

Transcript annotation in FANTOM3: mouse gene catalog based on physical cDNAs
- PMID: 16683036
- PMCID: PMC1449903
- DOI: 10.1371/journal.pgen.0020062
Transcript annotation in FANTOM3: mouse gene catalog based on physical cDNAs
Abstract
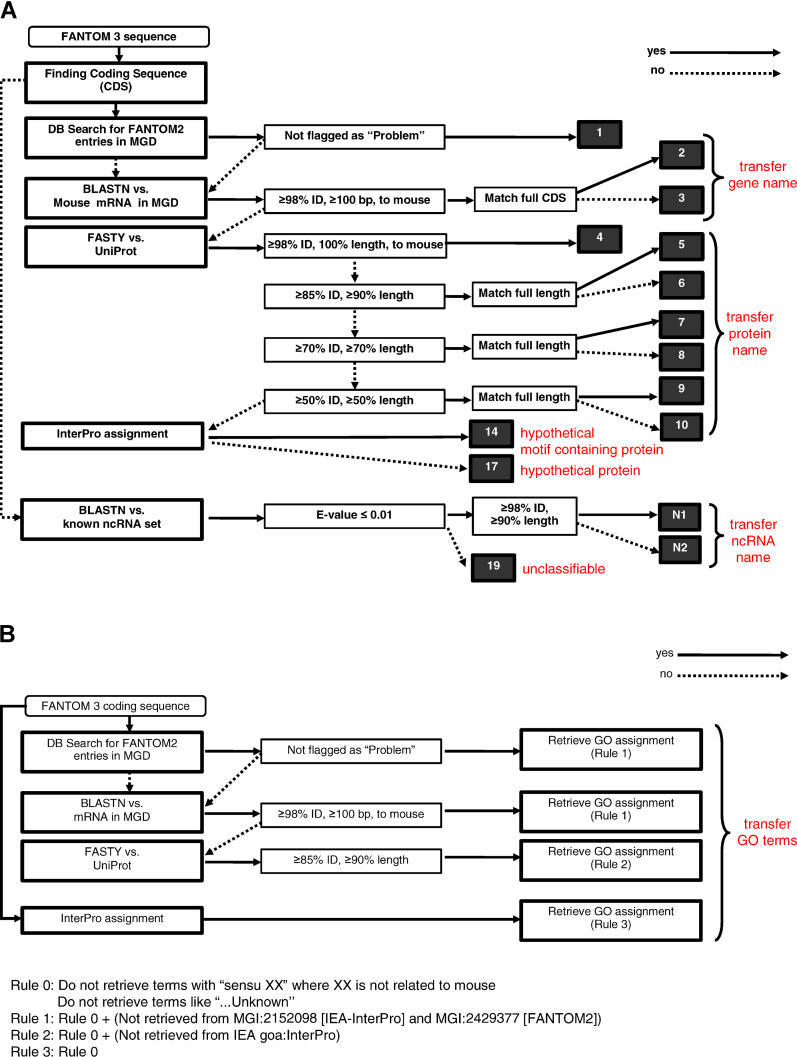
The international FANTOM consortium aims to produce a comprehensive picture of the mammalian transcriptome, based upon an extensive cDNA collection and functional annotation of full-length enriched cDNAs. The previous dataset, FANTOM2, comprised 60,770 full-length enriched cDNAs. Functional annotation revealed that this cDNA dataset contained only about half of the estimated number of mouse protein-coding genes, indicating that a number of cDNAs still remained to be collected and identified. To pursue the complete gene catalog that covers all predicted mouse genes, cloning and sequencing of full-length enriched cDNAs has been continued since FANTOM2. In FANTOM3, 42,031 newly isolated cDNAs were subjected to functional annotation, and the annotation of 4,347 FANTOM2 cDNAs was updated. To accomplish accurate functional annotation, we improved our automated annotation pipeline by introducing new coding sequence prediction programs and developed a Web-based annotation interface for simplifying the annotation procedures to reduce manual annotation errors. Automated coding sequence and function prediction was followed with manual curation and review by expert curators. A total of 102,801 full-length enriched mouse cDNAs were annotated. Out of 102,801 transcripts, 56,722 were functionally annotated as protein coding (including partial or truncated transcripts), providing to our knowledge the greatest current coverage of the mouse proteome by full-length cDNAs. The total number of distinct non-protein-coding transcripts increased to 34,030. The FANTOM3 annotation system, consisting of automated computational prediction, manual curation, and final expert curation, facilitated the comprehensive characterization of the mouse transcriptome, and could be applied to the transcriptomes of other species.
Conflict of interest statement
Competing interests. The authors have declared that no competing interests exist.
Figures
References
-
- Kawai J, Shinagawa A, Shibata K, Yoshino M, Itoh M, et al. Functional annotation of a full-length mouse cDNA collection. Nature. 2001;409:685–690. - PubMed
-
- Okazaki Y, Furuno M, Kasukawa T, Adachi J, Bono H, et al. Analysis of the mouse transcriptome based on functional annotation of 60,770 full-length cDNAs. Nature. 2002;420:563–573. - PubMed
-
- Carninci P, Kasukawa T, Katayama S, Gough J, Frith MC, et al. The transcriptional landscape of the mammalian genome. Science. 2005;309:1559–1563. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
