

doi: 10.1186/gb-2005-6-9-r80.
Epub 2005 Aug 16.
PubNet: a flexible system for visualizing literature derived networks
Affiliations
- PMID: 16168087
- PMCID: PMC1242215
- DOI: 10.1186/gb-2005-6-9-r80
Item in Clipboard
PubNet: a flexible system for visualizing literature derived networks
Genome Biol.
2005.
Abstract
We have developed PubNet, a web-based tool that extracts several types of relationships returned by PubMed queries and maps them into networks, allowing for graphical visualization, textual navigation, and topological analysis. PubNet supports the creation of complex networks derived from the contents of individual citations, such as genes, proteins, Protein Data Bank (PDB) IDs, Medical Subject Headings (MeSH) terms, and authors. This feature allows one to, for example, examine a literature derived network of genes based on functional similarity.
Figures

Basic examples. (a) The main page allows for submission of one or two queries. Queries are entered into the blue and yellow text boxes, and parameter options are selected below. Nodes may be defined as author, paper, Protein Data Bank (PDB), Genbank, or Swiss-Prot ID, and edges may be drawn for co-authorship, shared Medical Subject Headings (MeSH) term, or shared location. (b) PubNet connects to PubMed, submits each query separately, and parses the XML results. In this example, only Query1 was submitted, returning four publications. (c) In the output, each paper is represented as a single node. Each pair of nodes that share a common author are linked by an edge. (d) In this example, Query1 and Query2 have each returned three papers, each with MeSH terms and PDB IDs. (e) When nodes are specified as papers and edges specified as shared MeSH terms, papers returned only by Query1 are represented as blue nodes, papers returned only by Query2 are shown in yellow, and papers common to both queries are shown in green. (f) When nodes are specified as PDB IDs and edges specified as shared MeSH terms, each PDB ID from each paper is represented as a node and colored according to the query from which it was derived. A single paper can give rise to multiple nodes, as is the case for Paper3, which contains two PDB identifiers, each of which are represented by a separate node.

Node and edge reference chart. Nodes and edges can have subtle meanings depending on the parameters used to draw graphs with PubNet. This chart can be used as an aid when interpreting complex graphs. MeSH, Medical Subject Headings; PDB, Protein Data Bank.

Collaborative organization of the Northeast Structural Genomics (NESG) consortium. (a) Paper nodes linked by co-authorship edges show four major groups of publications, roughly corresponding to individual laboratories from which they were published. Here, three of the groups are fairly well connected to form the central nodes in the graph. The fourth set of papers is internally well connected but is only linked to other groups by a single paper with shared authors. (b) When nodes are drawn as authors with co-authorship edges, a slightly different pattern emerges. The principal investigators from each laboratory tend to form central anchor points, from which other laboratory members branch out. Links also connect collaborating laboratories. (c) Yet another pattern arises when shared Medical Subject Headings (MeSH) terms are used to connect papers. As expected, a large and well connected group of nodes is drawn in the center. Several unconnected nodes lining the periphery show papers that are unrelated in subject matter to the main group. (d) When papers are linked by shared zip codes, large clusters arise corresponding to geographically disparate laboratories. Here, the main clusters are the Universities of Washington, Columbia, Yale, Buffalo, and Rutgers.
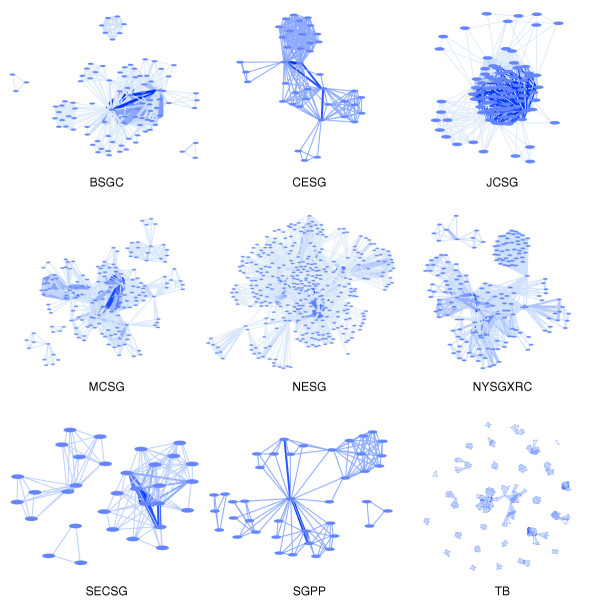
Author/co-authorship graphs for nine pilot centers of the Protein Structure Initiative. Publications were collected from the official publication lists of the following centers: Berkeley Center for Structural Genomics (BSGC), Center for Eukaroytic Structural Genomics (CESG), Joint Center for Structural Genomics (JCSG), Midwest Consortium for Structural Genomics (MCSG), Northeast Structural Genomics (NESG) consortium, New York Structural Genomics Research Consortium (NYSGXRC), Southeast Consortium for Structural Genomics (SECSG), Structural Genomics of Pathogenic Protozoa (SGPP), and Tuberculosis Structural Genomics (TB) consortium. The MCSG, NESG, and NYSGXRC consortia have comparably greater authorship of publications, with individual laboratories clustering together. The BSGC and JCSG centers include nearly all participating authors on every publication, as seen by dense clusters with heavy edge weights. At the other extreme, the TB consortium is a loose collaboration of many groups of different scientists who tend to publish separately.

DNA and RNA polymerase Protein Data Bank (PDB) IDs connected by Medical Subject Headings (MeSH) terms. (a) The PubNet graph resulting from the queries 'DNA polymerase 2004[dp]' and 'RNA polymerase 2004[dp]'. (b) A magnified view showing several PDB IDs that were present in papers returned by the first query. PDB IDs that were only returned by the 'DNA' query are blue, and those returned by both queries are shown in green. The green nodes correspond to structures of DNA primase. (c) A magnified view of several RNA polymerase PDB IDs.

Structure publications linked by Medical Subject Headings (MeSH) terms. (a) All available primary citations for Protein Structure Initiative (PSI) structures (shown in blue) were compared with primary citations from a random set of 300 Protein Data Bank (PDB) structures (shown in yellow). Blue color nodes are segregated into tight clusters, indicating close similarity among PSI structures. Yellow nodes are relatively interspersed because of fewer common edges, indicating greater variability in connecting MeSH terms. Out of a total of 860 MeSH terms associated with PSI structure nodes (435 of which are unique), the term 'Bacterial proteins - chemistry' is the most common, connecting a clique of 52 nodes. (b) As a control, two random sets of 300 PDB structures were chosen from a set of 3,112 structures released in 2001-2002 that included a primary citation available in PubMed. Those sets of citations were then run through PubNet as Query1 and Query2. Nodes of both colors are fairly well interspersed. The PDB structure nodes carry 1,247 MeSH terms (861 unique), the most common of which is also 'Bacterial proteins - chemistry', but it only connects a clique of 16 nodes.
References
-
- Entrez PubMed http://www.ncbi.nlm.nih.gov/entrez/
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
