

Parallel network simulations with NEURON
- PMID: 16732488
- PMCID: PMC2655137
- DOI: 10.1007/s10827-006-7949-5
Parallel network simulations with NEURON
Abstract
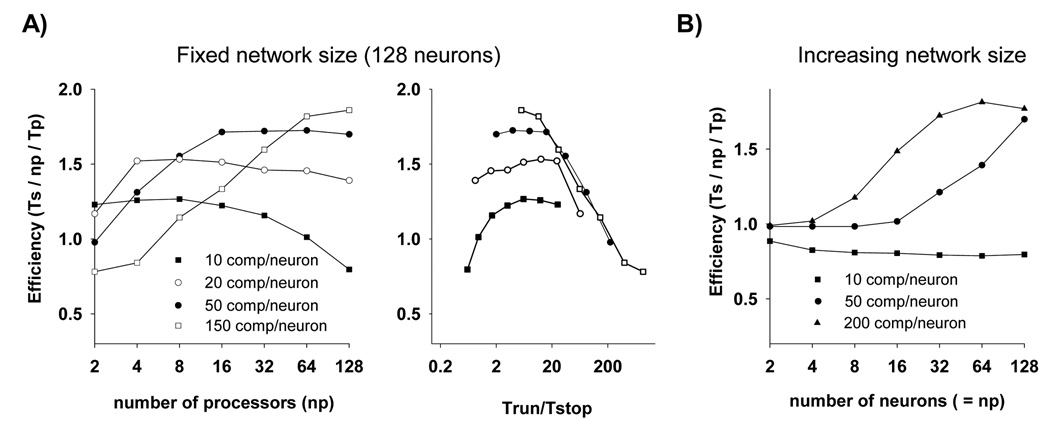
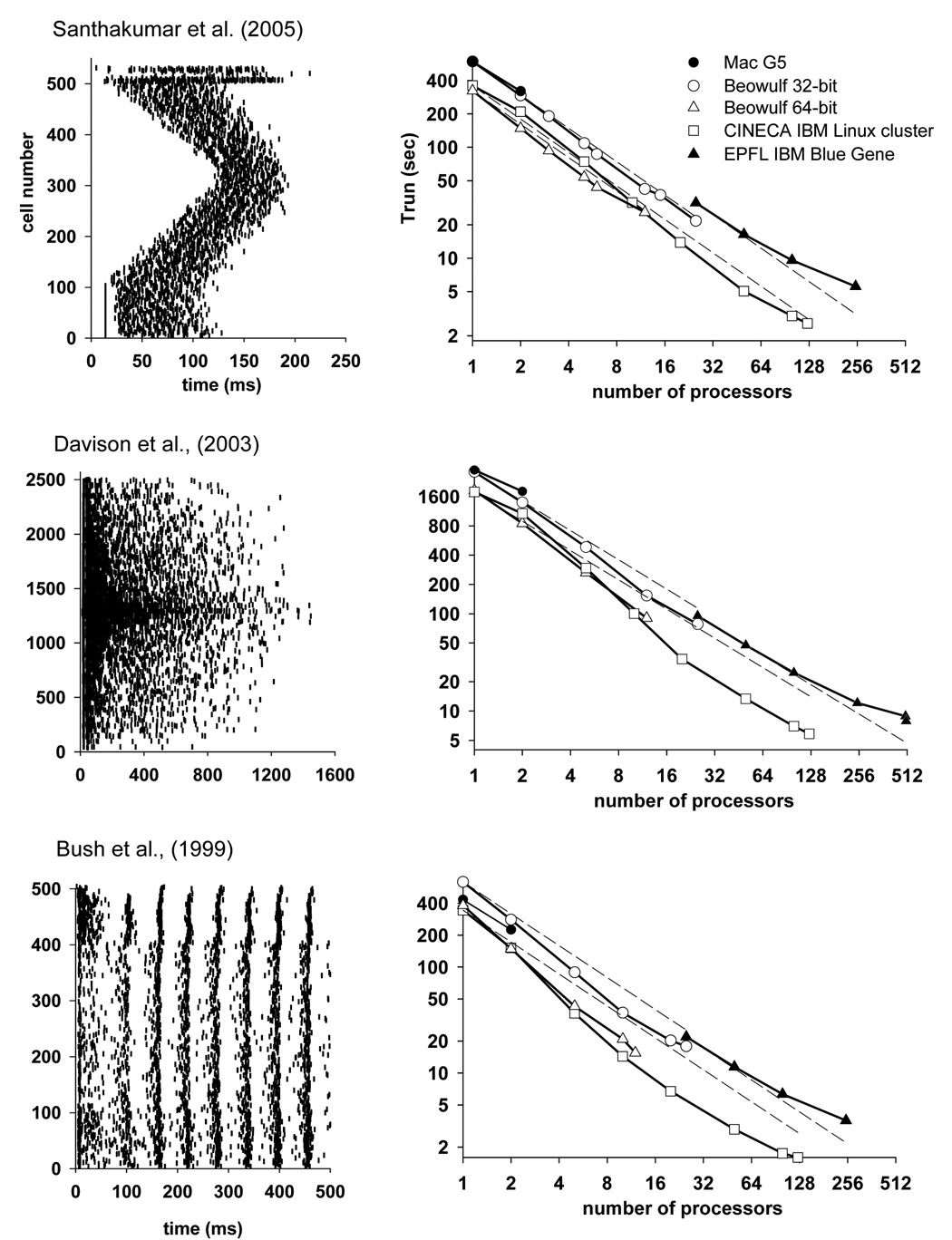
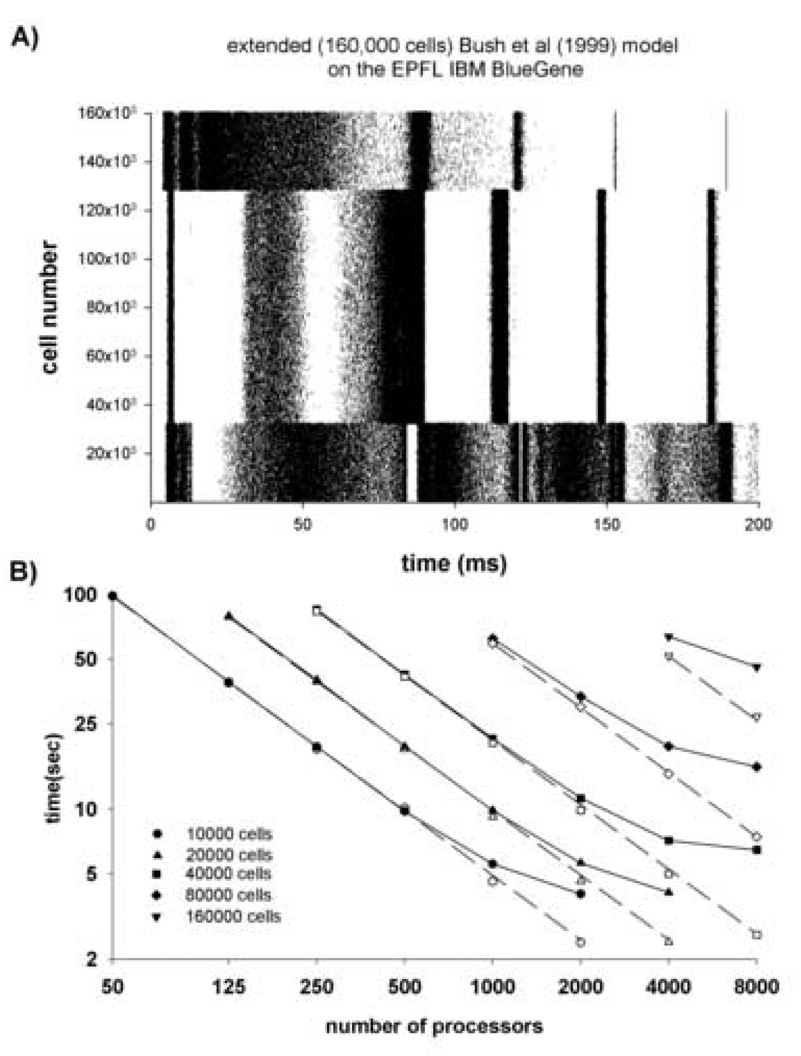
The NEURON simulation environment has been extended to support parallel network simulations. Each processor integrates the equations for its subnet over an interval equal to the minimum (interprocessor) presynaptic spike generation to postsynaptic spike delivery connection delay. The performance of three published network models with very different spike patterns exhibits superlinear speedup on Beowulf clusters and demonstrates that spike communication overhead is often less than the benefit of an increased fraction of the entire problem fitting into high speed cache. On the EPFL IBM Blue Gene, almost linear speedup was obtained up to 100 processors. Increasing one model from 500 to 40,000 realistic cells exhibited almost linear speedup on 2,000 processors, with an integration time of 9.8 seconds and communication time of 1.3 seconds. The potential for speed-ups of several orders of magnitude makes practical the running of large network simulations that could otherwise not be explored.
Figures



References
-
- Almási G, Heidelberger P, Archer CJ, Martorell X, Erway CC, Moreira JE, Steinmacher-Burow B, Zheng Y. Optimization of MPI collective communication on BlueGene/L systems. Proc. 19th annual international conference on Supercomputing; Cambridge MA. 2005. pp. 253–262.
-
- Bush PC, Prince DA, Miller KD. Increased pyramidal excitability and NMDA conductance can explain posttraumatic epileptogenesis without disinhibition a model. J Neurophysiol. 1999;82:1748–1758. - PubMed
-
- Carriero N, Gelernter D. Linda in context. Communications of the ACM. 1989 Apr; 1989.
-
- Delorme A, Thorpe SJ. SpikeNET: an event-driven simulation package for modelling large networks of spiking neurons Network. 2003;14:613–627. - PubMed
-
- Davison AP, Feng J, Brown D. Dendrodendritic inhibition and simulated odor responses in a detailed olfactory bulb network model. J. Neurophysiol. 2003;90:1921–1935. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
