

Integrated biclustering of heterogeneous genome-wide datasets for the inference of global regulatory networks
- PMID: 16749936
- PMCID: PMC1502140
- DOI: 10.1186/1471-2105-7-280
Integrated biclustering of heterogeneous genome-wide datasets for the inference of global regulatory networks
Abstract
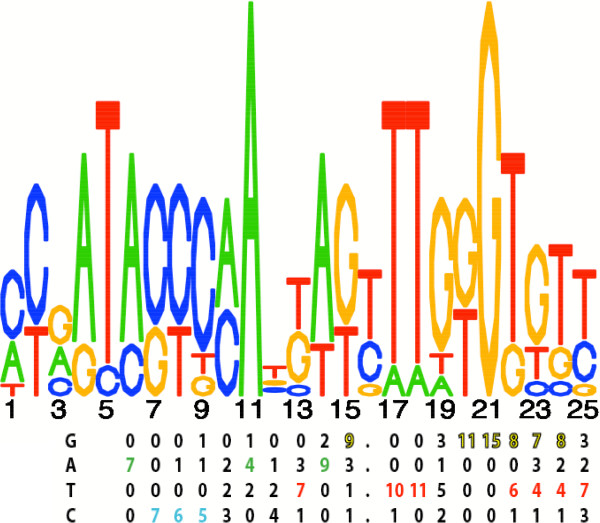
Background: The learning of global genetic regulatory networks from expression data is a severely under-constrained problem that is aided by reducing the dimensionality of the search space by means of clustering genes into putatively co-regulated groups, as opposed to those that are simply co-expressed. Be cause genes may be co-regulated only across a subset of all observed experimental conditions, biclustering (clustering of genes and conditions) is more appropriate than standard clustering. Co-regulated genes are also often functionally (physically, spatially, genetically, and/or evolutionarily) associated, and such a priori known or pre-computed associations can provide support for appropriately grouping genes. One important association is the presence of one or more common cis-regulatory motifs. In organisms where these motifs are not known, their de novo detection, integrated into the clustering algorithm, can help to guide the process towards more biologically parsimonious solutions.
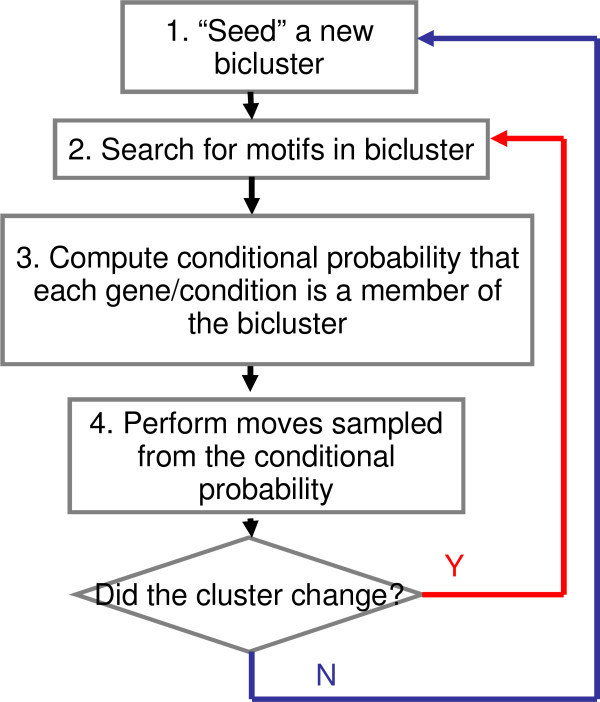
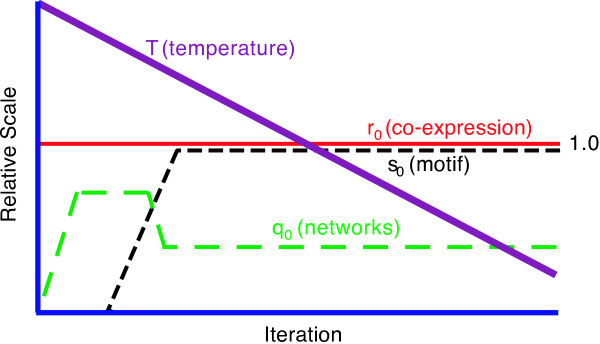
Results: We have developed an algorithm, cMonkey, that detects putative co-regulated gene groupings by integrating the biclustering of gene expression data and various functional associations with the de novo detection of sequence motifs.
