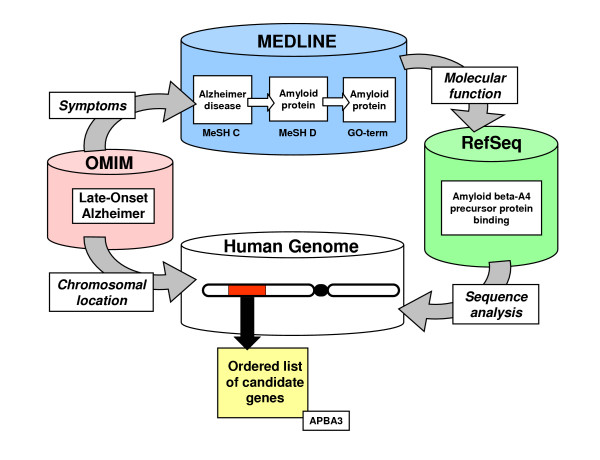
Background: Human inherited diseases can be associated by genetic linkage with one or more genomic regions. The availability of the complete sequence of the human genome allows examining those locations for an associated gene. We previously developed an algorithm to prioritize genes on a chromosomal region according to their possible relation to an inherited disease using a combination of data mining on biomedical databases and gene sequence analysis.
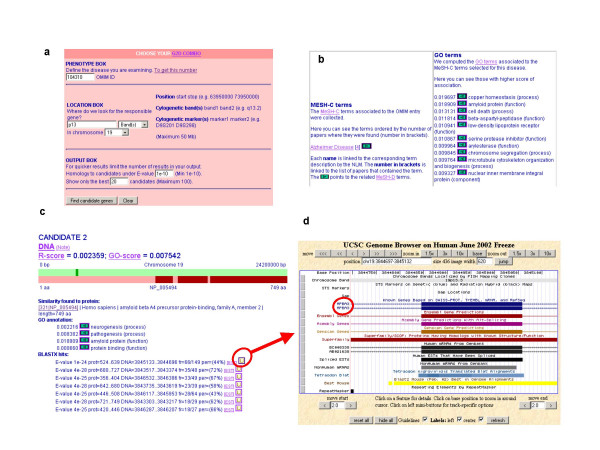
Results: We have implemented this method as a web application in our site G2D (Genes to Diseases). It allows users to inspect any region of the human genome to find candidate genes related to a genetic disease of their interest. In addition, the G2D server includes pre-computed analyses of candidate genes for 552 linked monogenic diseases without an associated gene, and the analysis of 18 asthma loci.
Conclusion: G2D can be publicly accessed at http://www.ogic.ca/projects/g2d_2/.
Figures
References
-
- Perez-Iratxeta C, Bork P, Andrade MA. Association of genes to genetically inherited diseases using data mining. Nat Genet. 2002;31:316–319. - PubMed
-
- Wheeler DL, Church DM, Edgar R, Federhen S, Helmberg W, Madden TL, Pontius JU, Schuler GD, Schriml LM, Sequeira E, Suzek TO, Tatusova TA, Wagner L. Database resources of the National Center for Biotechnology Information: update. Nucleic Acids Res. 2004;32:D35–D40. doi: 10.1093/nar/gkh073. - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
