

The abundance of short proteins in the mammalian proteome
- PMID: 16683031
- PMCID: PMC1449894
- DOI: 10.1371/journal.pgen.0020052
The abundance of short proteins in the mammalian proteome
Abstract
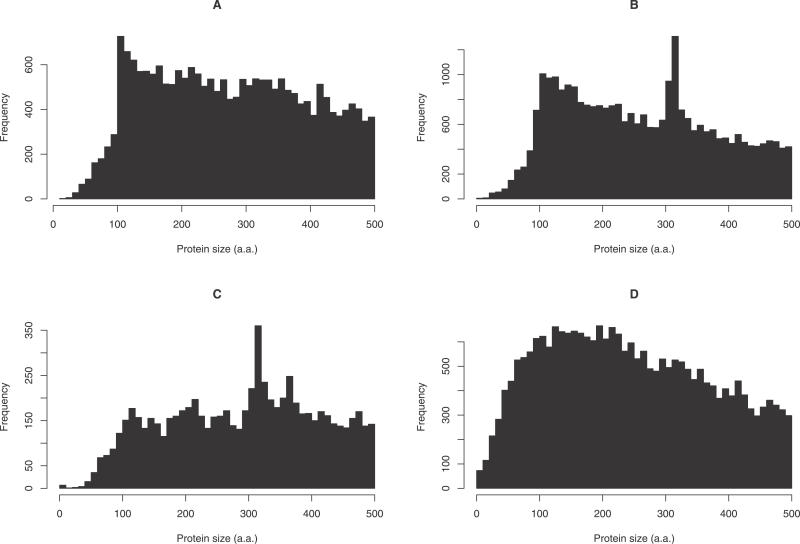
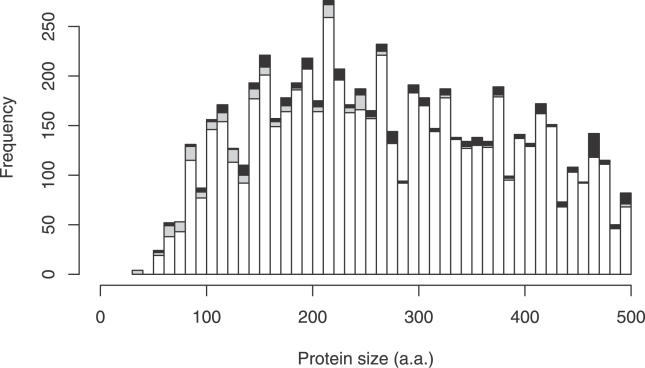
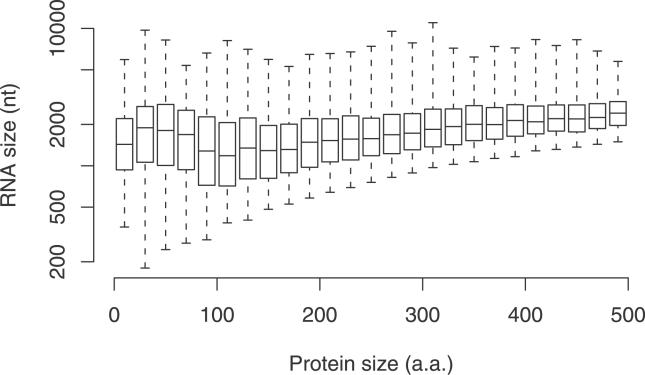
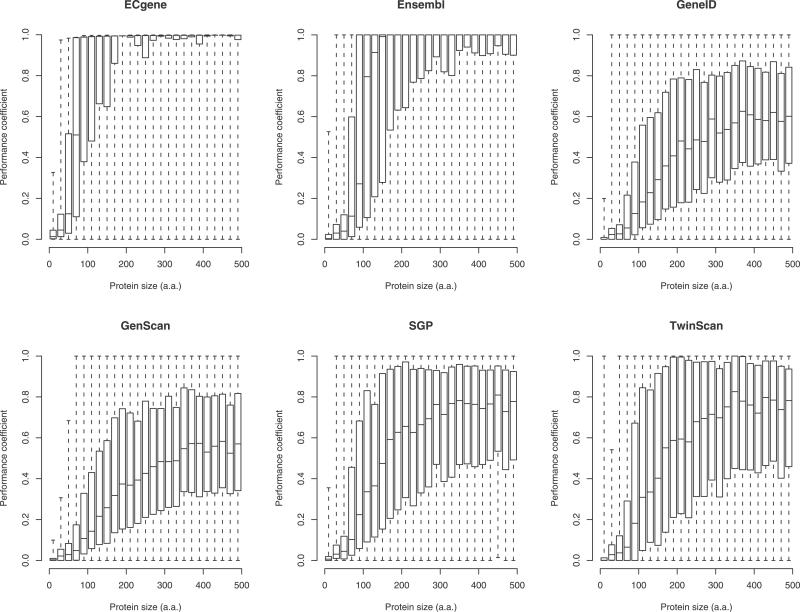
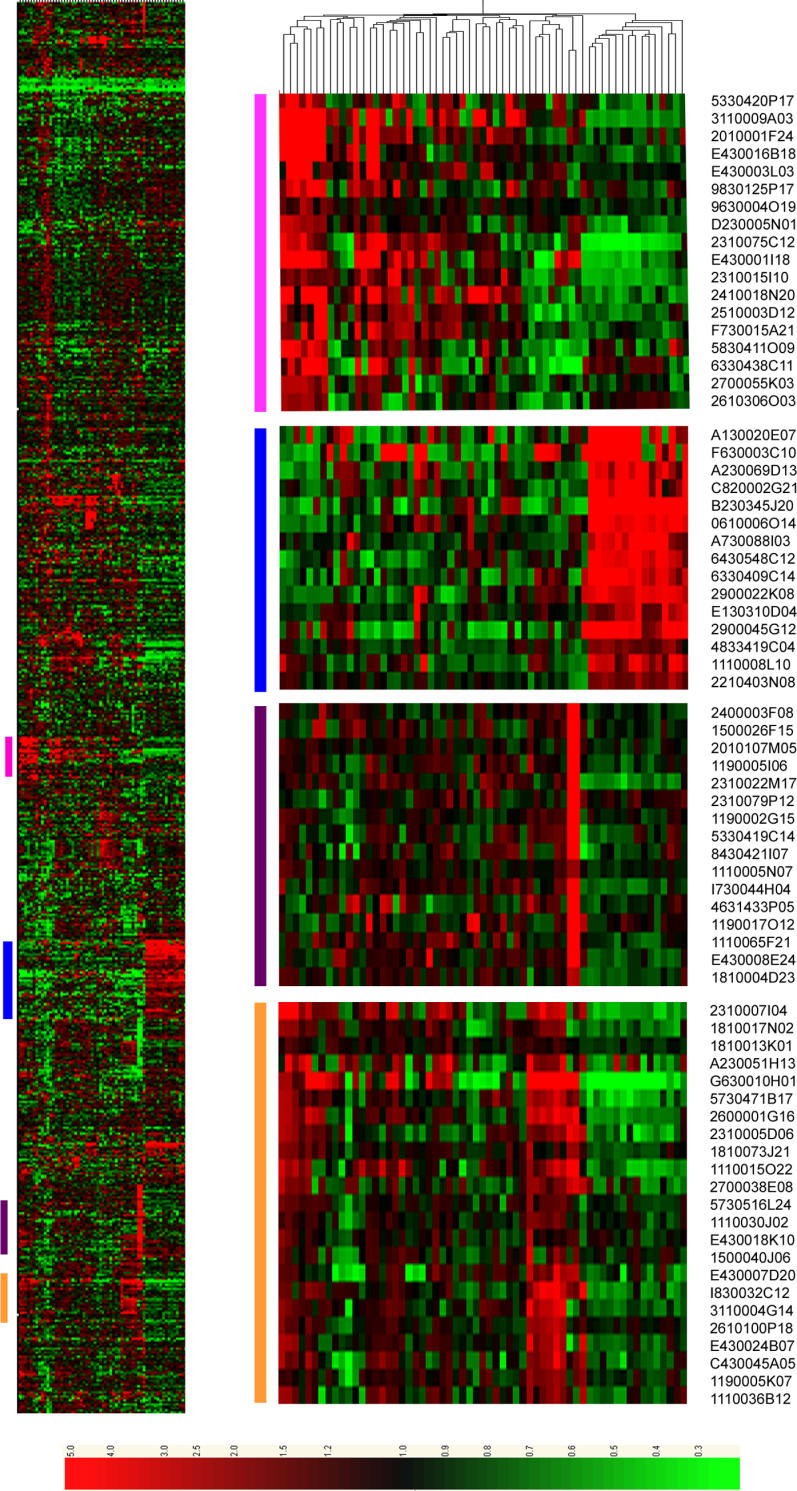
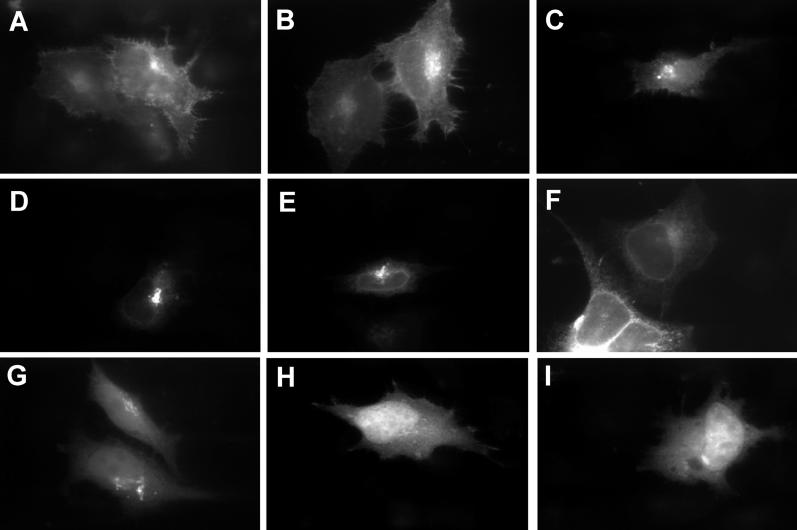
Short proteins play key roles in cell signalling and other processes, but their abundance in the mammalian proteome is unknown. Current catalogues of mammalian proteins exhibit an artefactual discontinuity at a length of 100 aa, so that protein abundance peaks just above this length and falls off sharply below it. To clarify the abundance of short proteins, we identify proteins in the FANTOM collection of mouse cDNAs by analysing synonymous and non-synonymous substitutions with the computer program CRITICA. This analysis confirms that there is no real discontinuity at length 100. Roughly 10% of mouse proteins are shorter than 100 aa, although the majority of these are variants of proteins longer than 100 aa. We identify many novel short proteins, including a "dark matter" subset containing ones that lack detectable homology to other known proteins. Translation assays confirm that some of these novel proteins can be translated and localised to the secretory pathway.
Conflict of interest statement
Competing interests. The authors have declared that no competing interests exist.
Figures

References
-
- Carninci P, Kasukawa T, Katayama S, Gough J, Frith MC, et al. The transcriptional landscape of the mammalian genome. Science. 2005;309:1559–1563. - PubMed
-
- Kersey PJ, Duarte J, Williams A, Karavidopoulou Y, Birney E, et al. The International Protein Index: An integrated database for proteomics experiments. Proteomics. 2004;4:1985–1988. - PubMed
-
- Waterston RH, Lindblad-Toh K, Birney E, Rogers J, Abril JF, et al. Initial sequencing and comparative analysis of the mouse genome. Nature. 2002;420:520–562. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
