

Post-transcriptional nucleotide modification and alternative folding of RNA
- PMID: 16452298
- PMCID: PMC1360285
- DOI: 10.1093/nar/gkj471
Post-transcriptional nucleotide modification and alternative folding of RNA
Erratum in
- Nucleic Acids Res. 2007;35(20):7041
Abstract
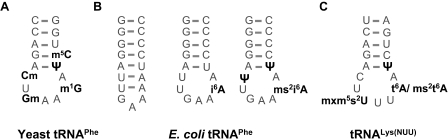
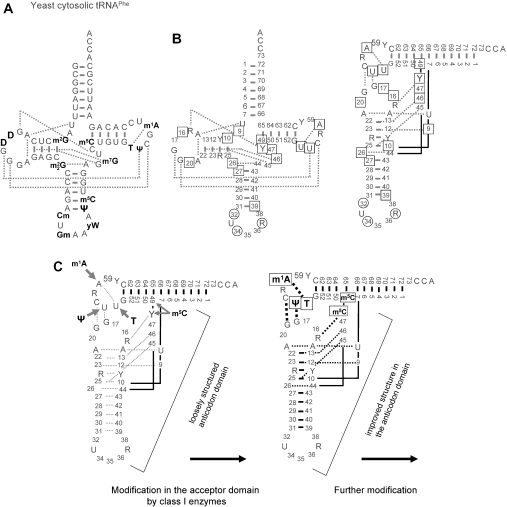
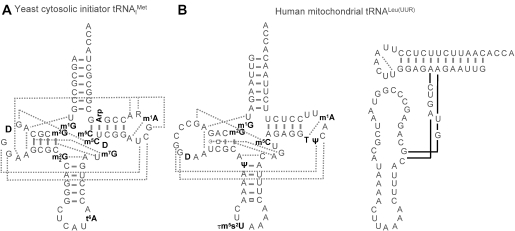
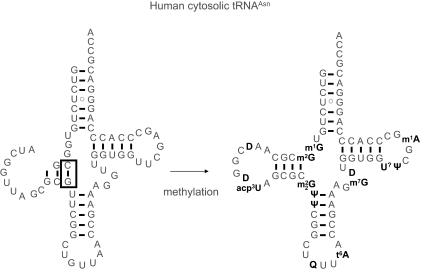
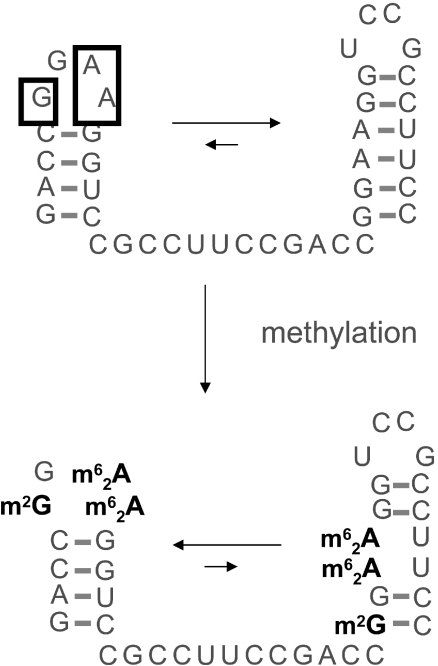
Alternative foldings are an inherent property of RNA and a ubiquitous problem in scientific investigations. To a living organism, alternative foldings can be a blessing or a problem, and so nature has found both, ways to harness this property and ways to avoid the drawbacks. A simple and effective method employed by nature to avoid unwanted folding is the modulation of conformation space through post-transcriptional base modification. Modified nucleotides occur in almost all classes of natural RNAs in great chemical diversity. There are about 100 different base modifications known, which may perform a plethora of functions. The presumably most ancient and simple nucleotide modifications, such as methylations and uridine isomerization, are able to perform structural tasks on the most basic level, namely by blocking or reinforcing single base-pairs or even single hydrogen bonds in RNA. In this paper, functional, genomic and structural evidence on cases of folding space alteration by post-transcriptional modifications in native RNA are reviewed.
Figures

References
-
- Garcia G.A., Goodenough-Lashua D.M. Mechanisms of RNA-modifying and -editing enzymes. In: Grosjean H., Benne R., editors. Modification and Editing of RNA. Washington DC: ASM Press; 1998. pp. 135–168.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
