

Detecting outliers when fitting data with nonlinear regression - a new method based on robust nonlinear regression and the false discovery rate
- PMID: 16526949
- PMCID: PMC1472692
- DOI: 10.1186/1471-2105-7-123
Detecting outliers when fitting data with nonlinear regression - a new method based on robust nonlinear regression and the false discovery rate
Abstract
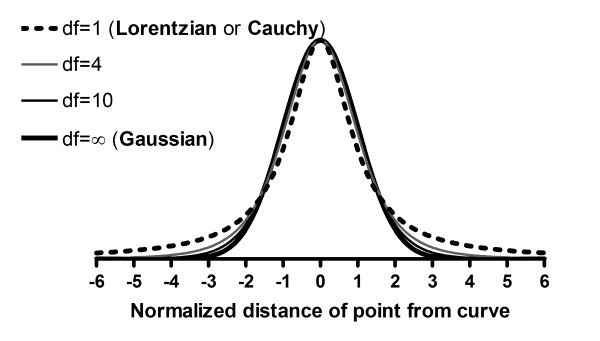
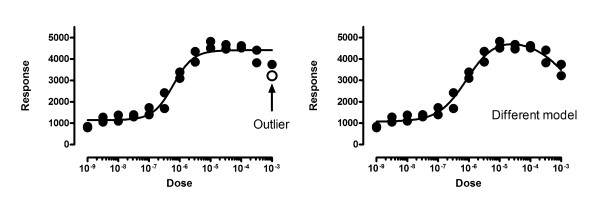
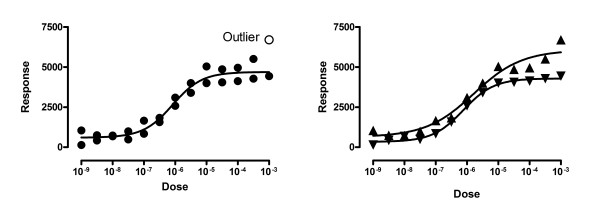
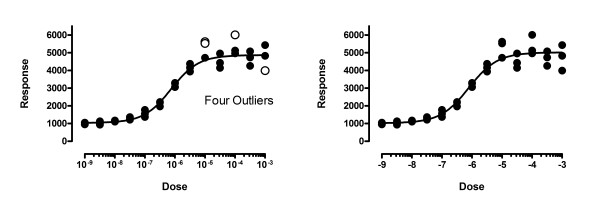
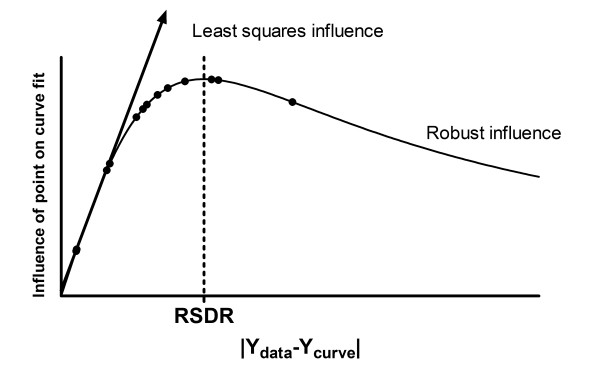
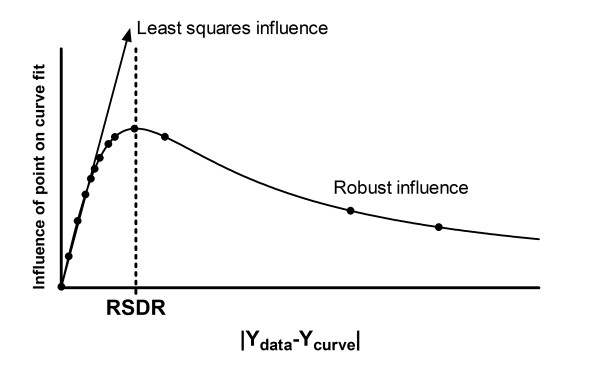
Background: Nonlinear regression, like linear regression, assumes that the scatter of data around the ideal curve follows a Gaussian or normal distribution. This assumption leads to the familiar goal of regression: to minimize the sum of the squares of the vertical or Y-value distances between the points and the curve. Outliers can dominate the sum-of-the-squares calculation, and lead to misleading results. However, we know of no practical method for routinely identifying outliers when fitting curves with nonlinear regression.
