

Gene connectivity, function, and sequence conservation: predictions from modular yeast co-expression networks
- PMID: 16515682
- PMCID: PMC1413526
- DOI: 10.1186/1471-2164-7-40
Gene connectivity, function, and sequence conservation: predictions from modular yeast co-expression networks
Abstract
Background: Genes and proteins are organized into functional modular networks in which the network context of a gene or protein has implications for cellular function. Highly connected hub proteins, largely responsible for maintaining network connectivity, have been found to be much more likely to be essential for yeast survival.
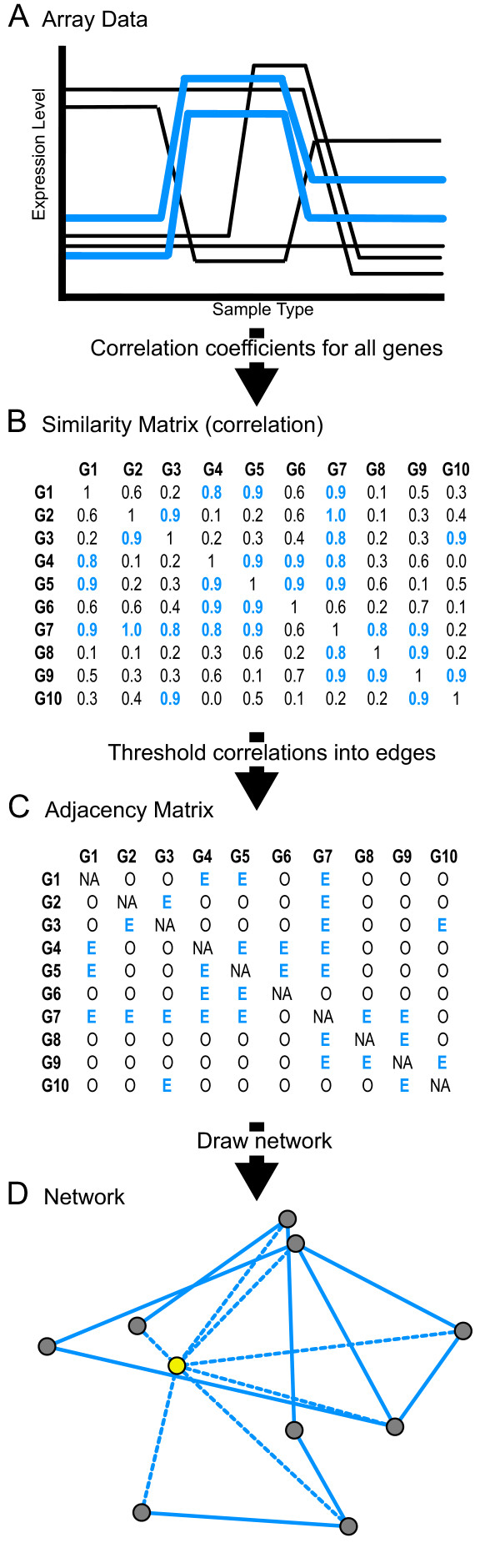
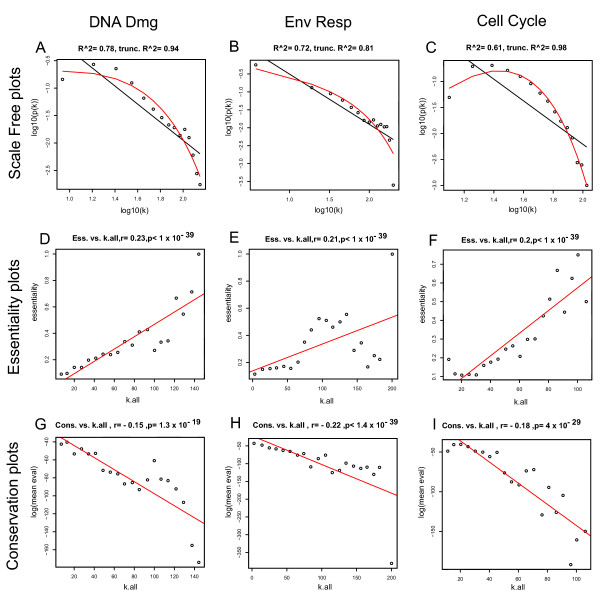
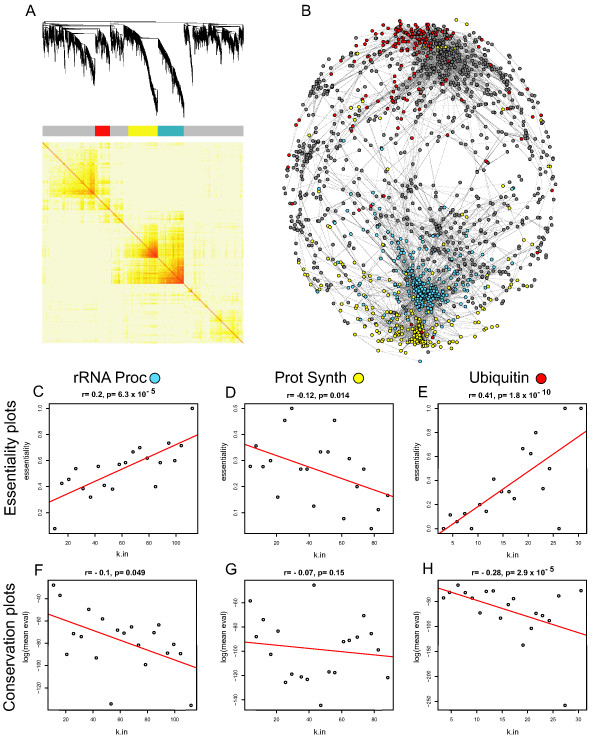
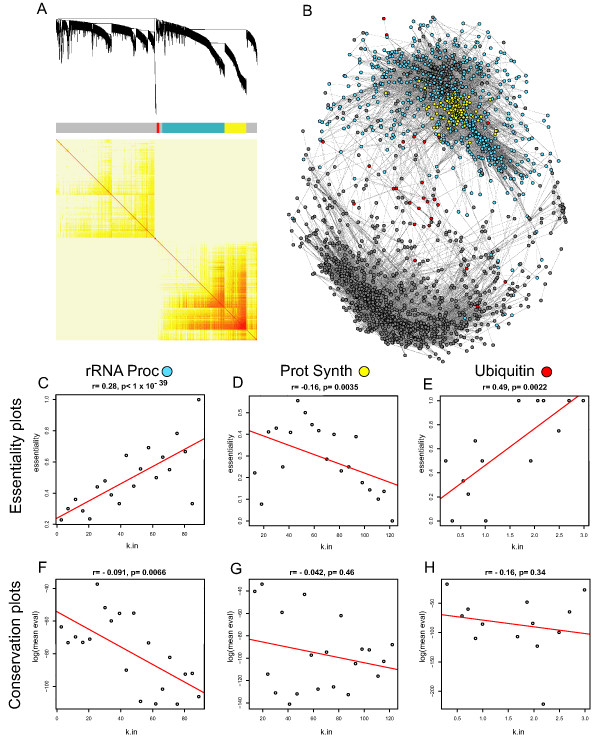
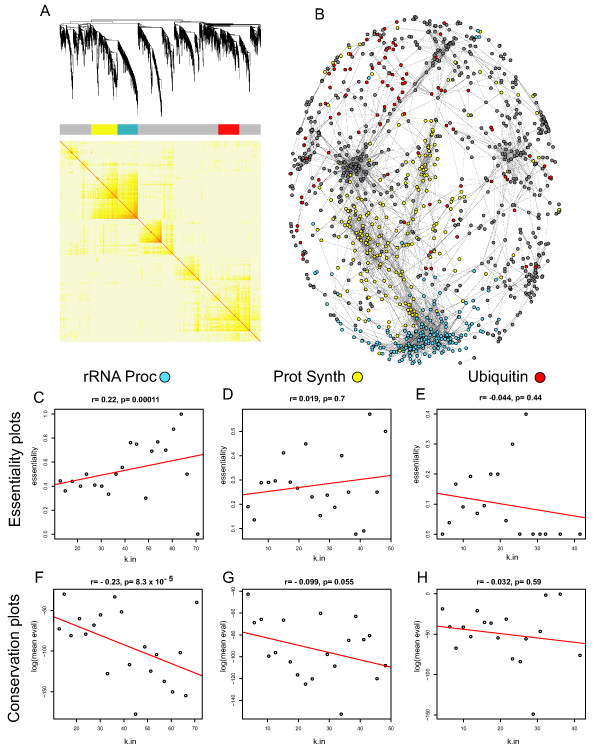
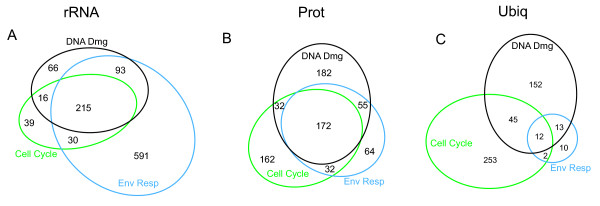
Results: Here we investigate the properties of weighted gene co-expression networks formed from multiple microarray datasets. The constructed networks approximate scale-free topology, but this is not universal across all datasets. We show strong positive correlations between gene connectivity within the whole network and gene essentiality as well as gene sequence conservation. We demonstrate the preservation of a modular structure of the networks formed, and demonstrate that, within some of these modules, it is possible to observe a strong correlation between connectivity and essentiality or between connectivity and conservation within the modules particularly within modules containing larger numbers of essential genes.
Conclusion: Application of these techniques can allow a finer scale prediction of relative gene importance for a particular process within a group of similarly expressed genes.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