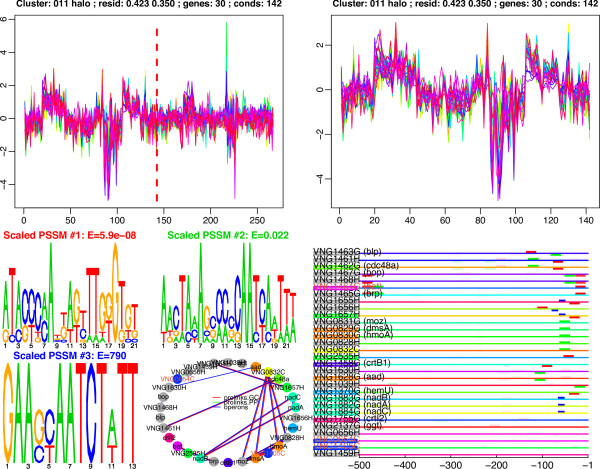
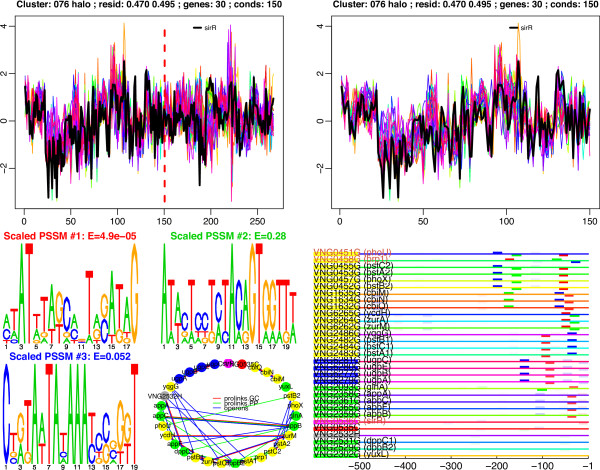
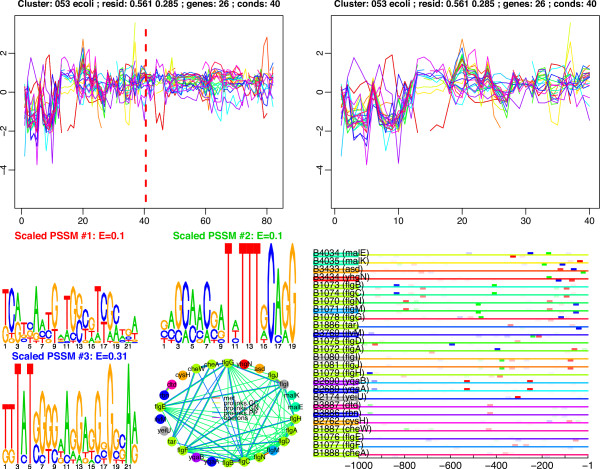
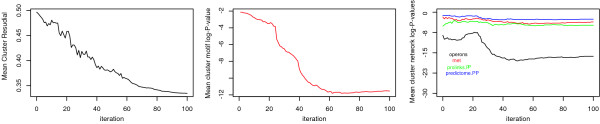
Conclusion: We have applied this procedure to the archaeon Halobacterium NRC-1, as part of our efforts to decipher its regulatory network. In addition, we used cMonkey on public data for three organisms in the other two domains of life: Helicobacter pylori, Saccharomyces cerevisiae, and Escherichia coli. The biclusters detected by cMonkey both recapitulated known biology and enabled novel predictions (some for Halobacterium were subsequently confirmed in the laboratory). For example, it identified the bacteriorhodopsin regulon, assigned additional genes to this regulon with apparently unrelated function, and detected its known promoter motif. We have performed a thorough comparison of cMonkey results against other clustering methods, and find that cMonkey biclusters are more parsimonious with all available evidence for co-regulation.
Figures


References
-
- European bioinformatics institute gene ontology annotations http://www.ebi.ac.uk/GOA/proteomes.html
-
- Kegg genomes web site ftp://ftp.genome.ad.jp/pub/kegg/genomes/
-
- Stanford microarray database http://genome-www5.stanford.edu
-
- CMONKEY web site http://halo.systemsbiology.net/cmonkey
-
- The R project for statistical computing http://www.r-project.org
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
