

The PeptideAtlas project
- PMID: 16381952
- PMCID: PMC1347403
- DOI: 10.1093/nar/gkj040
The PeptideAtlas project
Abstract
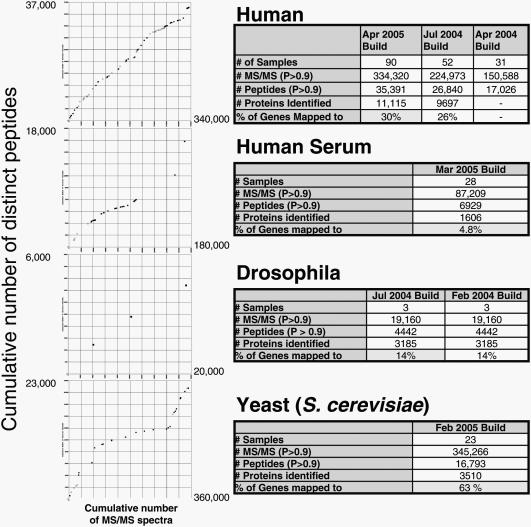
The completion of the sequencing of the human genome and the concurrent, rapid development of high-throughput proteomic methods have resulted in an increasing need for automated approaches to archive proteomic data in a repository that enables the exchange of data among researchers and also accurate integration with genomic data. PeptideAtlas (http://www.peptideatlas.org/) addresses these needs by identifying peptides by tandem mass spectrometry (MS/MS), statistically validating those identifications and then mapping identified sequences to the genomes of eukaryotic organisms. A meaningful comparison of data across different experiments generated by different groups using different types of instruments is enabled by the implementation of a uniform analytic process. This uniform statistical validation ensures a consistent and high-quality set of peptide and protein identifications. The raw data from many diverse proteomic experiments are made available in the associated PeptideAtlas repository in several formats. Here we present a summary of our process and details about the Human, Drosophila and Yeast PeptideAtlas builds.
Figures

References
-
- Eng J., McCormack A.L., Yates J.R. An approach to correlate tandem mass spectral data of peptides with amino acid sequences in a protein database. J. Am. Soc. Mass Spectrom. 1994;5:976–989. - PubMed
-
- Keller A., Nesvizhskii A.I., Kolker E., Aebersold R. Empirical statistical model to estimate the accuracy of peptide identifications made by MS/MS and database search. Anal. Chem. 2002;74:5383–5392. - PubMed
-
- Altschul S.F., Gish W., Miller W., Myers E.W., Lipman D.J. Basic local alignment search tool. J. Mol. Biol. 1990;215:403–410. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
