

Reproducibility of the STARD checklist: an instrument to assess the quality of reporting of diagnostic accuracy studies
- PMID: 16539705
- PMCID: PMC1522016
- DOI: 10.1186/1471-2288-6-12
Reproducibility of the STARD checklist: an instrument to assess the quality of reporting of diagnostic accuracy studies
Abstract
Background: In January 2003, STAndards for the Reporting of Diagnostic accuracy studies (STARD) were published in a number of journals, to improve the quality of reporting in diagnostic accuracy studies. We designed a study to investigate the inter-assessment reproducibility, and intra- and inter-observer reproducibility of the items in the STARD statement.
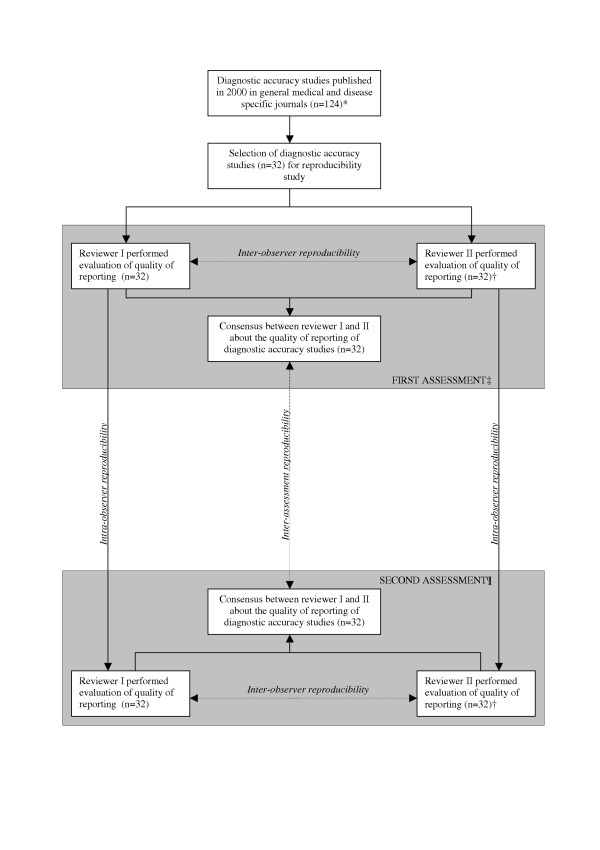
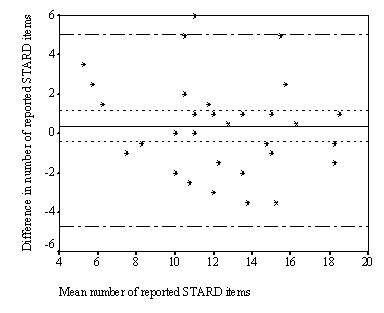
Methods: Thirty-two diagnostic accuracy studies published in 2000 in medical journals with an impact factor of at least 4 were included. Two reviewers independently evaluated the quality of reporting of these studies using the 25 items of the STARD statement. A consensus evaluation was obtained by discussing and resolving disagreements between reviewers. Almost two years later, the same studies were evaluated by the same reviewers. For each item, percentages agreement and Cohen's kappa between first and second consensus assessments (inter-assessment) were calculated. Intraclass Correlation coefficients (ICC) were calculated to evaluate its reliability.
Results: The overall inter-assessment agreement for all items of the STARD statement was 85% (Cohen's kappa 0.70) and varied from 63% to 100% for individual items. The largest differences between the two assessments were found for the reporting of the rationale of the reference standard (kappa 0.37), number of included participants that underwent tests (kappa 0.28), distribution of the severity of the disease (kappa 0.23), a cross tabulation of the results of the index test by the results of the reference standard (kappa 0.33) and how indeterminate results, missing data and outliers were handled (kappa 0.25). Within and between reviewers, also large differences were observed for these items. The inter-assessment reliability of the STARD checklist was satisfactory (ICC = 0.79 [95% CI: 0.62 to 0.89]).
Conclusion: Although the overall reproducibility of the quality of reporting on diagnostic accuracy studies using the STARD statement was found to be good, substantial disagreements were found for specific items. These disagreements were not so much caused by differences in interpretation of the items by the reviewers but rather by difficulties in assessing the reporting of these items due to lack of clarity within the articles. Including a flow diagram in all reports on diagnostic accuracy studies would be very helpful in reducing confusion between readers and among reviewers.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
