

An approach for clustering gene expression data with error information
- PMID: 16409635
- PMCID: PMC1360687
- DOI: 10.1186/1471-2105-7-17
An approach for clustering gene expression data with error information
Abstract
Background: Clustering of gene expression patterns is a well-studied technique for elucidating trends across large numbers of transcripts and for identifying likely co-regulated genes. Even the best clustering methods, however, are unlikely to provide meaningful results if too much of the data is unreliable. With the maturation of microarray technology, a wealth of research on statistical analysis of gene expression data has encouraged researchers to consider error and uncertainty in their microarray experiments, so that experiments are being performed increasingly with repeat spots per gene per chip and with repeat experiments. One of the challenges is to incorporate the measurement error information into downstream analyses of gene expression data, such as traditional clustering techniques.
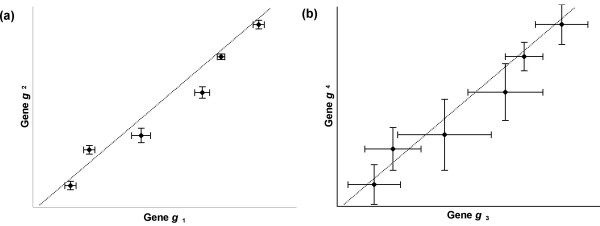
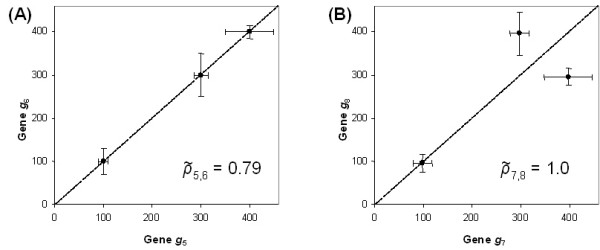
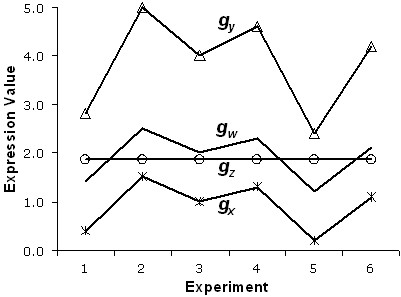
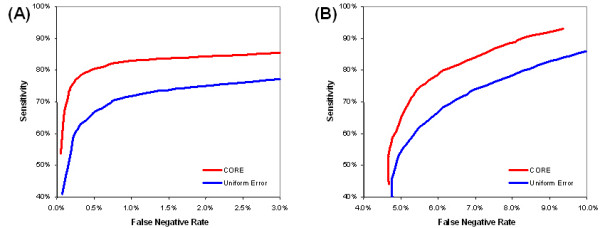
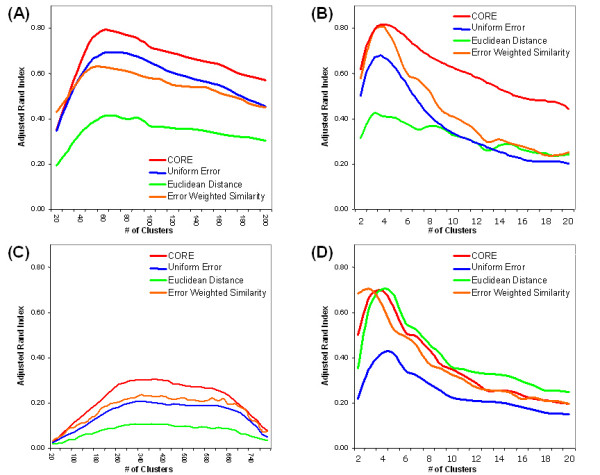
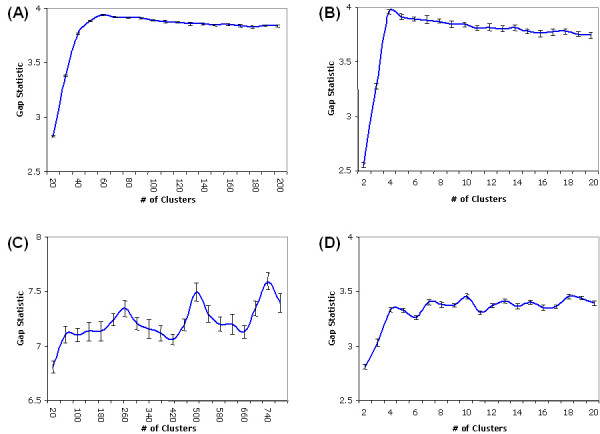
Results: In this study, a clustering approach is presented which incorporates both gene expression values and error information about the expression measurements. Using repeat expression measurements, the error of each gene expression measurement in each experiment condition is estimated, and this measurement error information is incorporated directly into the clustering algorithm. The algorithm, CORE (Clustering Of Repeat Expression data), is presented and its performance is validated using statistical measures. By using error information about gene expression measurements, the clustering approach is less sensitive to noise in the underlying data and it is able to achieve more accurate clusterings. Results are described for both synthetic expression data as well as real gene expression data from Escherichia coli and Saccharomyces cerevisiae.
Conclusion: The additional information provided by replicate gene expression measurements is a valuable asset in effective clustering. Gene expression profiles with high errors, as determined from repeat measurements, may be unreliable and may associate with different clusters, whereas gene expression profiles with low errors can be clustered with higher specificity. Results indicate that including error information from repeat gene expression measurements can lead to significant improvements in clustering accuracy.
Figures

References
-
- Tavazoie S, Hughes JD, Campbell MJ, Cho RJ, Church GM. Systematic determination of genetic network architecture. Nat Genet. 1999;22:281–285. - PubMed
-
- Hartuv E, Schmitt A, Lange J, Meirer-Ewert S, Lehrach H, Shamir R. An algorithm for clustering cDNAs for gene expression analysis. Proceedings for the Third Annual International Conference on Research in Computational Molecular Biology. 1999. pp. 188–197.
-
- Dasgupta A, Raftery AE. Detecting features in spatial point processes with clutter via model-based clustering. Journal of the American Statistical Association. 1998;93:294–302.
MeSH terms
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