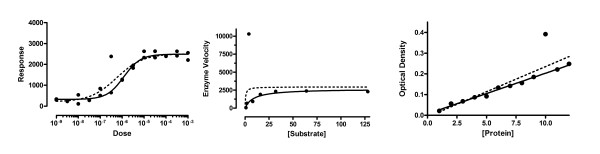
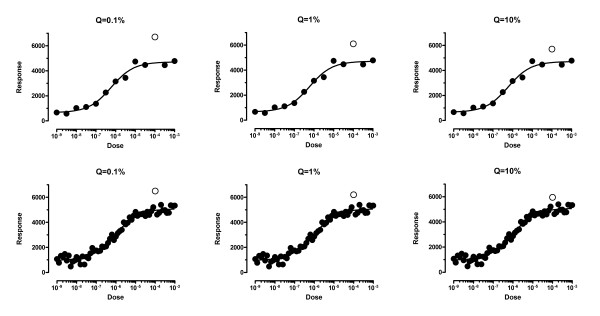
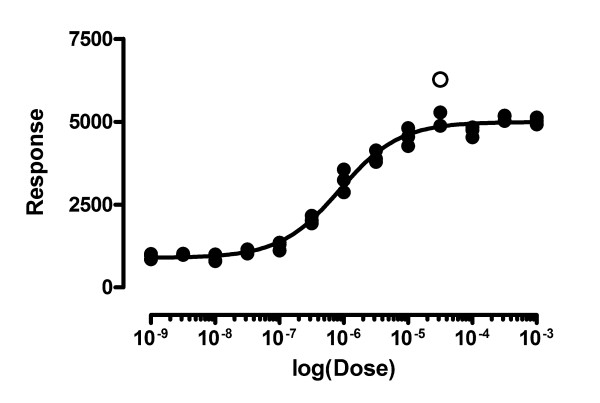
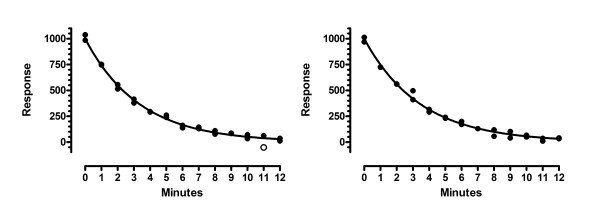
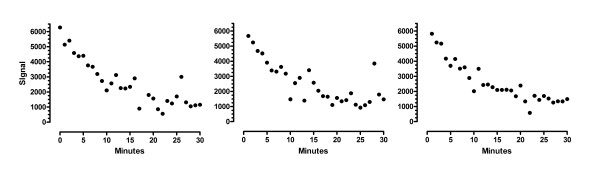
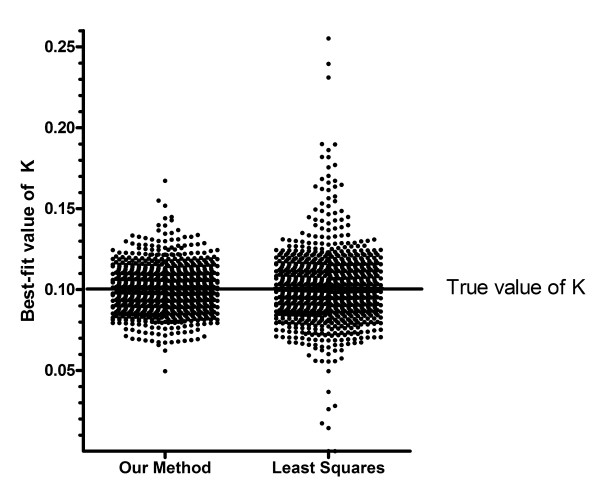
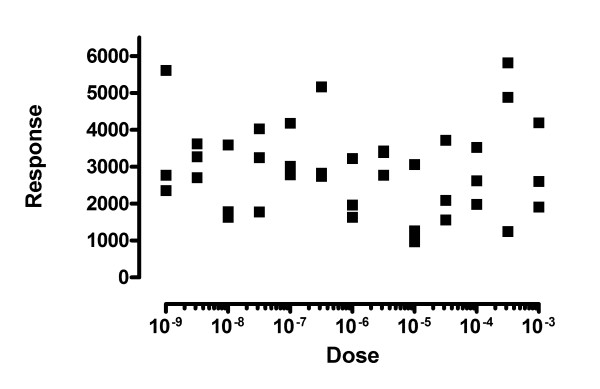
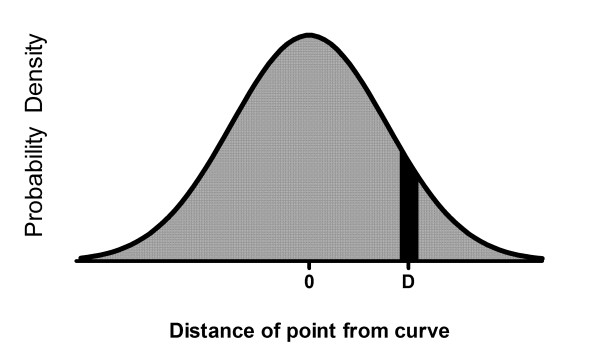
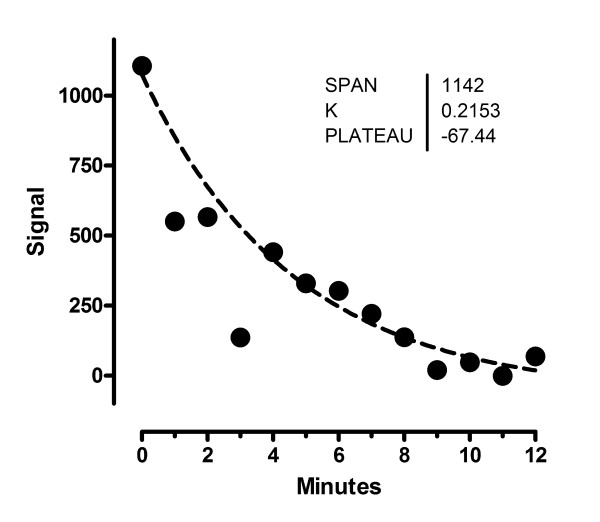
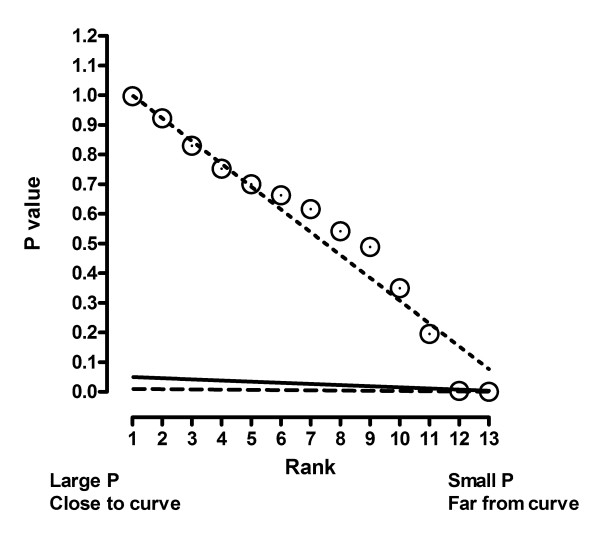
Results: We describe a new method for identifying outliers when fitting data with nonlinear regression. We first fit the data using a robust form of nonlinear regression, based on the assumption that scatter follows a Lorentzian distribution. We devised a new adaptive method that gradually becomes more robust as the method proceeds. To define outliers, we adapted the false discovery rate approach to handling multiple comparisons. We then remove the outliers, and analyze the data using ordinary least-squares regression. Because the method combines robust regression and outlier removal, we call it the ROUT method. When analyzing simulated data, where all scatter is Gaussian, our method detects (falsely) one or more outlier in only about 1-3% of experiments. When analyzing data contaminated with one or several outliers, the ROUT method performs well at outlier identification, with an average False Discovery Rate less than 1%.
