

A composite score for predicting errors in protein structure models
- PMID: 16751606
- PMCID: PMC2242555
- DOI: 10.1110/ps.062095806
A composite score for predicting errors in protein structure models
Abstract
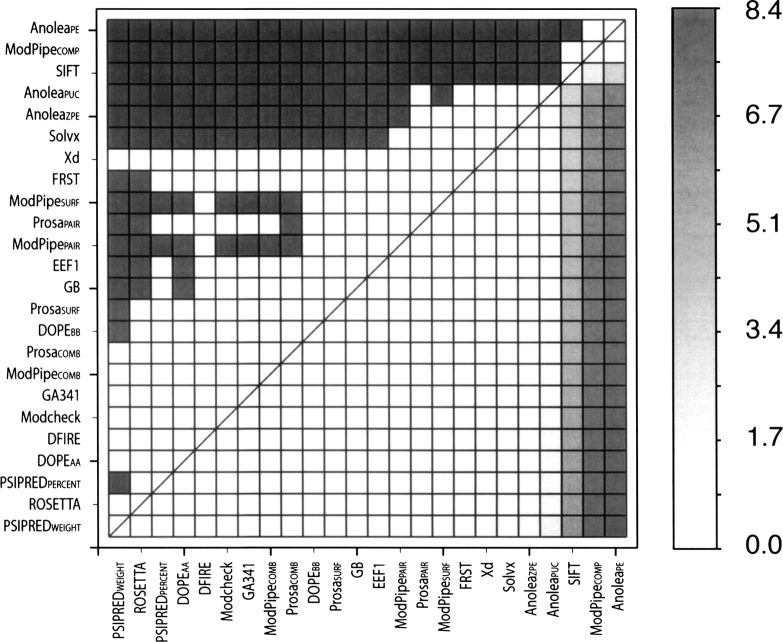
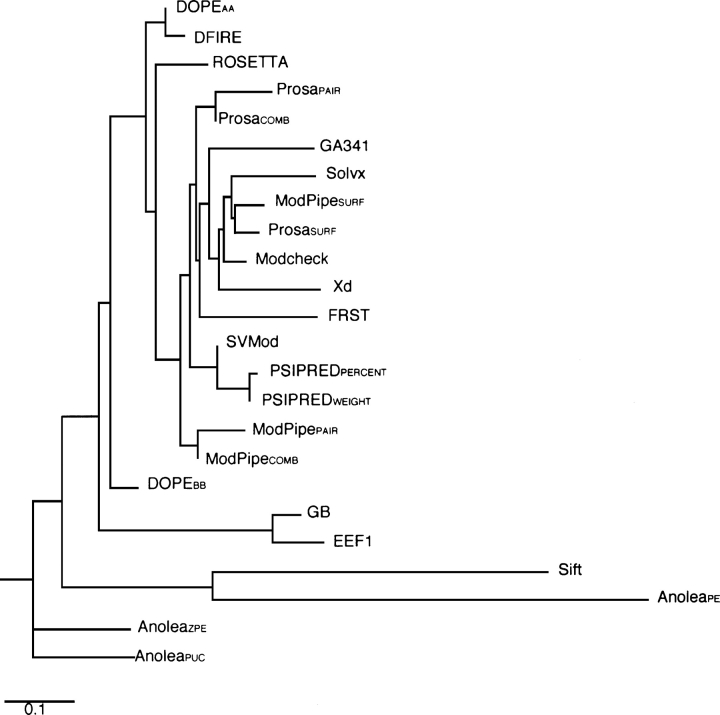
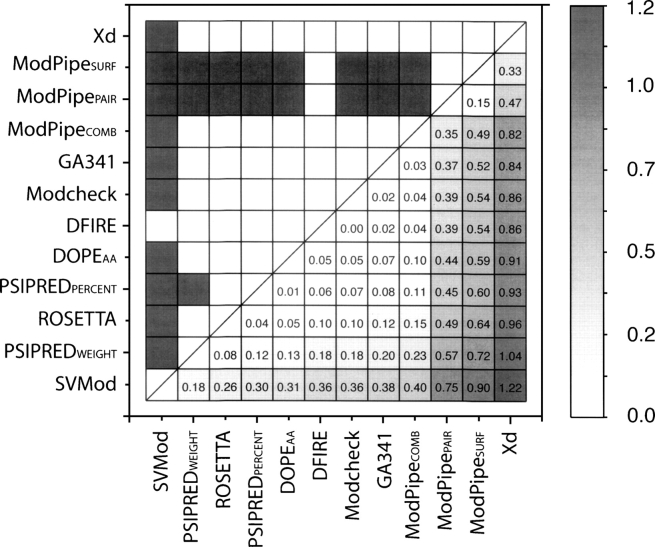
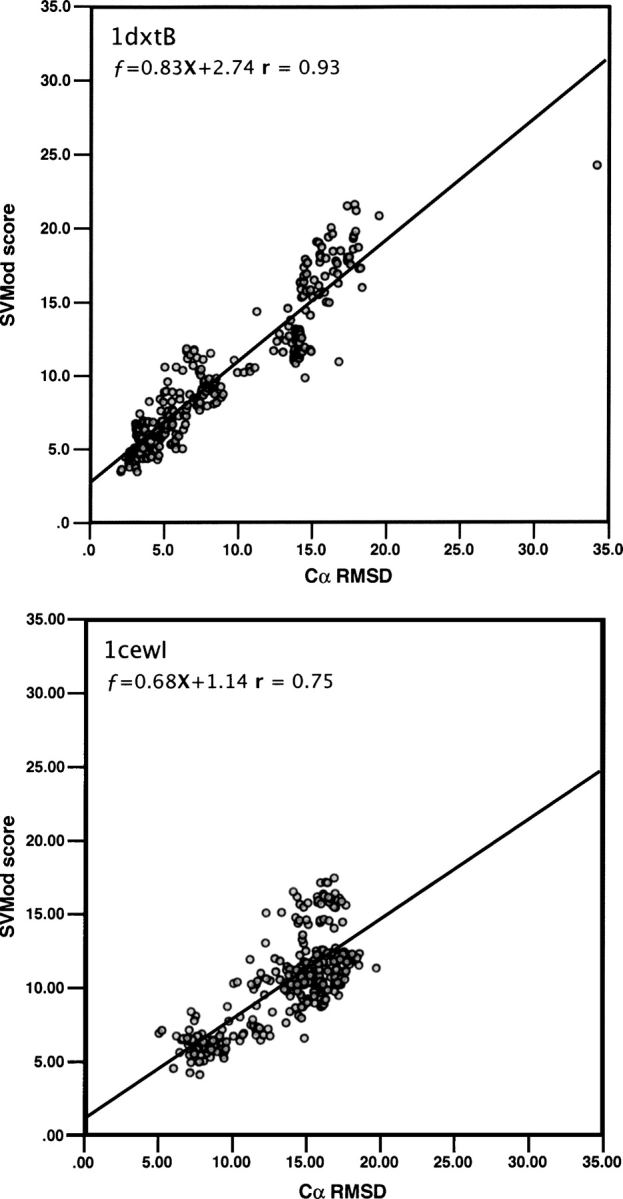
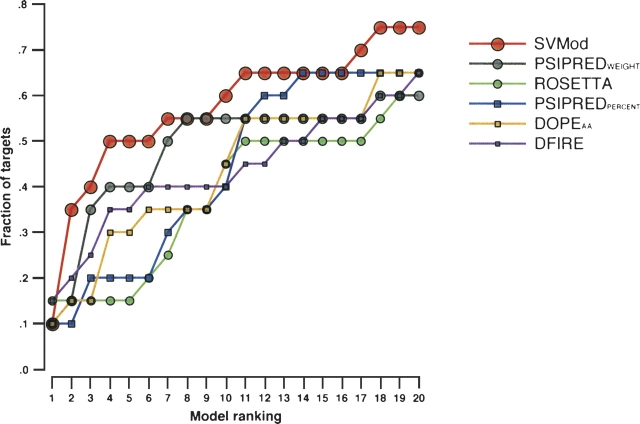
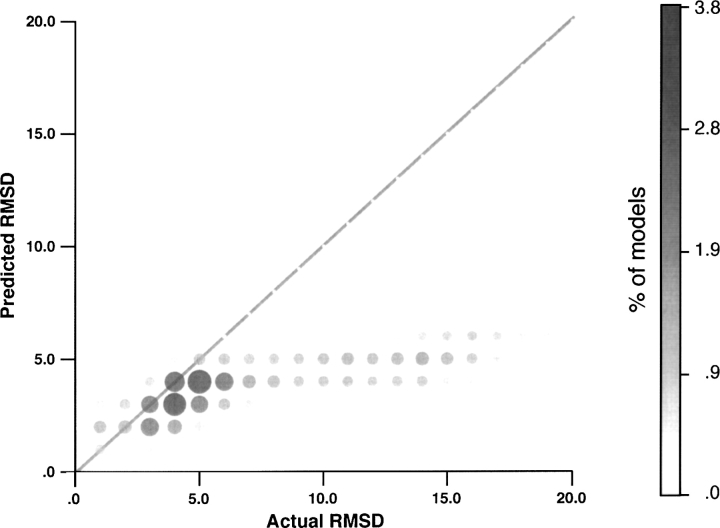
Reliable prediction of model accuracy is an important unsolved problem in protein structure modeling. To address this problem, we studied 24 individual assessment scores, including physics-based energy functions, statistical potentials, and machine learning-based scoring functions. Individual scores were also used to construct approximately 85,000 composite scoring functions using support vector machine (SVM) regression. The scores were tested for their abilities to identify the most native-like models from a set of 6000 comparative models of 20 representative protein structures. Each of the 20 targets was modeled using a template of <30% sequence identity, corresponding to challenging comparative modeling cases. The best SVM score outperformed all individual scores by decreasing the average RMSD difference between the model identified as the best of the set and the model with the lowest RMSD (DeltaRMSD) from 0.63 A to 0.45 A, while having a higher Pearson correlation coefficient to RMSD (r=0.87) than any other tested score. The most accurate score is based on a combination of the DOPE non-hydrogen atom statistical potential; surface, contact, and combined statistical potentials from MODPIPE; and two PSIPRED/DSSP scores. It was implemented in the SVMod program, which can now be applied to select the final model in various modeling problems, including fold assignment, target-template alignment, and loop modeling.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
