

The Escherichia coli proteome: past, present, and future prospects
- PMID: 16760308
- PMCID: PMC1489533
- DOI: 10.1128/MMBR.00036-05
The Escherichia coli proteome: past, present, and future prospects
Abstract
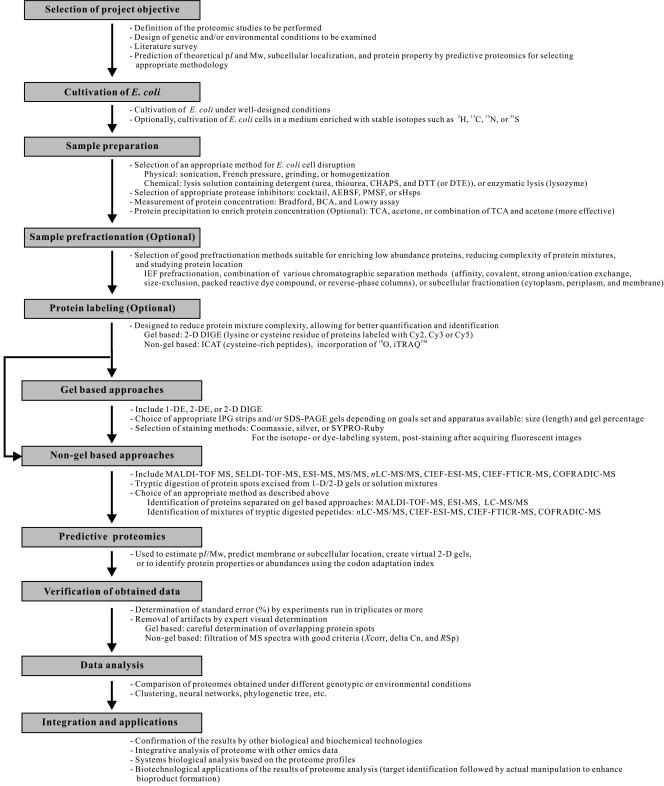
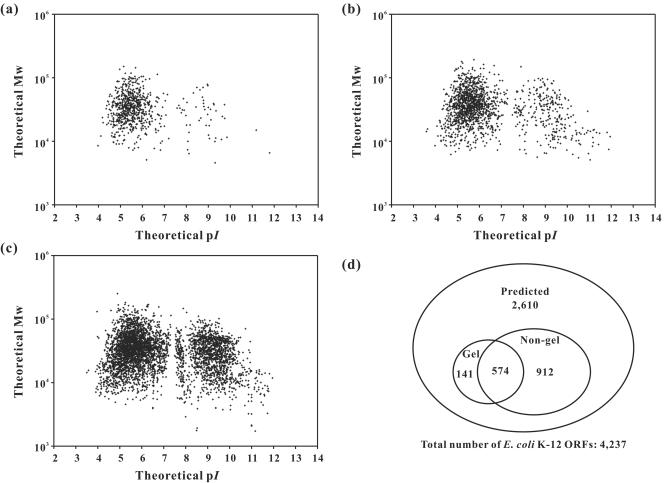
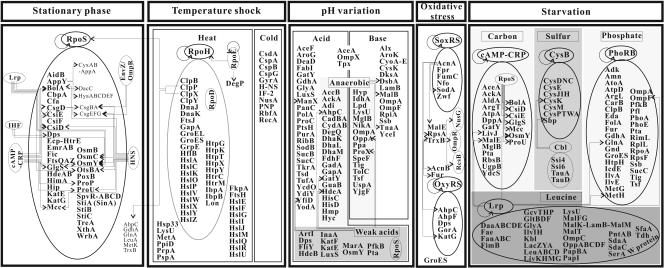
Proteomics has emerged as an indispensable methodology for large-scale protein analysis in functional genomics. The Escherichia coli proteome has been extensively studied and is well defined in terms of biochemical, biological, and biotechnological data. Even before the entire E. coli proteome was fully elucidated, the largest available data set had been integrated to decipher regulatory circuits and metabolic pathways, providing valuable insights into global cellular physiology and the development of metabolic and cellular engineering strategies. With the recent advent of advanced proteomic technologies, the E. coli proteome has been used for the validation of new technologies and methodologies such as sample prefractionation, protein enrichment, two-dimensional gel electrophoresis, protein detection, mass spectrometry (MS), combinatorial assays with n-dimensional chromatographies and MS, and image analysis software. These important technologies will not only provide a great amount of additional information on the E. coli proteome but also synergistically contribute to other proteomic studies. Here, we review the past development and current status of E. coli proteome research in terms of its biological, biotechnological, and methodological significance and suggest future prospects.
Figures

References
-
- Aggarwal, K., L. H. Choe, and K. H. Lee. 2005. Quantitative analysis of protein expression using amine-specific isobaric tags in Escherichia coli cells expressing rhsA elements. Proteomics 5:2297-2308. - PubMed
-
- Aldor, I. S., D. C. Krawitz, W. Forrest, C. Chen, J. C. Nishihara, J. C. Joly, and K. M. Champion. 2005. Proteomic profiling of recombinant Escherichia coli in high-cell-density fermentations for improved production of an antibody fragment biopharmaceutical. Appl. Environ. Microbiol. 71:1717-1728. - PMC - PubMed
-
- Almirón, M., A. J. Link, D. Furlong, and R. Kolter. 1992. A novel DNA-binding protein with regulatory and protective roles in starved Escherichia coli. Genes Dev. 6:2646-2654. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