Conclusion: Our method, which combines a new method of robust nonlinear regression with a new method of outlier identification, identifies outliers from nonlinear curve fits with reasonable power and few false positives.
Figures
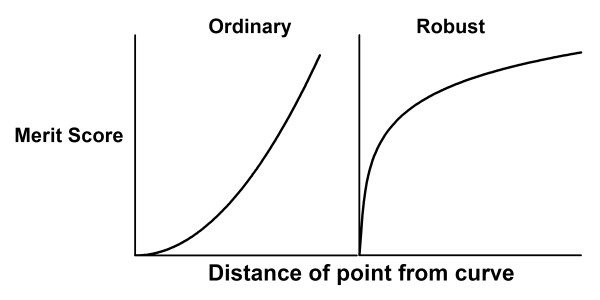
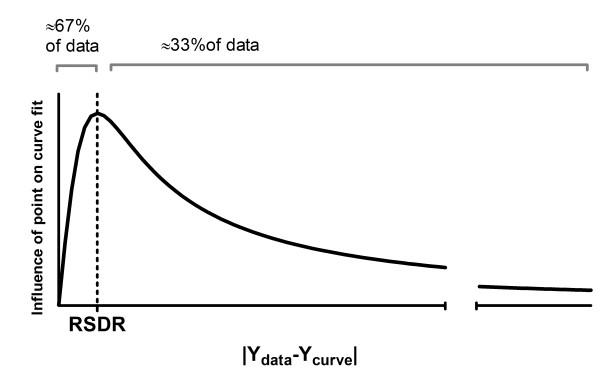
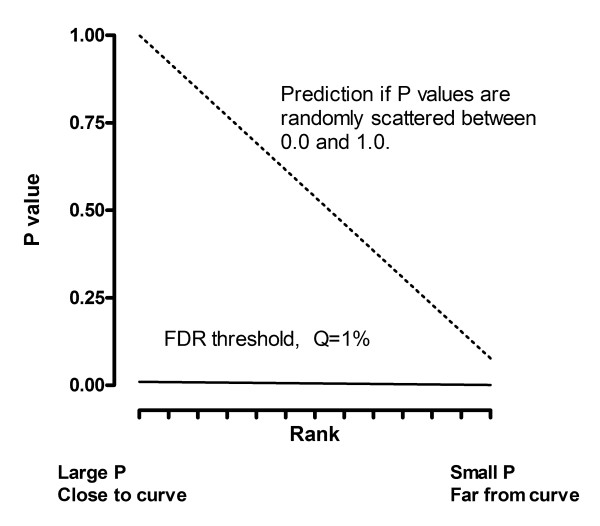
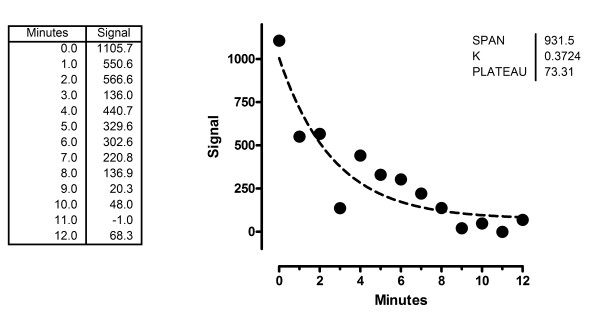
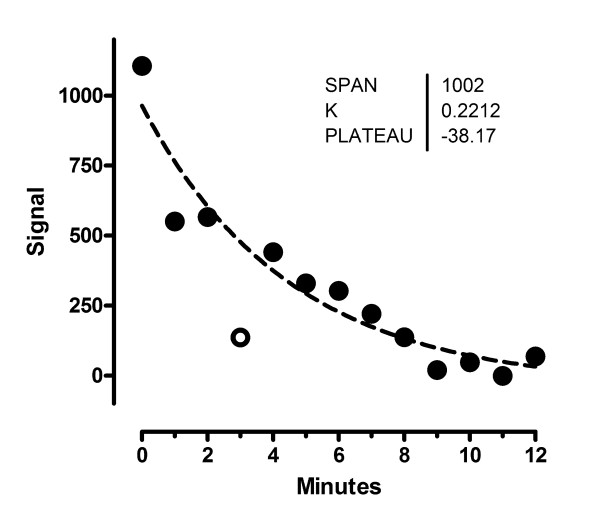
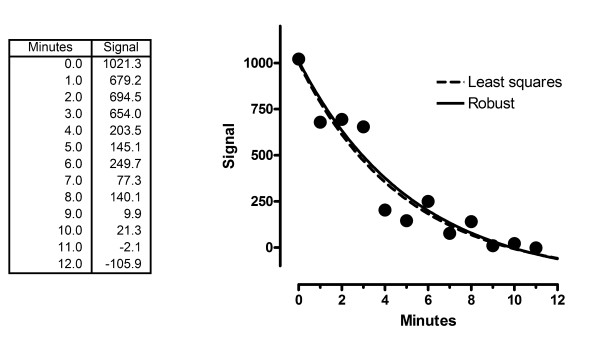
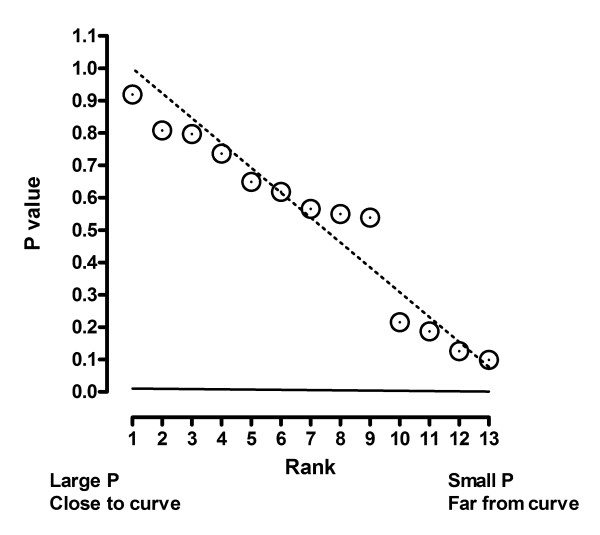
References
-
- Barnett V, Lewis T. Outliers in Statistical Data. 3. New York: John Wiley and sons; 1994.
-
- Hampel FR, Ronchetti EM, Rousseeuw PJ, Stahel WA. Robust Statistics the Approach Based on Influence Functions. New York: John Wiley and Sons; 1986.
-
- Hoaglin DC, Mosteller F, Tukey JW. Understanding Robust and Exploratory Data Analysis. New York: John Wiley and sons; 1983.
-
- Press WH, Teukolsky SA, Vettering WT, Flannery BP. Numerical Recipes in C the Art of Scientific Computing. New York, NY: Cambridge University Press; 1988.
-
- Benjamini Y, Hochberg Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J R Statist Soc B. 1995;57:290–300.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
